본 강의 학습 목표는 다음과 같다.
- Normalization: Input data, Feature map, Model weight
- Deep Learning Hardware: CPU vs GPU, Toeplitz matrix
- Distributed Training: Model parallelism, Data parallelism
Normalization: Input data
Input data의 특징들이 매우 다양한 scale을 가지면 불안정한 학습을 할 수 있다. 따라서, 각 데이터들을 평균이 0이고 표준편차가 1로 normalization을 해준다. 즉, 데이터가 가지고 있는 범위를 조절하여 데이터 분포가 특정 boundary 안에 있게끔 해준다. 이를 통해, 데이터 scale의 민감성을 감소시키고 수렴을 더 빨리 할 수 있게 해준다.

Normalization: Feature map
input data가 normalize가 잘 되었다하더라도 feature map은 normalize가 안될 수 있다. 즉, layer가 깊어질수록 데이터 분포가 흩어질 수 있다. 따라서, feature map에도 normalization을 해준다.
feature map normalization은 input data normalization과 다르게 좀 더 복잡하다. mini batch에서 forward, backward를 진행하는데 feature map이 batch size만큼 존재한다. 여기서 input normalization과 다른 점은 input normalization은 global mean과 standard deviation을 사용하는데 feature map의 경우 전체 training dataset에 대한 mean과 standard deviation을 사용하기에는 비효율적이다. 각 배치마다 bachward를 할때마다, 가중치가 달라지기 때문에 같은 데이터를 통과시키더라도 값이 달라진다. 그러면 각 iteration마다 전체 데이터셋에 대한 평균과 표준편차를 다시 계산하기에는 비효율적이다. 따라서, moving average 개념을 사용한다. batch 단위의 평균과 표준편차를 축적하여 normalize를 한다. 즉, 평균을 빼고 표준편차를 나눠주는게 아니라 이동평균을 빼고 표준편차의 이동평균으로 나눠준다.
x1,x2,x3,x4에서 이동 평균을 계산하면
첫 번째 평균은 x1.
두 번째 평균은 (x1+x2)/2
세 번째 평균은 (x1+x2+x3)/3
네 번째 평균은 (x1+x2+x3+x4)/4 이다.
즉, batch normalization을 정리하면 normalization은 moving average 개념이 포함되어 있다. input은 N개의 CxHxW가 있으면 평균과 표준편차는 1xCx1x1개가 있다. 즉, n개의 데이터와 HxW를 하나로 normalization해준다. Fully-connected layer의 경우는 input이 NxC이면 평균과 표준편차는 차원 수만큼 존재한다.
batch normalization 이외에도 다양한 normalization이 존재한다.
Layer Norm은 평균과 표준편차가 N개 존재.
Instance Norm은 NxC개 존재.
Group Norm은 NxC/(group size)개 존재.
normalization layer는 convolutional 혹은 fully connected layer 후, activation function을 넣기 전에 실행한다. 그리고 training과 test 때 다르게 사용되는데 training때에는 이동 평균을 계속 업데이트해주는데 test때에는 이동 평균을 업데이트 시켜주지 않는다. test할 때는 train에서 마지막에 얻어진 이동 평균을 사용한다.
Noramalization: Model weight
model initalization은 optimization을 어디서부터 시작할지를 정해주는 것이다. 이상한 initialized weight는 gradient가 폭발하거나 너무 작아질 수 있다.
다음과 같이 activation 값이 너무 작아질 수 있다.
너무 큰 값을 곱하게 되면 activation 값이 -1과 +1로만 나뉠 수 있다. (tanh일 경우)
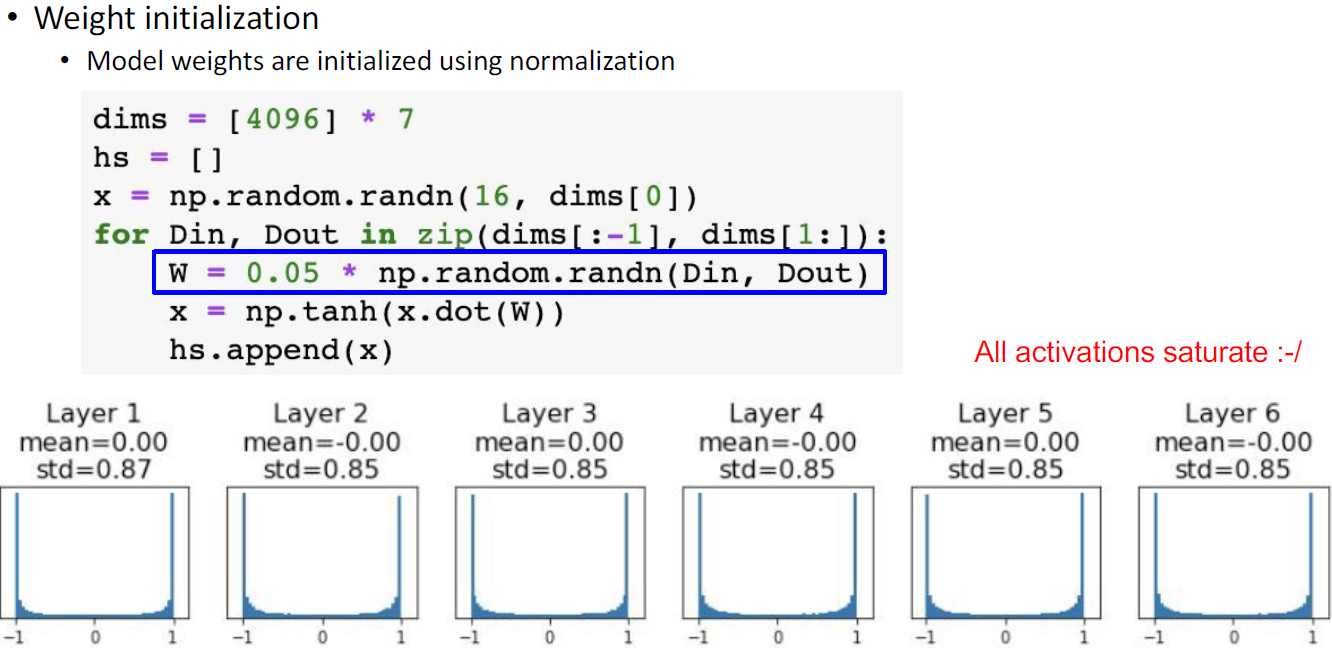
activation 값이 너무 작아지는 그림과 같이 분산이 작아지는 현상이 문제였기 때문에 분산을 유지할 수 있도록 하였다. 각 데이터들의 분산이 같다고 가정한다.오른쪽 칸처럼 식을 변경하면 Din을 나누면 된다.(표준편차)


Xavier initialization은 zero centered activation function으로 가정하기 때문에 sigmoid 함수나 tanh 함수에 적용된다. ReLU를 사용하게 되면, 음수는 0으로 되는 문제가 있다.

He initialization은 표준편차에 2를 곱한걸로 나눠줌으로써 Xavier initialization을 보완한다.

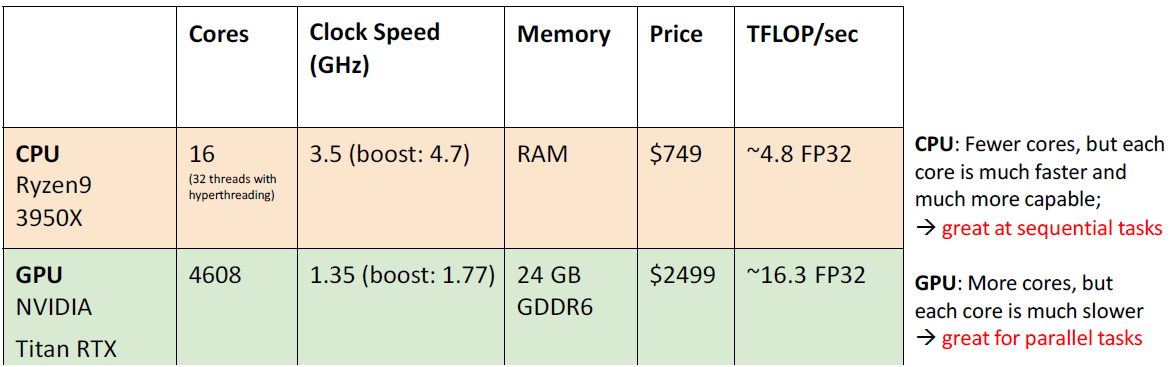
Deep Learning Hardware: CPU vs GPU
CPU: Central Processing Unit
GPU: Graphics Processing Unit
딥러닝은 GPU를 많이 사용하는데 이는 코어의 개수. 처리할 수 있는 일꾼 수 때문이다. CPU는 한 일꾼의 속도가 더 빠르지만 GPU는 일꾼이 느리더라도 일꾼 수가 엄청 많다.
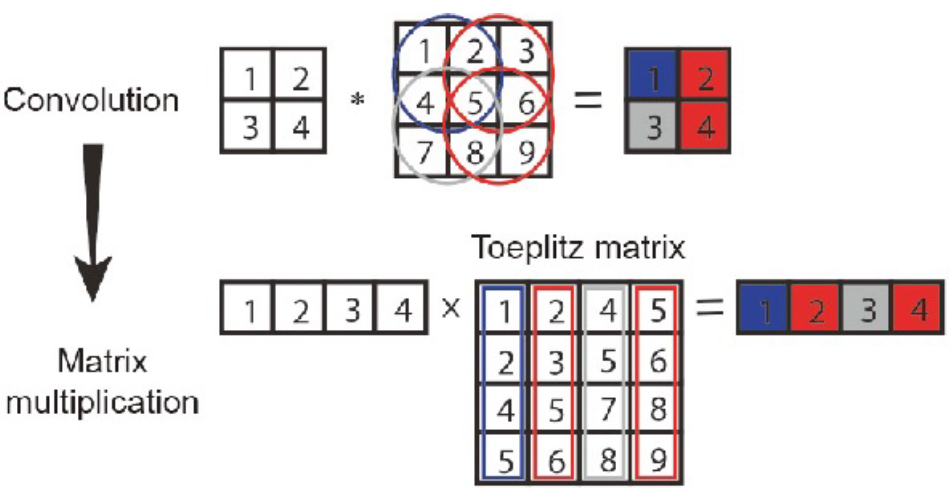
Deep Learning Hardware: Toeplitz matrix
filter가 있고 이미지가 있다고 생각하면 다음과 같이 Toeplitz matrix로 변환하면 convolution matrix 연산이 matrix multiplication으로 한 번에 끝난다. matrix multiplication이 마친 후 다시 reshape을 하여 convolution 연산 결과로 만든다.
matrix multiplication이 GPU에 이상적이다. AxC matrix 각각 나오는 값에 있어서 결과값들끼리 서로 연관이 없기 때문에 각각 구해버리면된다. 여러 개의 일꾼들을 써버리면 된다.
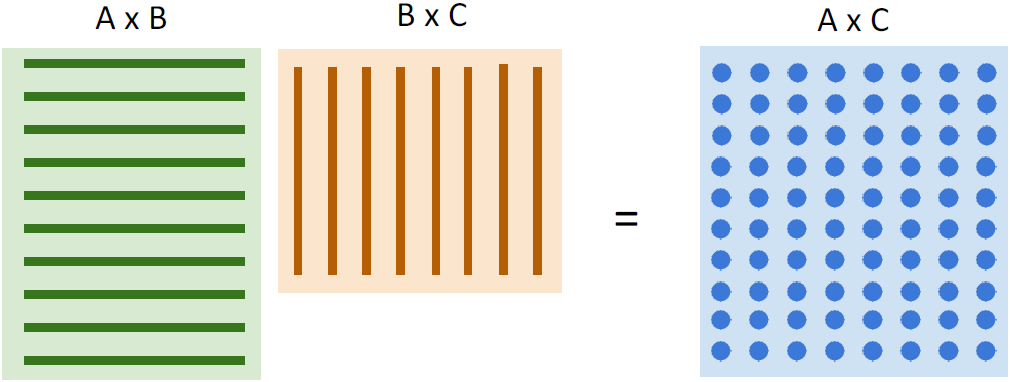
Distributed Training: Model parallelism
AI 모델 크기는 엄청 커지고 있다. 즉, 여러 개의 GPU를 사용해 학습을 시키는 것이 효율적이고 필수적으로 되고 있다. 여러 개의 GPU를 통해 Model parallelism 혹은 Data parallelism을 처리할 수 있다.
이렇게 모델을 나눠서 하면 단점은 모델 앞단을 학습할 때, 모델 뒤에 할당받은 GPU는 놀게된다.

이렇게 채널을 나눠서 GPU에 할당해서 계산되면 너무 복잡해진다. 할당받은 계산 값을 서로 연관지어서 계산해야하기 때문..

Distributed Training: Data parallelism
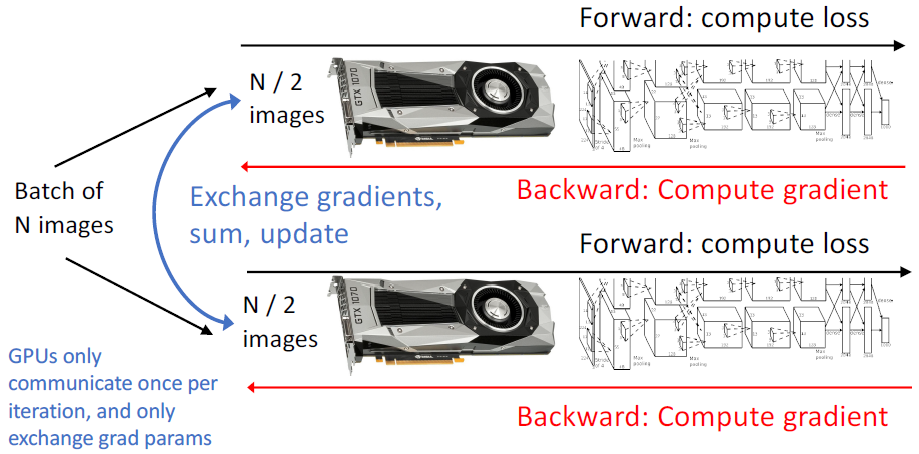
많이 사용되는 방법 중 하나가 Data parallelism이다. 모델은 각각 GPU에 할당하고 batch size에서 GPU 개수만큼 나눠 할당한 후, backward를 진행하여 gradient를 계산한다. 그 후, gradient를 평균내어 가중치를 업데이트한다.
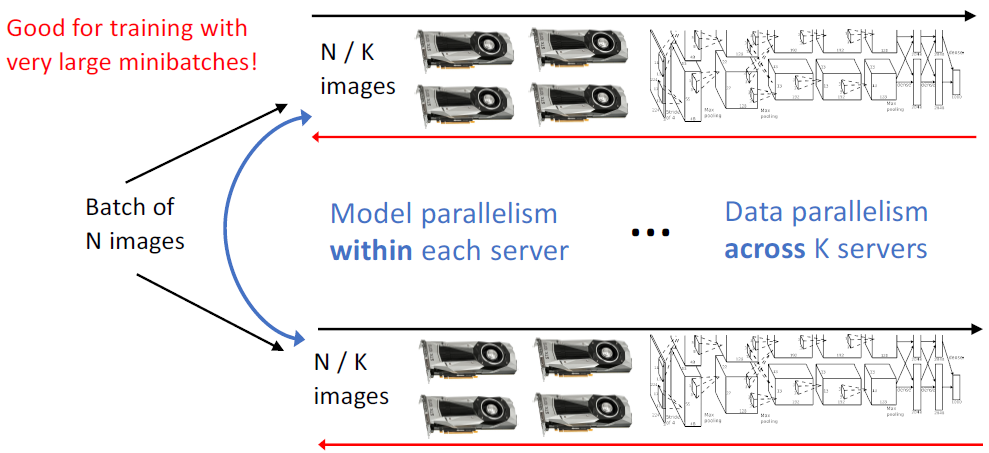
모델이 너무 커서 GPU 하나에 할당하기 어려우면 Model parallelism과 Data parallelism을 동시에 적용한다.
'Lectures > 딥러닝영상인식1' 카테고리의 다른 글
| [Lecture 10] Attention Mechanism and Transformer (0) | 2024.12.16 |
|---|---|
| [Lecture 9] Recurrent Neural Network (0) | 2024.12.16 |
| [Lecture 7] Training Neural Network (0) | 2024.12.16 |
| [Lecture 6] Convolutional Neural Network & Training Neural Network (0) | 2024.12.16 |
| [Lecture 5] Convolutional Neural Network (CNN) (1) | 2024.10.21 |



