Convolutional Neural Network
Lecture 5에서 못다룬 ResNet에 대해 알아본다.
ResNet

ResNet은 152개의 layer를 쌓아 처음으로 사람보다 뛰어난 성능을 보여주었다.
AlexNet은 8 layer, GoogleNet은 22 layer를 쌓아올림으로써 성능 향상을 이루었다. 더 깊은 network를 쌓아올릴수록 더 좋은 성능을 이루어질거라고 생각했다. 하지만, 일정 깊이 이후, 성능 하락이 있는 것을 확인하였다. vanishing gradient를 해결하며 deep neural network에 대해 성능 향상을 이룬 "Deep Residual Learning for Image Recognition" 논문 (ResNet)이 등장한다.
network가 깊어질수록 backpropagation 과정에서 gradient가 너무 작아지는 현상이 생긴다.
가중치를 업데이트할 때, "가중치(new) = 가중치(old) - gradient" 과정을 거치는데 gradient가 0으로 작아지다보니 가중치가 업데이트가 안되서 학습이 안되는 현상이다.
gradient vanishing 문제를 해결하기 위한 핵심 아이디어는 residual connection이다. 전통적인 neural network layer은 y = F(x)와 같으며 이를 y = F(x) + x로 변경함으로써 residual block으로 만들어주었다.
이를 왜 residual이라고 부를까? resiudal은 나머지라는 뜻인데 위 식을 F(x) = y - x로 바꿀 수 있는데 결국 output과 input 간의 차이(나머지)를 학습한다고 생각할 수 있다.
왜 residual connection이 gradient vanishing을 해결할 수 있을까? 특정 layer가 안좋게 학습이 되더라도 이 network는 gradient를 계속해서 뒤로 전달해 줄 수 있다. chain rule를 생각해보면 계속 깊어지는 상황에서 엄청 작은 값이 중간에 있어서 엄청 작은 값을 곱함으로써 작은 값으로 되는데 F(x) + x를 미분하면 x가 1이 되서 1.xxx가 됨으로써 그대로 gradient를 흐를 수 있게 해주었다.
Full ResNet architecutre:
- Add an additional conv layer at the beginning (stem) => GoogleNet
- Stack residual blocks, each containing two 3x3 conv layers => GoogleNet & VGG
- Doubl the # of filters when reducing the spatial dimension by half
- Insert a global average pooling (GAP) layer after the last conv layer => GoogleNet
Variations:
- ResNet-18 and ResNet-34
- Each using a different number of conv layers
ResNet-50부터는 computational cost를 낮추기 위해, bottleneck residual block을 사용한다.
기존 residual block의 FLOPs는 (HxWx4C) x (3x3x4C) = 144HWC^2에서 두 개로 총 288HWC^2이다.
Bottleneck residual block의 FLOPs는 (HxWxC) x (1x1x4C) = 4HWC^2 + (HxWxC) x (3x3xC) = 9HWC^2 + (HxWx4C) x (1x1xC) = 4HWC^2 로 총 17HWC^2이다.
2016년에 발표한 Shao et al. 모델은 구조가 살짝 다른 여러가지 ResNet 모델들을 사용하여 결과를 합쳐 더 좋은 결과를 이루었다. 즉, 앙상블을 한 것이다.
SENet은 ResNet보다 1.3% 성능 향상을 가져왔다.
Squeeze-and-Excitation Networks (SENet)
"feature recalibration" module을 사용해서 feature map을 reweight를 하여 학습한다. global average pooling을 통해 1x1xC로 squeeze하고 fully connected layer를 통해 각 채널마다 얼마나 weight를 다르게 할지 excitation을 한다. 채널마다 weight를 다르게 주어 성능 향상을 가져온 것이다.
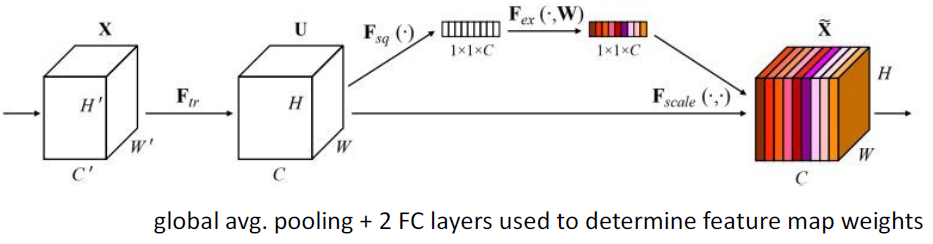
지금까지 배운 것을 정리해보면 다음과 같다.
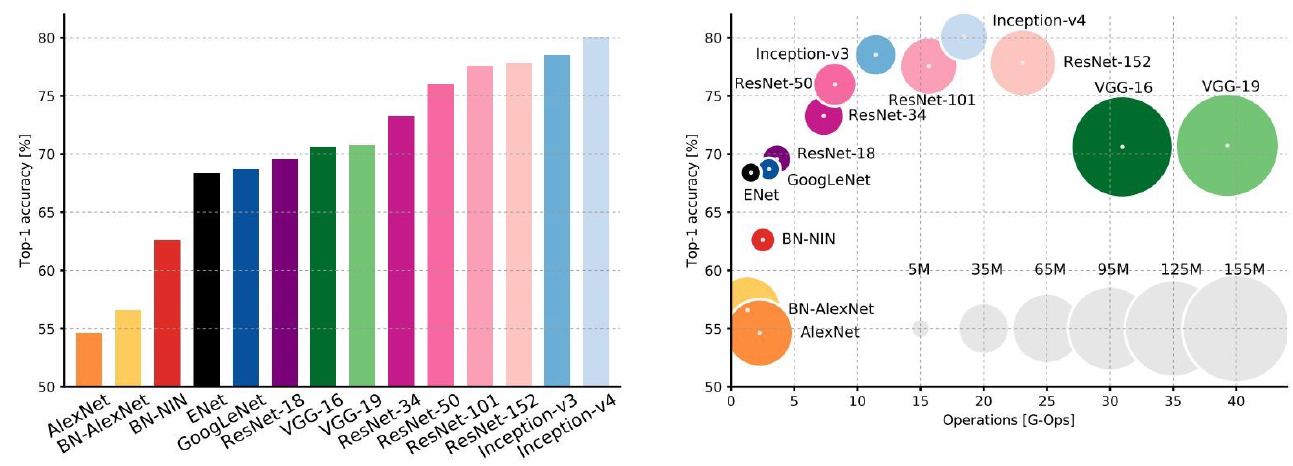
- AlexNet -> GoogleNet -> VGG -> ResNet 순으로 성능 향상 달성
- 계산량을 낮추면서도 성능 향상을 가져옴
- AlexNet은 smaller compute, still memory heavy, lower acuracy
- VGG는 most parameters, most operations
- GooleNet은 most efficient
- ResNet은 moderate efficiency, highest accuracy
Training Neural Network
본 강의 학습 목표는 다음과 같다.
- Dataset splitting
dataset은 train/validation/test 세 가지 subset으로 분할한다. 보통 6:2:2 혹은 7:1.5:1.5 비율로 나눈다. 보지못한 데이터에 대해 잘 수행할 수 있도록 즉, 일반화 성능을 올리기 위해 모델 신뢰성을 올리기 위해 데이터셋을 분할한다.
Train set: 모델을 학습시키기 위한 데이터셋
Validation set: training set에서 여러 모델을 학습시키며 validation set에서 가장 높은 성능을 보이는 네트워크로 설정. 즉, 검증 데이터셋
Test set: 아예 건드리지 않고 보지 않은 최종 평가 데이터셋.
K-Folds cross-validation
데이터를 k개로 분할하고 하나는 validation, 나머지를 training set으로 사용한다.
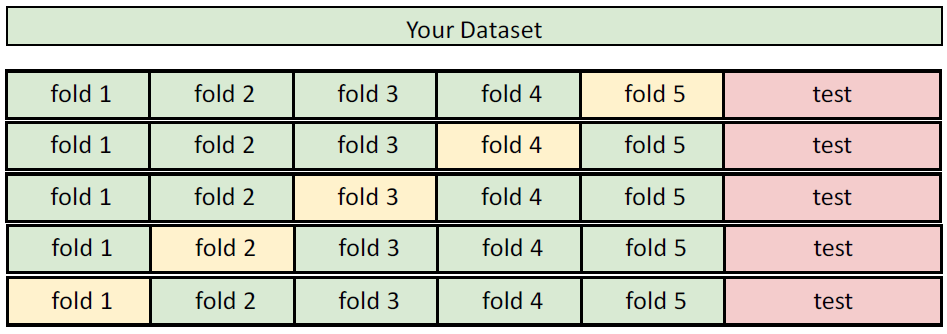
cross validation는 작은 데이터셋일 때 사용하는 것이 적합하다. 작은 데이터셋일 경우, 좀 더 다양한 validation set을 확보하고자 k-folds를 사용하면 일반화 성능 향상에 도움이 된다. (사실, 요즘은 대부분의 경우 데이터셋이 많다.)
'Lectures > 딥러닝영상인식1' 카테고리의 다른 글
| [Lecture 8] Training Neural Network (0) | 2024.12.16 |
|---|---|
| [Lecture 7] Training Neural Network (0) | 2024.12.16 |
| [Lecture 5] Convolutional Neural Network (CNN) (1) | 2024.10.21 |
| [Lecture 4] Convolution (3) | 2024.10.21 |
| [Lecture 3] Backpropagation (2) | 2024.10.20 |



