본 강의 학습 목표는 다음과 같다.
- Dataset splitting
- Optimizer
- Learning rate / scheduling
- Loss curve and Overfitting
- Activation functions
- Dropout
- Data augmentation
Dataset splitting
기존 데이터셋을 train / validation / test set으로 분할한다.
그러면 train set으로 어떻게 모델을 학습시킬까?
전에 배웠던, backpropagation algorithm으로 모델을 학습한다.
단순하게 이미지 한장만으로 학습을 시키지 않는다. train set이 6,000장이 있다고 하면 하나의 이미지로 학습을 할 경우, 전체 데이터셋 분포를 반영하지 않고 불안정한 수렴으로 이끌 수 있다. 그러면 6,000장을 한 번에 학습하면 전체 이미지 분포를 반영하기 때문에 좋지 않을까 생각할 수 있는데 하지만 이는 계산량이 너무 크고 한정된 자원으로 처리가 안될 수 있다.
따라서, training dataset을 batch로 나눠서 학습을 하게 된다. mini batch로 나눠 학습을 하게 되면 이미지 한 장을 쓰는 것보다 데이터 분포를 반영할 수 있고 효율성과 안정적인 수렴 간의 balance를 맞출 수 있다. iteration은 특정 mini batch를 가지고 한 번 학습시킨 것이다. 즉, 한 번 forward & backpropagation을 진행한 것이다. 6,000개의 이미지가 있고 mini batch size를 100개로 설정하면 총 60번의 iteration을 진행한다. 60번의 iteration이 진행되면 training dataset을 전부 학습한 것으로 1 epoch이 끝난 것이다. 1 epoch 후, 전체 데이터셋을 섞고 mini batch를 재정의한다. 즉, 계속해서 똑같은 mini batch로 학습하지 않는다.

아래는 training dataset을 어떻게 처리하냐에 따라 optimization 되는 과정을 보여준다. 2번과 3번 과정을 stochastic gradient descent (SGD)라고 한다.
Optimizer
SGD를 사용할 때, local minima에 빠질 수 있다. loss를 미분할 때, 0이 되어 가중치가 업데이트가 안되고 local minima에 빠질 수 있다. 우리는 global minima를 원하기 때문에 이를 해결해야 한다.
momentum update를 통해 이를 해결한다. 현재 gradient뿐만 아니라, 이전 iteration에서 학습한 것까지 고려한다. 이전에 나아갔던 방향으로 더 이동하려는 힘이 생긴다.
SGD 말고도 다양한 optimizer들이 있다.
- RMSprop: 똑같이 이동 평균을 하는데 suqared gradient를 사용하여 learning rate를 적용한다.
- Adam(Adaptive Moment Estimation): momentum과 RMSprop을 결합한 방법으로 속도와 안정성에 좋아 default optimizer로 사용한다.
- AdaGrad: 각 파라미터마다 learning rate를 적용한다.
Learning rate / scheduling
learning rate는 weight를 얼마나 업데이트할 것인지 결정해주는 것이다.
안정된 학습을 위해 learning rate를 결정하는 것은 중요하다.
learning rate를 scheduling해주는 방법도 있다. learning rate를 적절하게 변형하면서 모델을 학습하는 방법이다. 대부분의 방법들은 이를 사용한다. 일반적으로 초기 단계에서는 조금 큰 learning rate를 사용하며 이후 단계에서 learning rate를 조금씩 줄여 학습한다.
Loss curve and Overfitting
loss curve를 이해하는 것은 모델 학습 진행사항을 이해하는데 중요하다. loss curve를 통해 learning rate를 최적화한다. 또한, loss curve를 확인하고 early stopping을 통해 overfitting을 예방할 수 있다.
Activation functions
Sigmoid
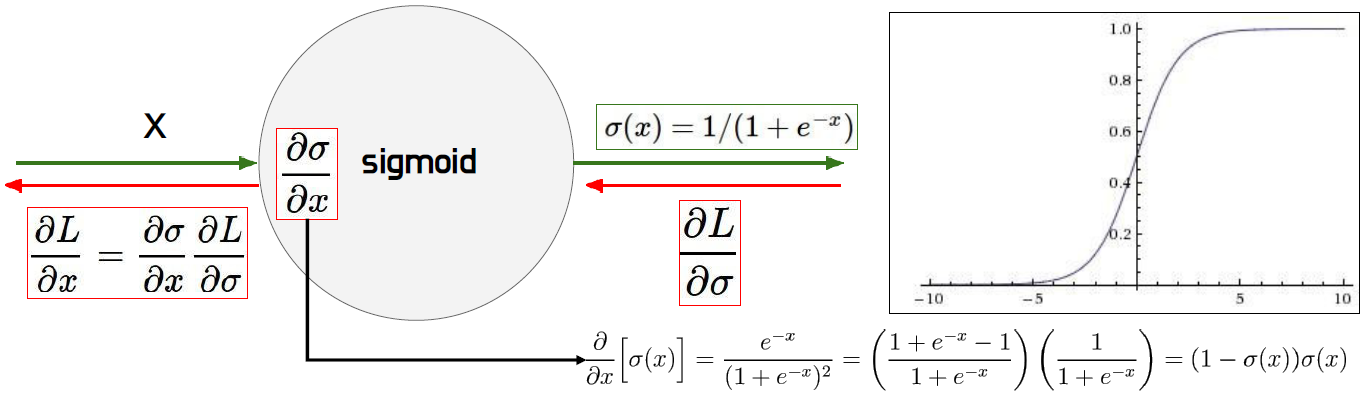
0~1 사이의 값을 가지며 중간 값은 0.5이다. 예전에는 sigmoid 함수가 많이 사용되었는데 요즘은 안사용된다. 그 이유를 살펴보자. sigmoid를 미분하면 (1-sigmoid)*sigmoid이다. x=-10일 때, sigmoid 값은 거의 0에 가까운 값이 되어 결국 loss를 미분한 값이 0에 가까워진다. 이는 gradient vanishing 문제를 일으킨다. 즉, 가중치가 업데이트가 되지 않아 학습이 안된다. x=10일 때도, sigmoid 값은 거의 1에 가까운 값이 되어 sigmoid 미분 값이 0에 가까워진다. 이 또한, gradient vanishing 문제를 일으킨다. sigmoid 미분 값의 최대 값은 0.25이며 -5 미만, -5 초과일 경우 거의 0이된다.
Tanh 함수는 -1에서 1사이의 값을 가진다. 이 또한, 양쪽으로 갈수록 미분 값이 0으로 가까워져 gradient vanishing 문제를 일으켜 잘 안사용한다.

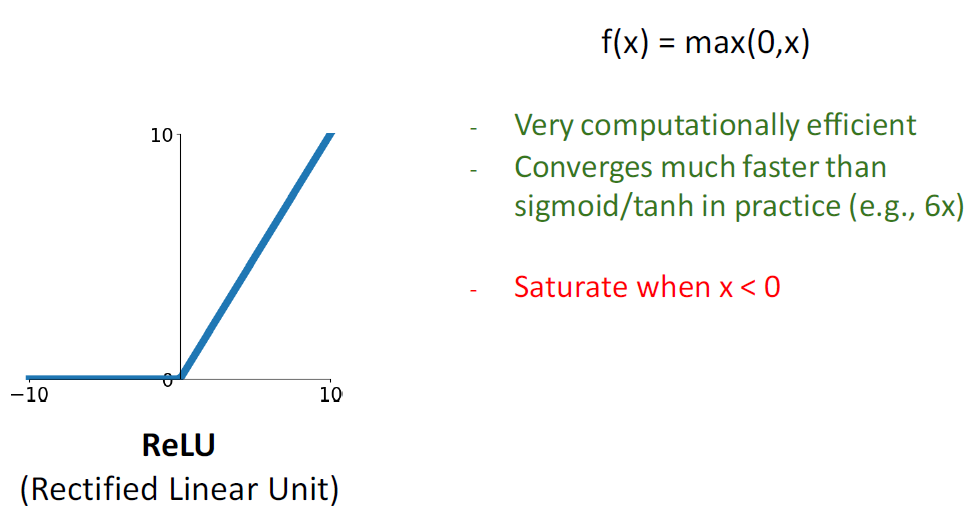
ReLU 함수는 잘 사용된다. X가 양수면 그대로 통과되며 sigmoid와 tanh 함수보다 6배 더 빠르게 학습된다. ReLU 함수를 미분하면 양수일 때, 1. 음수일 때, 0이다. 즉, 양수일 때는 계속 학습이 되지만 음수일 때는 gradient 값이 0이 되어 학습이 되지 않는다. 음수일 때는 학습이 안되는 문제가 있어 다양한 ReLU가 등장한다.
Leaky ReLU는 미분값이 양수일 때는 1, 음수일 때는 0.01으로 되어 chain rule를 지속적으로 학습될 수 있게 수정했다. PReLU는 미분값이 양수일 때는 1, 음수일 때는 알파값으로 되어 음수일 때, 얼마나 backpropagation할 지 학습으로 결정되게 한다.

ELU (Exponential Linear Unit)은 음수일 때, exponential 하게 설정하였다. 작은 음수일때는 기울기를 어느정도 살려서 전달해준다.
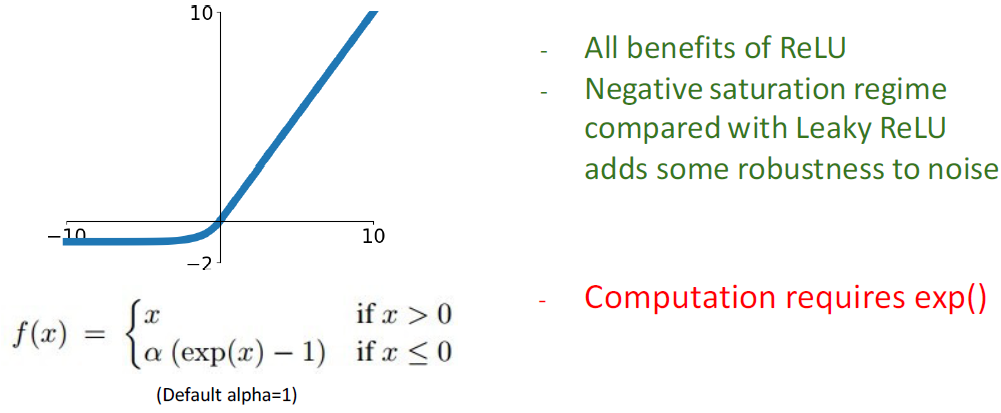
SELU (Scaled Exponential Linear Unit)은 91페이지를 거쳐 수학적으로 최적값을 찾아낸 함수이다.

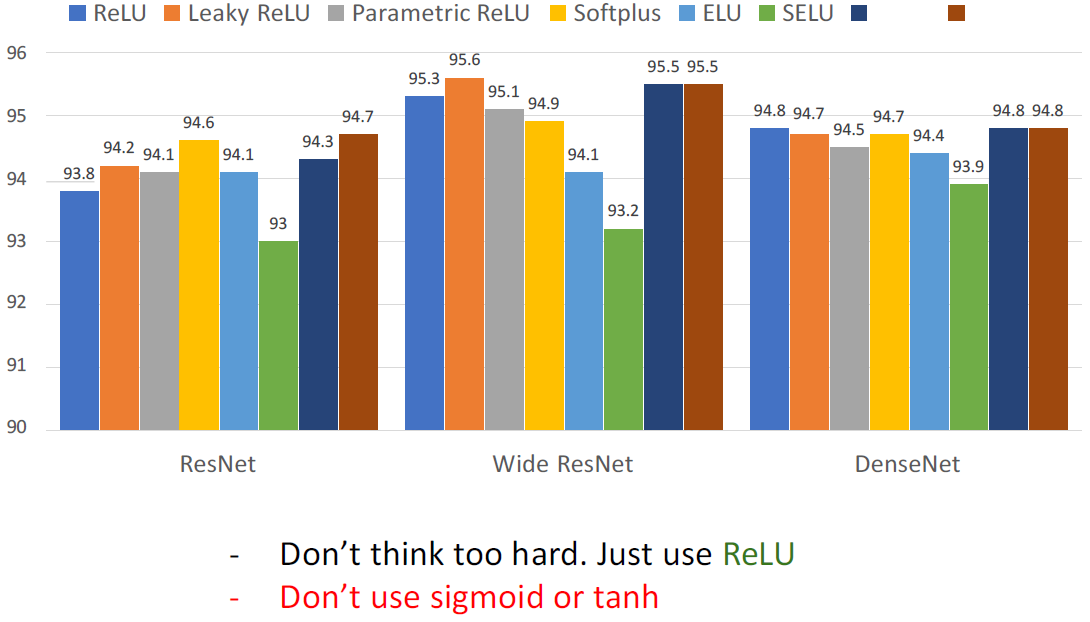
지금까지 배운 activation function을 사용하여 CIFAR10 데이터셋에 대한 실험 결과이다. ReLU나 Leaky ReLU를 사용해도 큰 문제는 없고 sigmoid와 tanh 함수만 안사용하면 된다. (SELU가 오히려 낮은 값이다.)
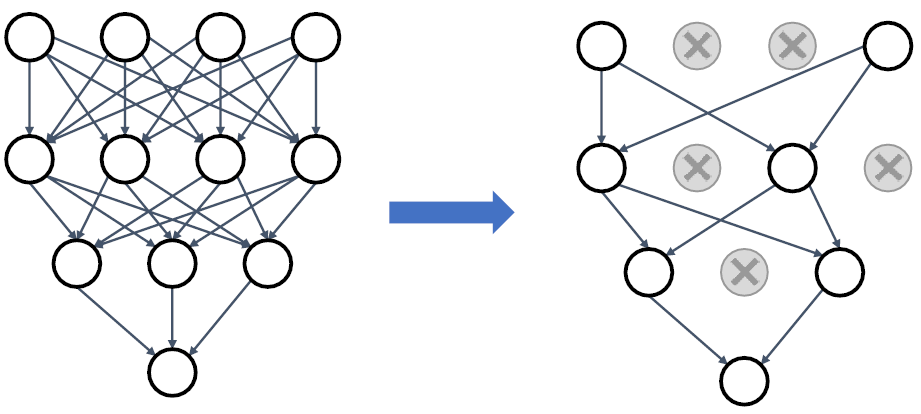
Dropout
Dropout은 forward 과정에서, linear layer에서 랜덤하게 특정 뉴런들을 0으로 변경해주는 것이다. 이를 통해, 다양한 특성 뉴런들을 통해 학습할 수 있도록 하여 성능 향상을 시킬 수 있다.
Data augmentation
이미지를 좌우반전 시키거나 밝기를 조절하고 회전을 시키는 등 다양한 조건의 이미지를 만듦으로써 모델이 더 학습을 잘 할 수 있다.
대표적인 방법으로는 Random Crop과 Scale이 있다. 이는 다양한 부분의 영역으로 잘르거나 확대해서 학습시키는 방법이다.
Color Jitter 방법은 색상을 변경하여 학습시키는 방법이다.
Random erasing 방법은 이미지 일부를 가린 상태에서 학습시키는 방법이다.
즉, 이러한 data augmentation 기법들을 통해 한 이미지를 가지고 다양한 이미지를 만들어 학습시킴으로써 모델 성능을 향상시킨다.
'Lectures > 딥러닝영상인식1' 카테고리의 다른 글
| [Lecture 9] Recurrent Neural Network (0) | 2024.12.16 |
|---|---|
| [Lecture 8] Training Neural Network (0) | 2024.12.16 |
| [Lecture 6] Convolutional Neural Network & Training Neural Network (0) | 2024.12.16 |
| [Lecture 5] Convolutional Neural Network (CNN) (1) | 2024.10.21 |
| [Lecture 4] Convolution (3) | 2024.10.21 |



