본 강의 학습목표는 다음과 같다.
- LeNet
- ILSVR Challenge - 2012: Alexnet, 2013: ZFNet, 2014: VGGNet, 2015: ResNet
LeNet
LeNet is not the very first neural network, it is widely considered one of the first successul applications of convolutional layers. LeNet is developed for handwritten digit recognition on the MNIST dataset.
LeNet은 "Gradient-based learning applied to document recognition" 논문에서 1998년에 소개되었다. LeNet의 구조는 다음과 같다.

MNIST dataset은 28x28x1 흑백이미지가 70,000개 있으며 10개의 클래스(0~9)로 구성되어 있다. MNIST는 다음과 같다.
MNIST 데이터셋을 LeNet에 입력한 예시는 다음과 같다.
MNIST 클래스는 10개이므로 마지막은 10개로 설정하고 activation function은 추가하지 않는다(non-linearity를 이미 만들었으며 마지막에는 linear하게 분류한다).
ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
엄청 큰 이미지를 가지고 classification하는 대회이다.
ICVRC : An annual competition evaluating large-scale image classification algorithms
- Dataset
ImageNet : 14 million labeled 256x256 RGB images of 1000 classes
- Impact
First held in 2010, the ILSVRC has been a driving force behind advancements in computer vision
In 2012, the deep learning model AlexNet won the competition, outperforming traditional techniques (딥러닝의 시작)
AlexNet
AlexNet is conceptually an extension of LeNet but is much deeper and designed to handle larger datasets and higher-resolution images.
AlexNet은 "ImageNet Classification with Deep Convolutional Neural Networks" 논문에서 소개되었으며 2012년에 NeurIPS 학회에 발표되었다.(인용수가 어마무시하다. 글 작성 시점 기준으로 134,518회이다.)
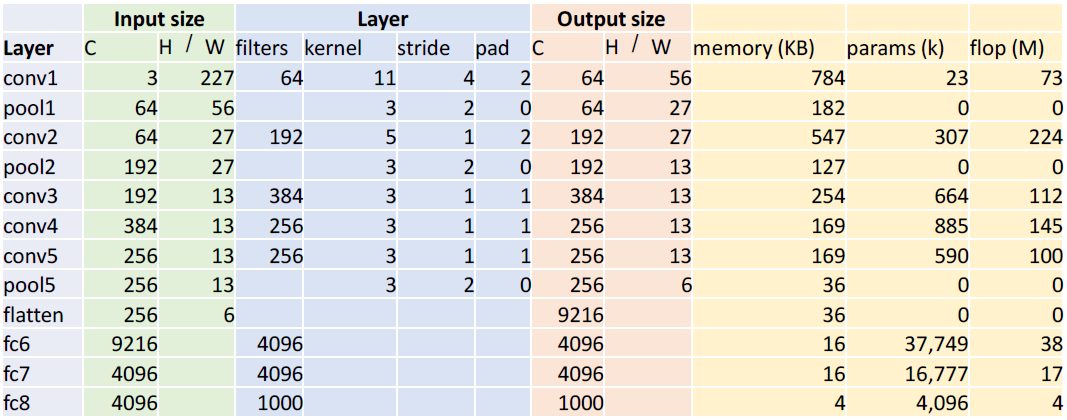
위 그림에서 Input size와 Layer가 주어지면 Output size는 이제 구할 수 있을거라 생각하고 메모리를 계산하는 법을 간략하게 설명한다. output size는 64 x 56 x 56 = 200,704 이다. 보통 컴퓨터는 실수를 저장하기 위해 32-bit를 사용하는데 1 byte = 8-bit이므로 4 byte를 필요로한다. 이걸 KB로 환산하기 위해 1024로 나눈다. 즉, 200,704 x 4 / 1024 = 784 KB이다. KB는 MB, GB와 같은 단위이다.
weight size는 64 x 3 x 11 x 11 이다. bias는 총 64개를 가지고 있으므로 전체 가중치 수는 64x3x11x11+64 = 23,296이다.
계산량(multiply+add operation)은 output element의 수 x filter size 이다. 따라서, (64 x 56 x 56) x (3 x 11 x 11 + 1) = 200,704 x 364 = 73,056,256 이다.
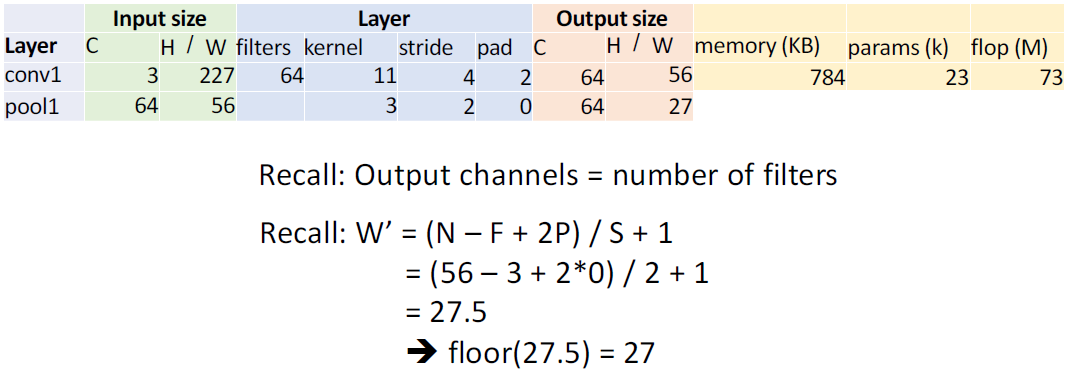
pooling 행을 보면 input size는 64 x 56 x 56이 되며 layer가 저렇게 될 때, 27.5가 나오는데 버림연산으로 27로 계산한다. 저번 강의에서는 안된다고 했으나 이런걸 지원해주는 라이브러리가 있으며 그렇게 추천하지는 않는다.
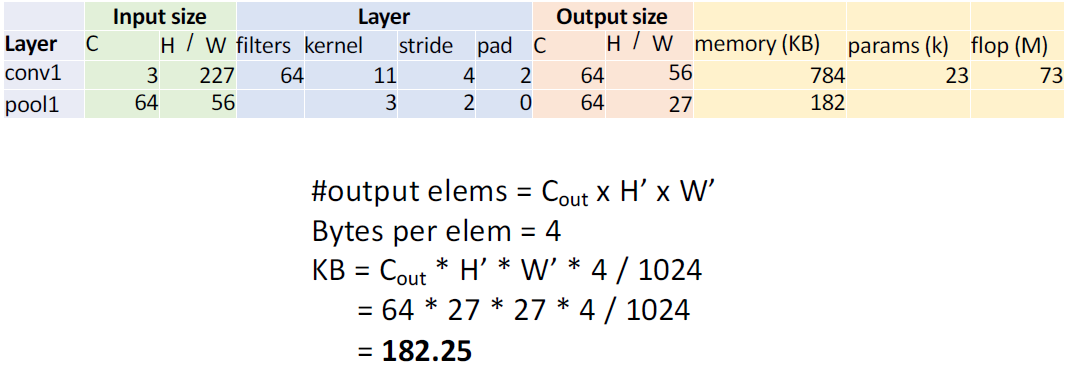
계산 메모리(KB)는 output size에 4 byte를 곱하고 1024로 나눠주면된다.
풀링에는 파라미터가 존재하지 않으므로 0이다.

계산량은 output size와 kernel size를 곱하면 되므로 419,904가 나온다.
최종 결과는 다음과 같다.
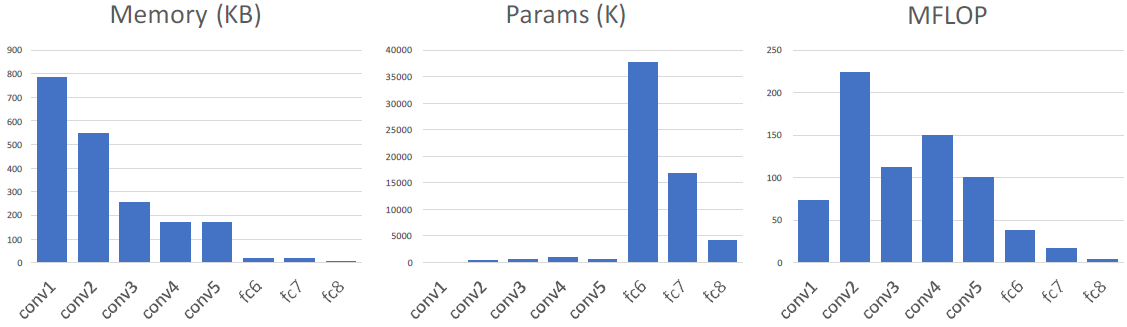
Most of the memory usage is in the early convolution layers.
Nearly all parameters are in the fully-connected layers.
Most floating-point ops occur in the convolution layers.
ZFNet: A Bigger AlexNet
2013년에 소개된 ZFNet에 대해 알아본다. 이는 ILSVRC에서 AlexNet보다 5% 정도 성능 향상을 보였다.
AlexNet에서 살짝 바꾼건데 대표적으로 바꾼 부분은 다음과 같다.
conv1: change from (11x11 stride 4) to (7x7 stride 2)
conv3,4,5: instead of 384, 384, 256 filters use 512, 1024, 512
VGGNet
2014년에 소개된 VGGNet에 대해 알아본다. AlexNet, ZFNet에 대해 8개 layer만 쌓았는데 VGGNet은 19개 layer를 쌓는다. 그 전까지 여러가지 시행착오를 겪다보니 VGGNet에서는 이러한 Disgn rule을 따르면 좋다라는 것을 제안한다.
Design rules
1. All conv are 3x3 stride 1 pad 1
2. All max pool are 2x2 stride 2
3. After pool, double #channels
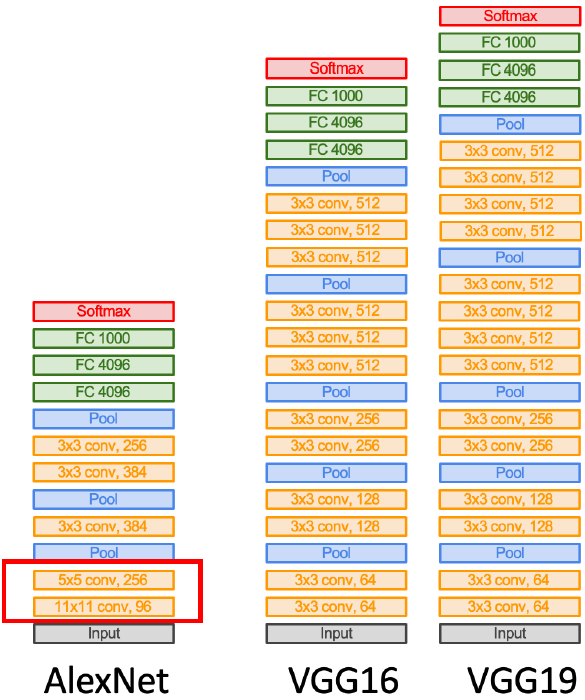
Q : Why use smaller filters? (3x3 conv)
3x3 conv을 3번 쌓아서 receptive field를 계산하면 7x7 conv 1번하는거랑 3x3 3번 하는거랑 receptive field 관점에서 같다. 하지만 3x3 conv을 3번 쌓으면 더 깊게 쌓을 수 있고 non-linearity를 더 추가할 수 있으며 파라미터를 덜 쓴다.
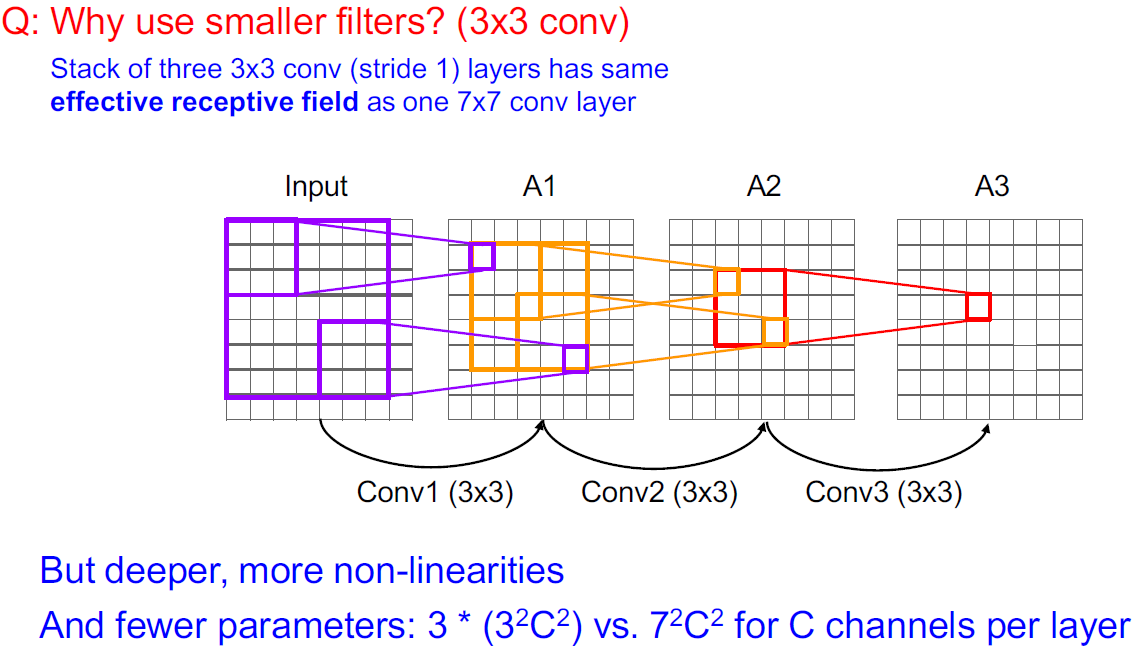
VGG16에 대한 세부 사항은 다음과 같다.

VGGNet은 AlexNet에 비해 메모리를 훨씬 더 사용하고 파라미터도 더 사용하고 계산량도 훨씬 많긴하지만 성능이 더 좋아졌다.
GoogLeNet
2014년 동일한 년도에 소개된 GoogLeNet에 대해 알아본다.
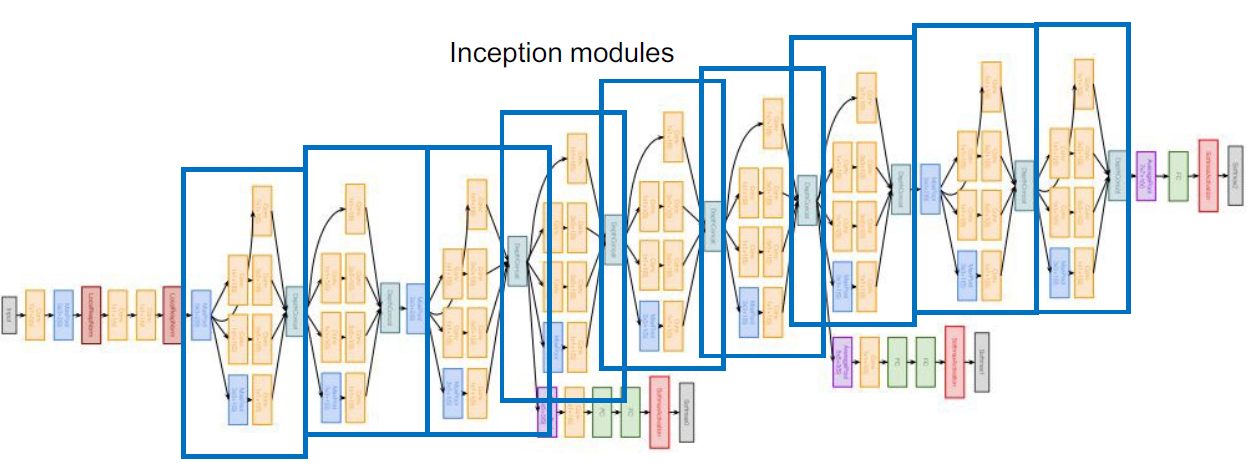
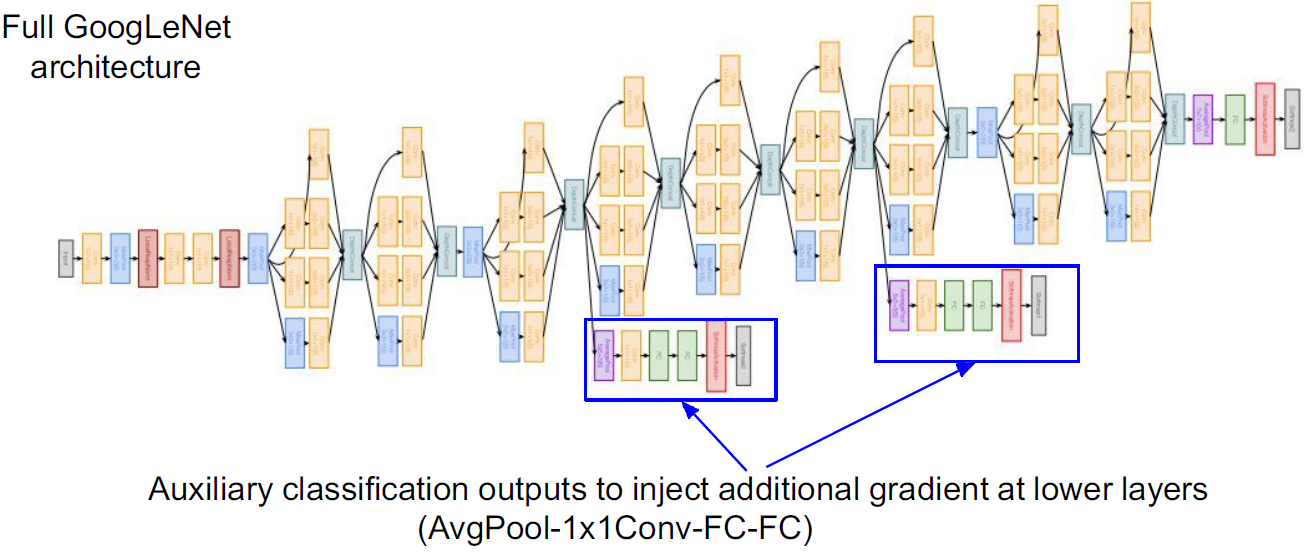
conv-pool-conv-conv-pool을 통해 이미지를 처리하고 inception module을 만들어 이러한 모듈을 단순하게 쌓아 만들었다. 그리고 맨 마지막에 linear classifier를 달아주는건 똑같은데 H x W x C 를 통해 fc layer를 거치는데 이렇게 안하고 average pooling을 통해 1 x 1 x C로 변환해준다.
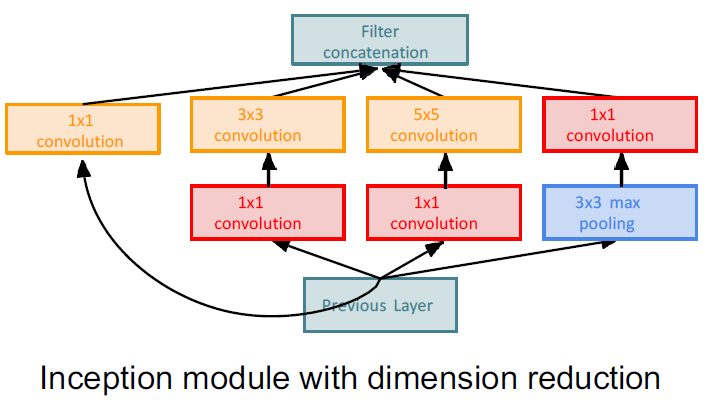
이전 layer가 있고 그 다음 conv을 통해 다음 layer를 통과할텐데 이전 모델까지는 conv 하나만 선택해 사용했다. 3x3 or 5x5 or 3x3 max pooling 등.. 그래서 여기서 등장하는게 모두 사용한 결과를 합쳐주는 방법이다. 다양한 receptive field가 생성되며 여러 정보가 합쳐진다. 하지만, 이렇게 되면 계산량이 너무 많아진다.
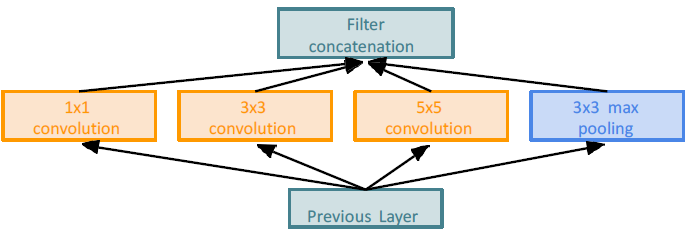
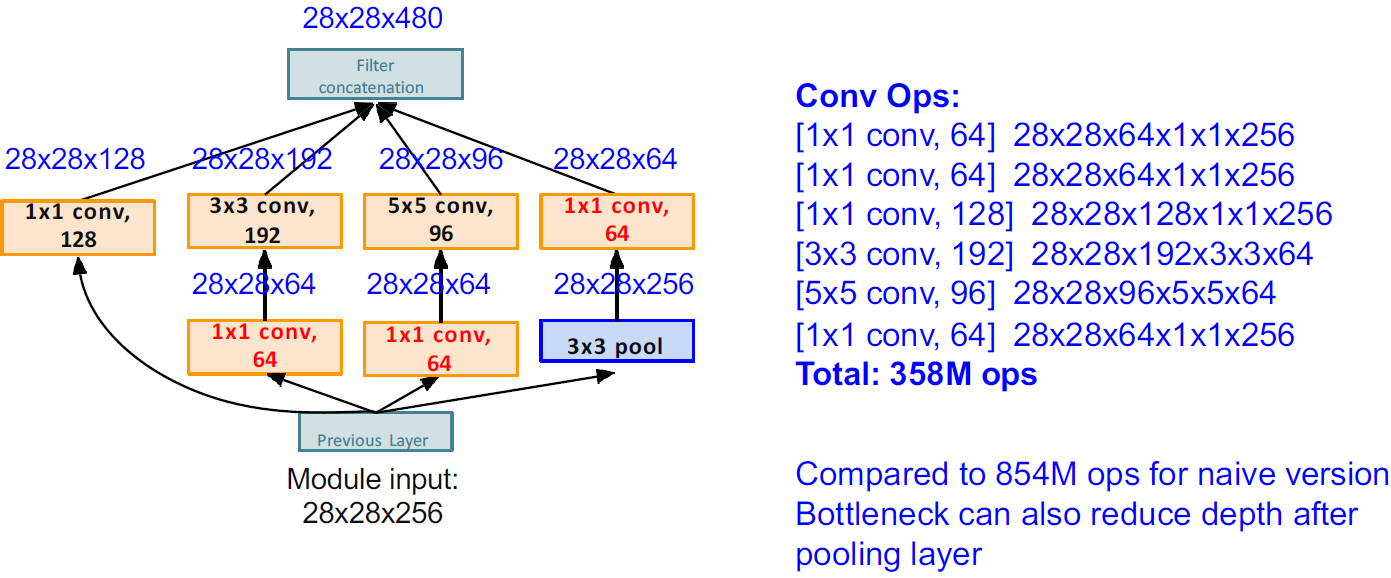
계산량이 너무 많아지다보니 1x1 conv을 넣는다.
계산량은 다음과 같다.
앞서 말한것처럼 last convolutional layer 후에 global average pooling layer를 통해 각 feature map의 평균을 사용한다. 이는 FC layer의 파라미터 수, 계산량, 메모리를 줄였다.
그리고 마지막으로 중간 중간 classifier를 넣어줘서 loss를 통해 학습시켰다.
다음 강의에서는 ResNet에 대해 학습한다.
'Lectures > 딥러닝영상인식1' 카테고리의 다른 글
| [Lecture 7] Training Neural Network (0) | 2024.12.16 |
|---|---|
| [Lecture 6] Convolutional Neural Network & Training Neural Network (0) | 2024.12.16 |
| [Lecture 4] Convolution (3) | 2024.10.21 |
| [Lecture 3] Backpropagation (2) | 2024.10.20 |
| [Lecture 2] Neural Network and Loss Function (0) | 2024.09.24 |



