본 강의 학습목표는 다음과 같다.
- Sequence to Sequence (Seq2Seq) Model: Sequence to Sequence with RNNs, Sequence to Sequence with RNNs and Attention, Image Captioning with RNNs, Image Captioning with RNNs and Attention
- Transformer: Transformer, Vision Transformer (ViT)
Sequence to Sequence (Seq2Seq) Model
Sequence to Sequence 모델은 input과 output 길이가 달라도 되며 시퀀스 데이터를 처리한다. 기계 번역이나 텍스트 요약에 사용할 수 있다.
Sequence to Sequence with RNNs
Encoder를 통해 input 데이터의 정보를 압축한다. input으로부터 output을 생성해야하는데 Encoder의 마지막 layer에서 나온 값 h4를 initial decoder 상태인 s0과 context vector인 c로 설정한다. s0와 c, y0을 이용해 s1을 생성하여 y1을 출력한다. 그 후, s1과 c, y1을 이용해 s2를 생성하여 y2를 출력한다. 그 후, s2와 c, y2를 이용해 s3를 생성하여 y3를 출력한다. 이렇게 계속 생성한 후, [STOP]이 출력되면 멈춘다. 하지만, input 시퀀스가 너무 많게 되면 초반 정보들이 사라지게 된다. 이를 해결하기 위해, 디토더의 각 스텝마다 새로운 context vector를 사용한다. 이를 위해, Attention을 이용한다.

Sequence to Sequence with RNNs and Attention
인코더 마지막 h4를 그대로 s0으로 설정한다. s0와 각 hidden state 간의 alignment score를 계산한다. MLP나 cosine similarity 등을 이용해 계산할 수 있다. 유사도 점수를 계산한 것들을 softmax를 통해 normalize를 해준다. 이렇게 attention을 각 hidden state에 곱해진 값을 더하여 context vector를 만든다. 즉, attention을 통해 input sequence에서 관련되어 있는 부분을 집중할 수 있게 해준다. 이 과정은 모두 미분 가능하여 backpropation이 가능하여 attention 또한 학습이 가능하다.
두 번째 step은 다음과 같이 진행된다.
Image Captioning with RNNs
RNN을 사용하여 image captioning한 예제는 다음과 같다. 이미지 정보에 대한 context vector와 hidden state를 이용해 문장을 생성한다. 하지만, 아까 발생했던 문제와 같이 context vector에 문제가 생긴다. 각 시퀀스마다 집중해야하는 부분이 다르며 이미지에 대한 모든 정보를 잘 못담을 수 있고 긴 문장을 생성할 경우 문제가 생긴다. 이를 해결하기 위해, attention을 적용한다.
Image Captioning with RNNs and Attention
이미지를 hidden state와 유사도를 계산하여 alignment score를 계산한다. 그 후, softmax를 통해 attention score를 계산한다. attention score와 이미지를 곱하여 context vector를 생성하고 이를 이용해 hidden state h1을 생성하여 y1을 출력한다.
attention score를 통해 어디 부분을 집중하고 있는지 시각화하여 해석 할 수 있다.
Transformer
Transformer은 Encoder와 Decoder로 구성되어 있으며 RNN, CNN, hidden state가 존재하지 않고 Attention 메커니즘만 사용한다.
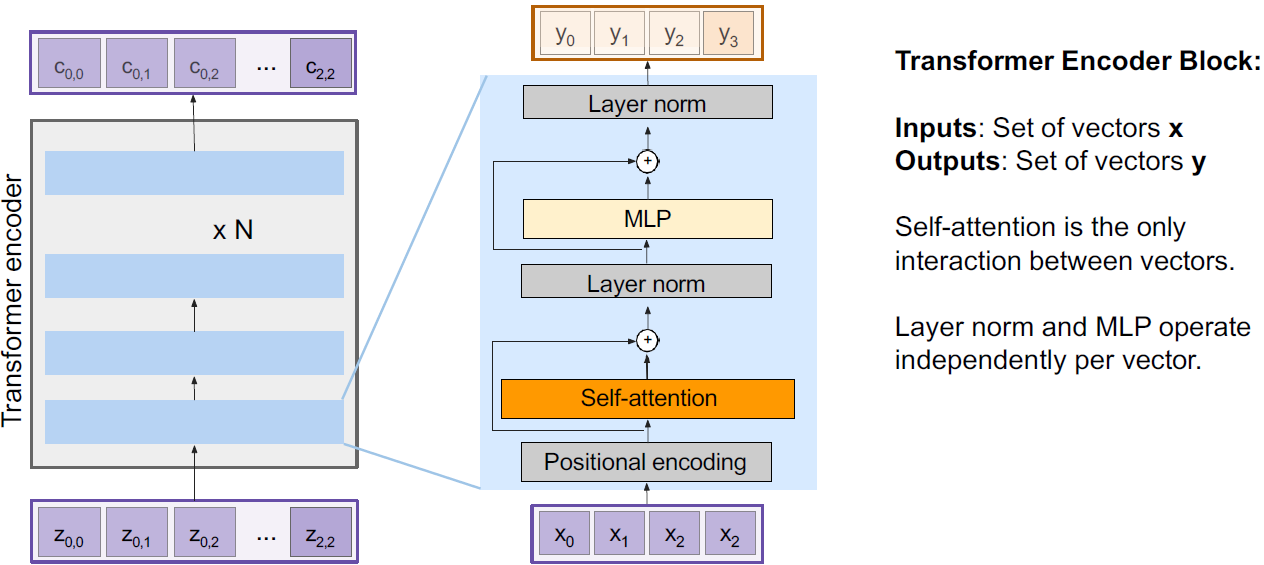
처음, Transformer encoder input에 positional encoding을 추가함으로써 위치 순서 정보를 넣어준다. 그 후, self-attention을 통과한다.
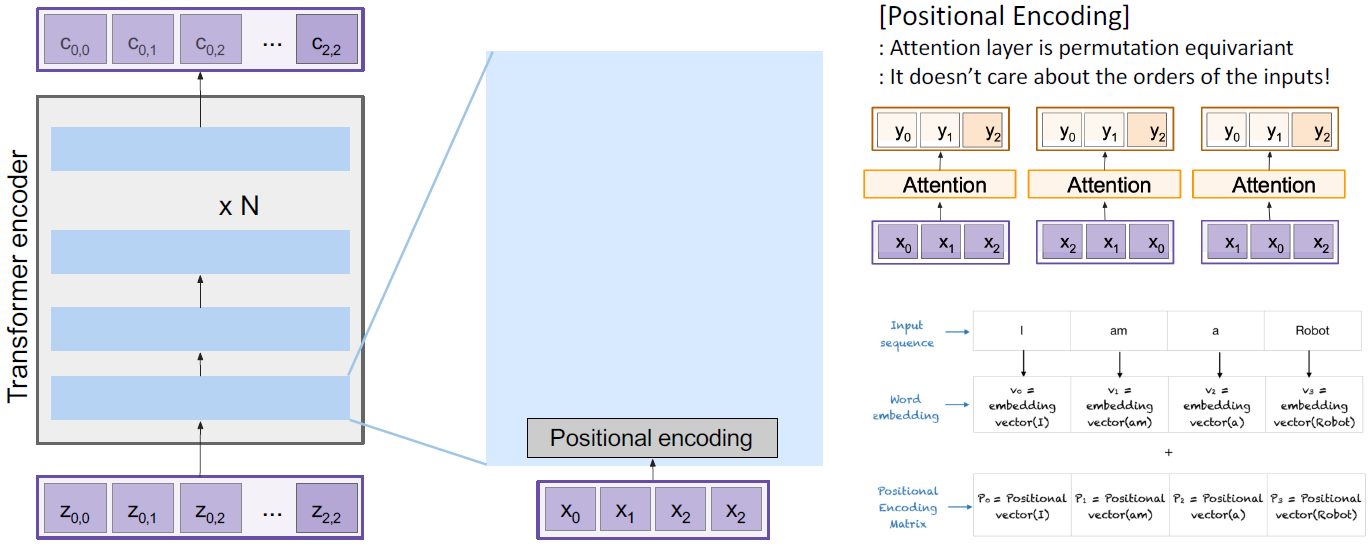
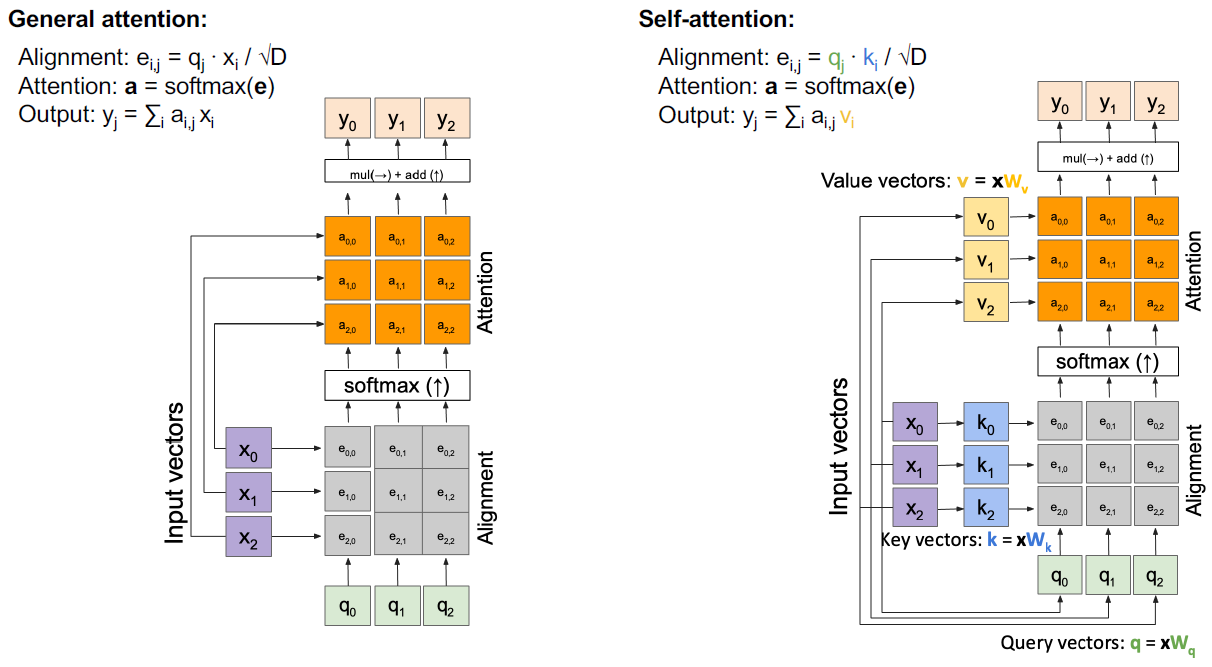
self-attention은 다음과 같이 동작한다. 기존에 전에 배웠던 attention 메커니즘은 input 특징을 hidden state와 곱하여 alignment를 계산하고 softmax를 거쳐 attention score를 계산한 후, input 특징과 attention score와 곱하였다. self-attention은 query, key, value라는 것이 있고 이는 input 벡터로부터 만들어진다. query와 key가 곱하여 alignment를 계산하고 softmax를 거쳐 attention score를 계산한 후, value와 곱해져서 최종 output을 출력한다. 말그대로, self-attention. 스스로 key, value, query를 만들어 계산한다.
self attention을 통과한 후 residual connection을 수행하고 layer normalization을 하고 MLP를 통과하고 residual connection을 수행하고 layer noramlization을 하여 output을 출력한다. 이게 하나의 encoder이다.
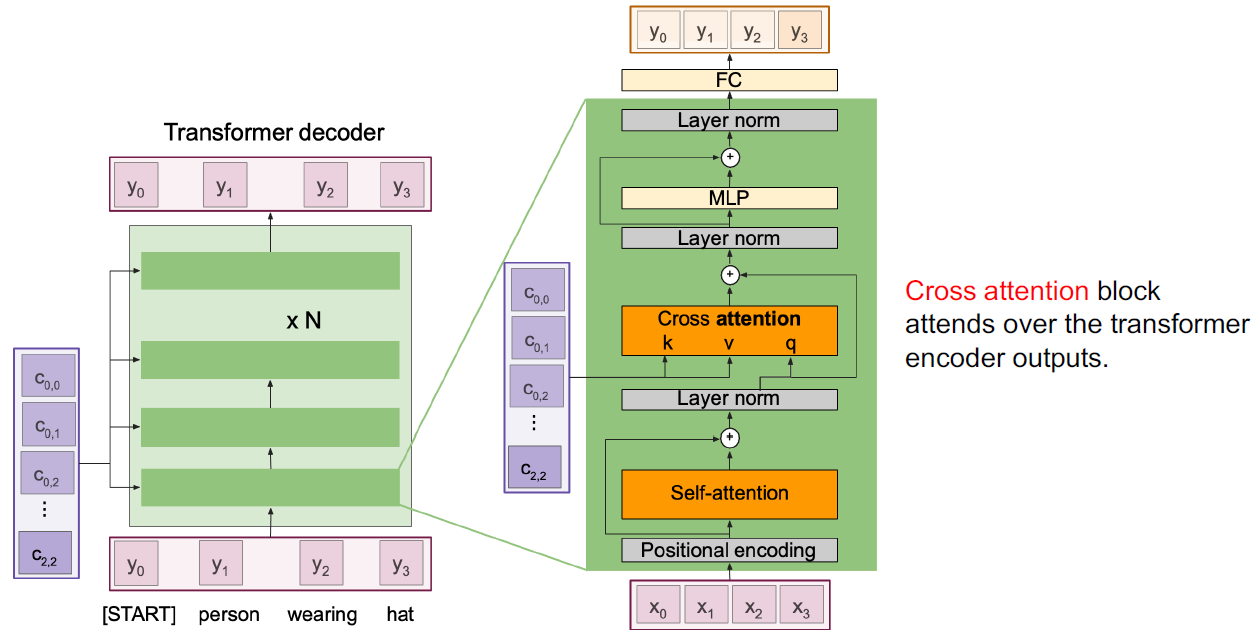
Decoder도 positional encoding을 더하여 self-attention에 넣는다. encoder와 다른 점은 cross attention이 있다는 것이다. cross attention은 self-attention과 다른 점은 query를 스스로 만들지 않고 encoder에서 나온 결과를 query로 사용한다는 것이다.
RNN vs Transformer
RNN
- (+) LSTMs work reasonably well for long sequences
- (-) Expects an ordered sequences of inputs
- (-) Sequential computation: subsequent hidden states can only be computed after the previous ones are done
Transformer
- (+) Very good at long sequences. Each attention calculation looks at all inputs.
- (+) arallel computation: All alignment and attention scores for all inputs can be done in parallel
- (-) Requires a lot of memory: N x M alignment and attention scalers need to be calculated and stored for a single self-attention head. (but GPUs are getting bigger and better)
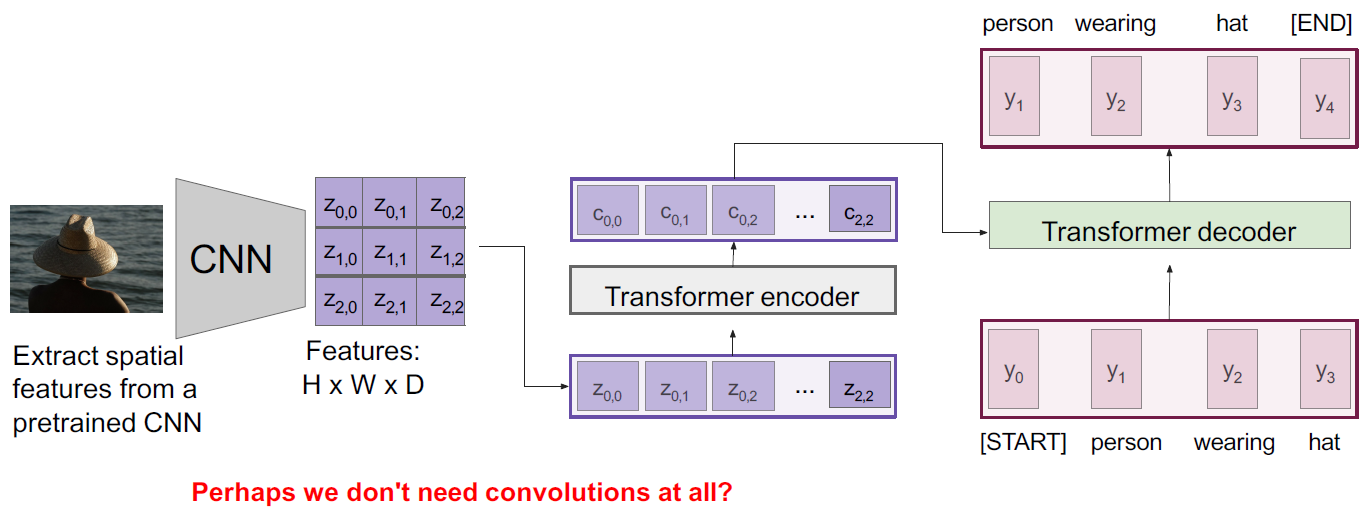
Image Captioning with Transformer
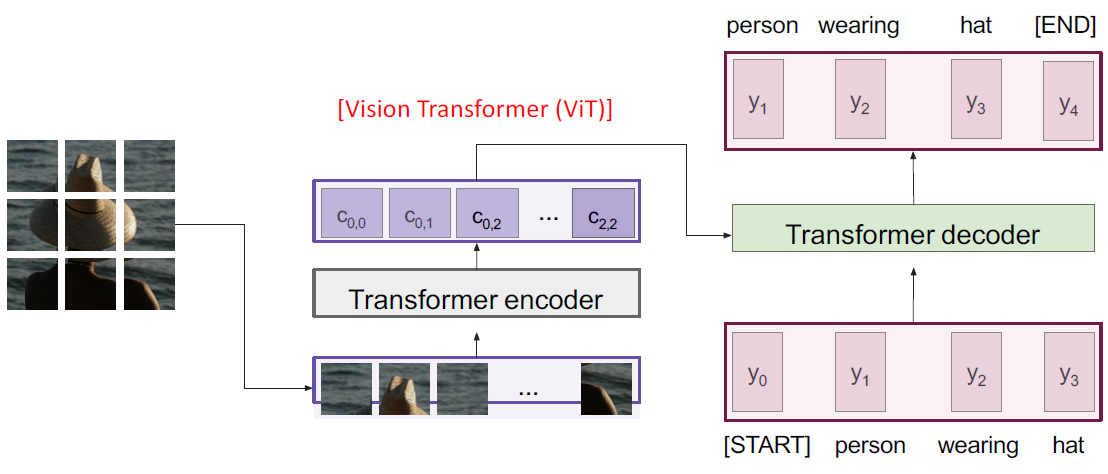
Vision Transformer (ViT)
CNN을 없애고 Transformer만 이용하여 image captioning을 할 수 있다.
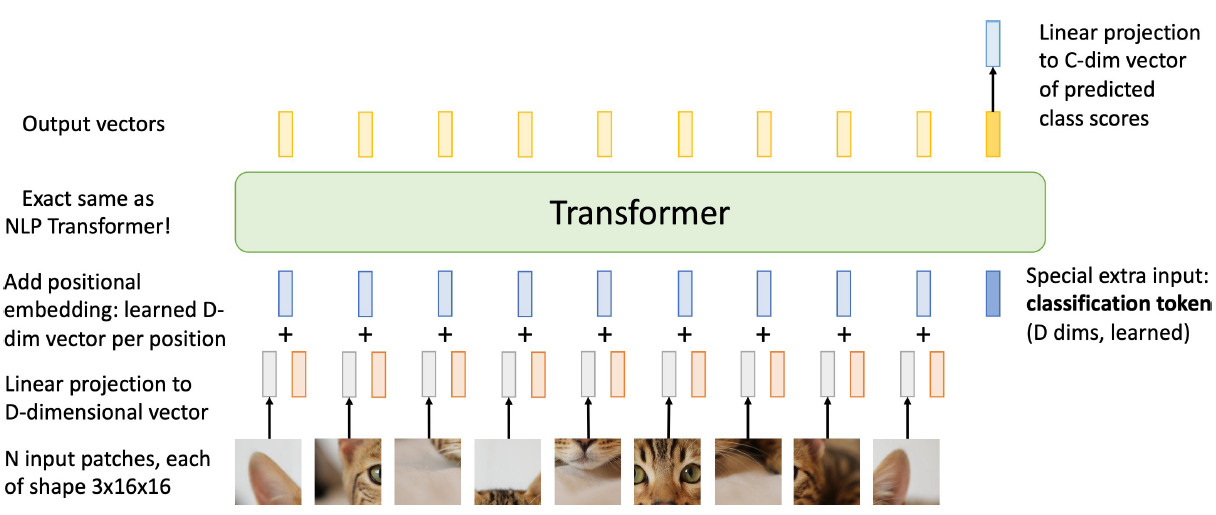
이미지를 16x16 크기인 패치로 나눠준 후 나열한다. 그 후, linear layer를 통해 벡터로 변환한다. positional encoding을 더한 후 transformer encoder를 통과한다. 학습가능한 classification token을 추가한다. 마지막 토큰에 linear layer를 통과하여 class score를 얻어낸다.
'Lectures > 딥러닝영상인식1' 카테고리의 다른 글
| [Lecture 11] Image Segmentation and Object Detection (1) | 2024.12.17 |
|---|---|
| [Lecture 9] Recurrent Neural Network (0) | 2024.12.16 |
| [Lecture 8] Training Neural Network (0) | 2024.12.16 |
| [Lecture 7] Training Neural Network (0) | 2024.12.16 |
| [Lecture 6] Convolutional Neural Network & Training Neural Network (0) | 2024.12.16 |



