본 글은 https://arxiv.org/abs/2106.08254 내용을 기반으로 합니다.
혹시 잘못된 부분이나 수정할 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
Abstract
Image Transformer에서 양방향 인코더 표현을 의미하는 BEIT(Bidirectional Encoder representation from Image Transformers)라는 serlf-supervised vision representation 모델을 소개한다. 자연어 처리 분야에서 개발된 BERT를 따르며, vision Transformer를 사전 훈련하기 위해 masked image modeling task를 제안한다. 구체적으로, 사전 훈련에서는 각 이미지가 두 가지 뷰, 즉 이미지 패치(예: 16x16 픽셀)와 시각적 토큰(즉, discrete token)을 가진다. 먼저 원본 이미지를 시각적 토큰으로 토큰화한다. 그런 다음 일부 이미지 패치를 무작위로 마스킹하고 이를 backbone Transformer에 입력한다. 사전 훈련 objective는 손상된 이미지 패치를 기반으로 원래의 시각적 토큰을 복원하는 것이다. BEIT를 사전 훈련한 후, 사전 훈련된 인코더 위에 task layer를 추가하여 모델 매개변수를 직접 파인튜닝한다. 이미지 분류 및 semantic segmentation에 대한 실험 결과는 이전 사전 훈련 방법과 경쟁력 있는 결과를 달성함을 보여준다.
1. Introduction
Transformer는 컴퓨터 비전 분야에서 유망한 성능을 달성했다. 그러나 경험적 연구에 따르면 vision Transformer는 CNN보다 더 많은 훈련 데이터가 필요하다. 데이터 부족 문제를 해결하기 위해, self-supervised pre-training은 대규모 이미지 데이터를 활용할 수 있는 유망한 해결책이다. contrastive learning 및 self-distillation과 같은 여러 방법이 vision Transformer에 대해 탐구되었다.
동시에, BERT는 자연어 처리에서 큰 성공을 거두었다. BERT의 masked language modeling task는 먼저 텍스트 내 일부 비율의 토큰을 무작위로 마스킹한 후, 손상된 텍스트의 Transformer 인코딩 결과를 기반으로 마스킹된 토큰을 복구한다. BERT의 영감을 받아, vision 커뮤니티에서 잘 연구되지 않은 vision Transformer를 사전 훈련하기 위해 denoising auto-encoding 아이디어로 전환한다. 이미지 데이터에 BERT 스타일의 사전 훈련을 직접 적용하는 것은 어려운 일이다. 우선, vision Transformer의 입력 단위인 이미지 패치에 대한 사전 정의된 어휘가 없다. 따라서 마스킹된 패치에 대한 모든 가능한 후보를 예측하기 위해 softmax 분류기를 간단히 사용할 수 없다. 반면에 단어 및 BPE와 같은 언어 어휘는 잘 정의되어 있어 자동 인코딩 예측을 용이하게 한다. 간단한 대안으로는 마스킹된 패치의 원시 픽셀을 예측하는 회귀 문제로 간주하는 것이다. 그러나 이러한 픽셀 수준 복구 task는 사전 훈련의 단기 의존성 및 고주파 세부 사항에 모델링 능력을 낭비하는 경향이 있다. 본 논문의 목표는 vision Transformer의 사전 훈련을 위한 위의 문제를 극복하는 것이다.
이 연구에서는 Bidirectional Encoder representation from Image Transformers를 의미하는 self-supervised vision representation 모델 BEIT를 소개한다. BERT에서 영감을 받아 masked image modeling (MIM)이라는 사전 훈련 task를 제안한다. Figure 1에서 볼 수 있듯이, MIM은 각 이미지에 대해 이미지 패치와 시각적 토큰이라는 두 가지 뷰를 사용한다. 이미지를 backbone Transformer의 입력 표현인 패치 그리드로 나눈다. 또한 이미지를 discrete VAE의 잠재 코드로 얻은 discrete 시각적 토큰으로 토큰화한다. 사전 훈련 동안 일부 비율의 이미지 패치를 무작위로 마스킹하고 손상된 입력을 Transformer에 입력한다. 모델은 마스킹된 패치의 원시 픽셀이 아니라 원본 이미지의 시각적 토큰을 복원하는 법을 배운다.

self-supervised learning을 수행한 후 사전 훈련된 BEIT를 이미지 분류 및 의미론적 분할 두 가지 downstream task에 파인튜닝한다. 실험 결과 BEIT는 초기부터 훈련한 모델 및 이전의 강력한 self-supervised 모델들을 능가하는 성능을 보였다. 또한, BEIT는 supervised 사전 훈련과 보완적이다. ImageNet 라벨들을 사용한 중간 파인튜닝을 통해 BEIT의 성능을 더욱 향상시킬 수 있다. ablation study는 이미지 데이터에 대한 BERT 스타일 사전 훈련의 효과에서 본 연구에서 제안한 기술이 중요함을 보여준다. 성능 외에도 파인튜닝의 수렴 속도와 안정성의 개선은 최종 task의 훈련 비용을 줄여준다. 또한, self-supervised BEIT가 사전 훈련을 통해 합리적인 의미 영역을 학습할 수 있음을 보여주어 이미지에 포함된 풍부한 supervision 신호를 활용할 수 있다.
본 연구의 contribution은 다음과 같이 요약된다.
- vision Transformer를 self-supervised 방식으로 사전 훈련하기 위해 masked image modeling task를 제안한다. 또한 variational autoencoder 관점에서 이론적 설명을 제공한다.
- BEIT를 사전 훈련하고 이미지 분류 및 의미론적 분할과 같은 downstream task에서 광범위한 파인튜닝 실험을 수행한다.
- self-supervised BEIT의 self-attention 메커니즘이 인간 주석을 사용하지 않고도 의미 영역과 객체 경계를 구별하는 법을 학습한다는 것을 보여준다.
2. Methods
주어진 input 이미지 x에 대해 BEIT는 이를 맥락화된 벡터 표현으로 인코딩한다. Figure 1에서 볼 수 있듯이, BEIT는 self-supervised learning 방식으로 masked image modeling (MIM) task를 통해 사전 훈련된다. MIM은 인코딩 벡터를 기반으로 마스킹된 이미지 패치를 복원하는 것을 목표로 한다. downstream task를 위해 사전 훈련된 BEIT 위에 task layer를 추가하고 특정 데이터셋에서 파라미터를 파인튜닝한다.
2.1 Image representations
본 연구의 방법에서는 이미지가 두 가지 뷰의 표현(이미지 패치와 시각적 토큰)을 가진다. 이 두 가지 유형은 각각 사전 훈련 동안 입력 및 출력 표현으로 사용된다.
2.1.1 Image Patch
2D 이미지는 패치 시퀀스로 분할되어 standard Transformer가 이미지 데이터를 직접 수용할 수 있다. 형식적으로, 이미지를 R H x W x C로 재구성하여 N = HW / P^2 패치 R N x (P^2C)로 나눈다. 여기서 C는 채널 수, (H, W)는 input 이미지 해상도, (P, P)는 각 패치의 해상도이다. 이미지 패치는 벡터로 평탄화되고 선형적으로 투영되며 이는 BERT의 단어 임베딩과 유사하다. 이미지 패치는 원시 픽셀을 유지하며 BEIT의 input 특징으로 사용된다.
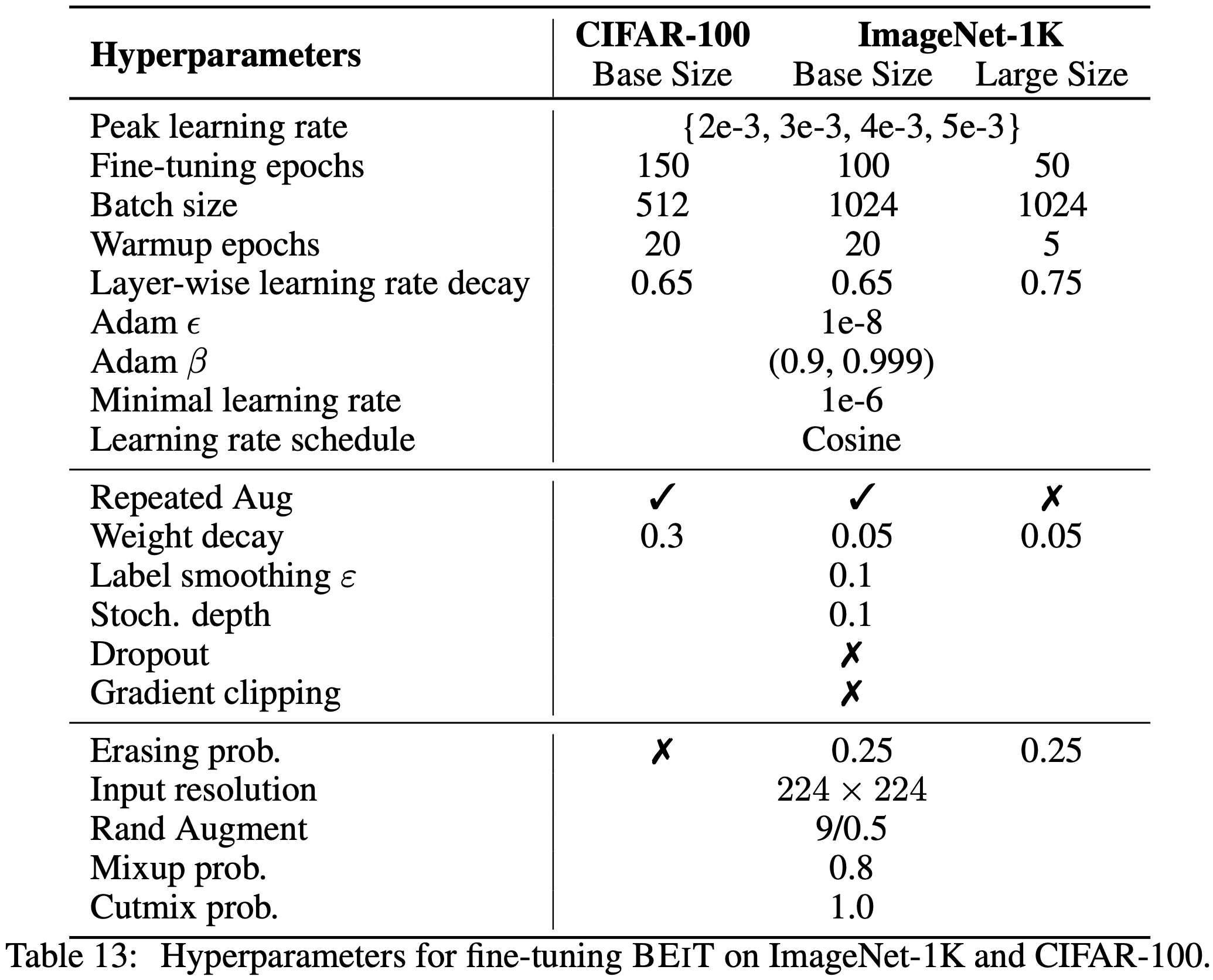
실험에서, 각 224 x 224 이미지를 16 x 16 크기의 패치로 이루어진 14 x 14 그리드로 나눈다.
2.1.2 Visual Token
자연어와 유사하게, 이미지를 원시 픽셀이 아닌 이미지 토크나이저에 의해 얻어진 discrete 토큰 시퀀스로 표현한다. 구체적으로, 이미지를 R H x W x C에서 z = [z1, ..., zN] 으로 토큰화하며 여기서 어휘 V = {1, ..., |V|}는 discrete 토큰 인덱스를 포함한다.
이전 연구에 따라, discrete variational autoencoder (dVAE)가 학습한 이미지 토크나이저를 사용한다. 시각적 토큰 학습에는 토크나이저와 디코더라는 두 가지 모듈이 있다. 토크나이저 q는 시각적 코드북(즉, 어휘)에 따라 이미지 픽셀 x를 discrete 토큰 z로 매핑한다. 디코더 p는 시각적 토큰 z를 기반으로 input 이미지 x를 재구성하는 법을 학습한다. 재구성 목표는 다음과 같이 작성할 수 있다.

잠재 시각적 토큰이 discrete하므로 모델 훈련은 비미분 가능이다. Gumbel-softmax relaxation이 모델 파라미터를 훈련하는 데 사용된다. 또한, dVAE 훈련 중 q에 균일한 우선 순위를 둔다. 이미지 토크나이저의 더 많은 훈련 세부사항은 이전 연구를 참조하면 된다.
각 이미지를 14 x 14 그리드의 시각적 토큰으로 토큰화한다. 하나의 이미지에 대한 시각적 토큰 수와 이미지 패치 수는 동일하다. 어휘 크기는 |V| = 8192로 설정한다. 본 연구에서 이전 연구에 설명된 공개 이미지 토크나이저를 직접 사용한다. 부록 C에서 다시 구현된 토크나이저와 비교도 수행한다.
2.2 Backbone Network: Image Transformer
ViT에 따라, 표준 Transformer를 backbone 네트워크로 사용한다. 따라서 네트워크 아키텍처 측면에서 이전 연구와 직접 비교할 수 있다.
Transformer의 input은 이미지 패치의 시퀀스이다. 그런 다음 패치는 선형적으로 투영되어 패치 임베딩을 얻는다. 또한, 입력 시퀀스에 특별한 토큰 [S]를 앞에 붙인다. 그리고 표준 학습 가능한 1D position 임베딩을 패치 임베딩에 추가한다. input 벡터 H0가 Transformer에 입력된다. 인코더는 Transformer 블록의 L개의 layer로 구성된다. 마지막 layer의 output 벡터 HL은 이미지 패치에 대한 인코딩된 표현으로 사용된다.
2.3 Pre-Training BEIT: Masked Image Modeling
masked image modeling (MIM) task를 제안한다. 이미지 패치의 일정 비율을 무작위로 마스킹한 다음, 마스킹된 패치에 해당하는 시각적 토큰을 예측한다. Figure 1은 본 연구 방법의 개요를 보여준다. section 2.1에서 설명한 것처럼, input 이미지 x가 주어지면 이를 N개의 이미지 패치로 나누고 N개의 시각적 토큰으로 토큰화한다. 이미지 패치의 약 40%를 무작위로 마스킹하며, 마스킹된 위치를 {1, ..., N}으로 나타낸다. 다음으로 마스킹된 패치를 학습 가능한 임베딩으로 대체한다. 손상된 이미지 패치는 section 2.2에서 설명한 대로 L-layer Transformer에 입력된다. 마지막 hidden 벡터는 input 패치의 인코딩된 표현으로 간주된다. 각 마스킹된 위치에 대해, softmax 분류기를 사용하여 해당 시각적 토큰을 예측한다. pre-training objective는 손상된 이미지가 주어졌을 때 올바른 시각적 토큰 z의 log-likelihood를 최대화하는 것이다.
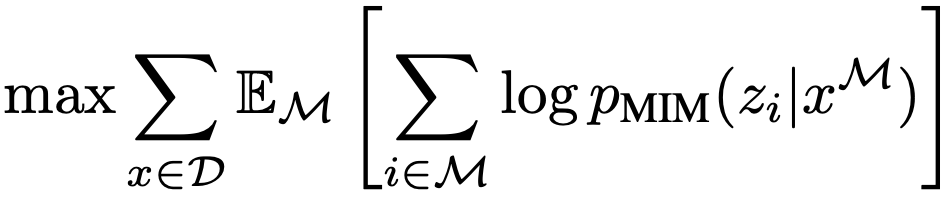
여기서 D는 training corpus이고 M은 무작위로 마스킹된 위치를 나타내고 x^M은 M에 따라 마스킹된 손상된 이미지이다.
마스킹된 위치 M을 무작위로 선택하는 대신, 본 연구에서 블록 단위 마스킹을 사용한다. Algorithm 1에 요약된 것처럼, 각 블록마다 이미지 패치의 블록을 마스킹한다. 각 블록에 대해 패치의 최소 수를 16으로 설정한다. 그런 다음 마스킹 블록의 종횡비를 무작위로 선택한다. 위의 두 단계를 0.4N, 즉 총 이미지 패치 수 N의 40%를 얻을 때까지 반복한다.

MIM task는 자연어 처리에서 가장 성공적인 사전 훈련 목표 중 하나인 masked language modeling에서 크게 영감을 받았다. 또한, 블록 단위(또는 n-gram) 마스킹은 BERT 유사 모델에서도 널리 적용된다. 그러나 vision 사전 훈련을 위해 픽셀 수준의 auto-encoding(즉, 마스킹된 패치의 픽셀을 복원)을 직접 사용하는 것은 모델이 단기 의존성 및 고주파 세부 사항에 집중하게 만든다. BEIT는 세부 사항을 고수준 추상화로 요약하는 discrete 시각적 토큰을 예측함으로써 이러한 문제를 극복한다. section 3.3의 ablation study는 제안한 방법이 픽셀 수준 auto-encoding을 크게 능가함을 보여준다.
2.4 From the Perspective of Variational Autoencoder
BEIT 사전 훈련은 variational autoencoder 훈련으로 볼 수 있다. x를 원본 이미지, x~를 마스킹된 이미지, z를 시각적 토큰으로 나타낸다. 손상된 버전으로부터 원본 이미지를 복원하는 log-likelihood의 증거 하한(ELBO)을 고려한다.

(1) q는 시각적 토큰을 얻는 이미지 토크나이저를 나타낸다.
(2) p(x|z)는 input 시각적 토큰을 주어진 원본 이미지를 디코딩한다.
(3) p(z|x~)는 마스킹된 이미지를 기반으로 시각적 토큰을 복원하는 것으로, 이는 MIM pre-training task이다.
본 논문은 이전 연구들과 유사한 두 단계 절차를 따른다. 첫 번째 단계에서 discrete variational autoencoder로 이미지 토크나이저를 얻는다. 구체적으로, 첫 번째 단계는 식 (2)에서 설명한 대로 균일한 우선 순위를 사용하여 재구성 손실을 최소화한다. 두 번째 단계에서는 q와 p를 고정한 상태에서 우선순위 p세타를 학습한다. q를 가장 가능성이 높은 시각적 토큰을 가진 일점 분포로 단순화한다. 그러면 식 (2)는 다음과 같이 다시 쓸 수 있다.
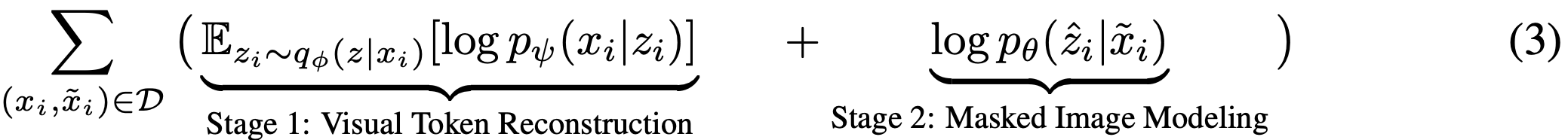
여기서 두 번째 항은 BEIT 사전 훈련 목표이다.
2.5 Pre-Training Setup
BEIT의 네트워크 아키텍처는 공정한 비교를 위해 ViT-Base를 따른다. 12-layer Transformer를 사용하며 768 hidden size와 12 attention head를 갖는다. feed-forward netowrk의 중간 크기는 3072이다. 기본 16 x 16 input 패치 크기를 사용한다. 이전 연구에서 학습된 이미지 토크나이저를 직접 차용한다. 시각적 토큰의 어휘 크기는 8192이다.
약 120만 개의 이미지를 포함하는 ImageNet-1K의 훈련 세트에서 BEIT를 사전 훈련한다. 본 논문의 증강 정책은 무작위로 크기 조정된 cropping, horizontal flipping, color jittering을 포함한다. self-supervised learning을 위해 라벨을 사용하지 않는다. 실험에서 224 x 224 해상도를 사용한다. input은 14 x 14 이미지 패치와 동일한 양의 시각적 토큰으로 분할한다. 최대 75개의 패치(즉, 전체 이미지 패치의 약 40%)를 무작위로 마스킹한다.
사전 훈련은 batch size 2000으로 약 50만 step(즉, 800 epoch)동안 실행된다. 최적화에는 Adam을 사용한다. 학습률은 1.5e-3으로 설정되며 10 epoch 동안 warmup하고 cosine learning rate decay를 사용한다. weight decay는 0.05이다. 0.1 비율로 stochastic depth를 사용하고 dropout은 사용하지 않는다. 50만 training step은 16개의 Nvidia Tesla V100 32GB GPU 카드로 약 5일이 걸린다.
특히 대규모 사전 훈련의 경우 Transformer를 안정화하기 위해 적절한 초기화가 중요하다는 것을 발견했다. 먼저 모든 매개변수를 작은 범위 내에서 무작위로 초기화한다. 그런 다음 l번째 Transformer layer에 대해 self-attention 모듈과 feed-forward network의 각 sub-layer 내 마지막 linear projection의 춫력 행렬을 1/루트(2l)로 rescale한다.
2.6 Fine-Tuning BEIT on Downstream Vision Tasks
BEIT를 사전 훈련한 후, Transformer 위에 task layer를 추가하고 BERT와 마찬가지로 downstream task에서 파라미터를 파인튜닝한다. 본 연구에서 이미지 분류와 semantic segmentation을 예로 든다. BEIT를 사용하여 다른 vision task에서도 pre-training-then-fine-tuning 패러다임을 활용하는 것은 간단하다.
Image classification.
이미지 분류 task에서는 간단한 선형 분류기를 task layer로 직접 사용한다. 구체적으로, 평균 풀링을 사용하여 표현을 집계하고 이를 softmax 분류기에 입력한다. BEIT와 softmax 분류기의 파라미터를 업데이트하여 레이블이 지정된 데이터의 likelihood를 최대화한다.
Semantic segmentation.
Segmantic segmentation의 경우, SETR-PUP에서 사용된 task layer를 따른다. 구체적으로, 사전 훈련된 BEIT를 backbone encoder로 사용하고 여러 deconvolution layer들을 디코더로 통합하여 분할을 생산한다. 모델은 이미지 분류와 유사하게 end-to-end로 파인튜닝한다.
Intermediate fine-tuning.
self-supervised pre-training 후, 데이터가 풍부한 중간 데이터셋(즉, 본 연구에서는 ImageNet-1K)에서 BEIT를 추가로 훈련한 후 타겟 downstream task에서 모델을 파인튜닝할 수 있다. 이러한 intermediate fine-tuning은 NLP에서 BERT 파인 튜닝의 일반적인 관행이다. 이 방법을 BEIT에 직접 적용한다.
3. Experiments
이미지 분류와 semantic segmentation에 대한 완전한 파인 튜닝 실험을 수행한다. 또한, 사전 훈련에 대한 다양한 ablation study를 제시하고 BEIT가 학습한 표현을 분석한다. 부록 D에서는 ImageNet에 대한 linear probe도 보고한다.
3.1 Image Classification
이미지 분류 task는 input 이미지를 다양한 범주로 분류한다. 1,000개의 클래스와 130만 개의 이미지를 가진 ILSVRC-2012 ImageNet 데이터셋에서 BEIT를 평가한다. 공정한 비교를 위해 파인 튜닝 실험에서 DeiT의 대부분의 하이퍼파라미터를 직접 따른다. BEIT는 사전 훈련되었기 때문에 초기부터 훈련하는 것에 비해 파인 튜닝 epoch을 줄였다. 따라서 더 큰 학습률을 사용하고 layer별로 감소시킨다. 자세한 하이퍼파라미터는 부록 H에 요약되어 있다.
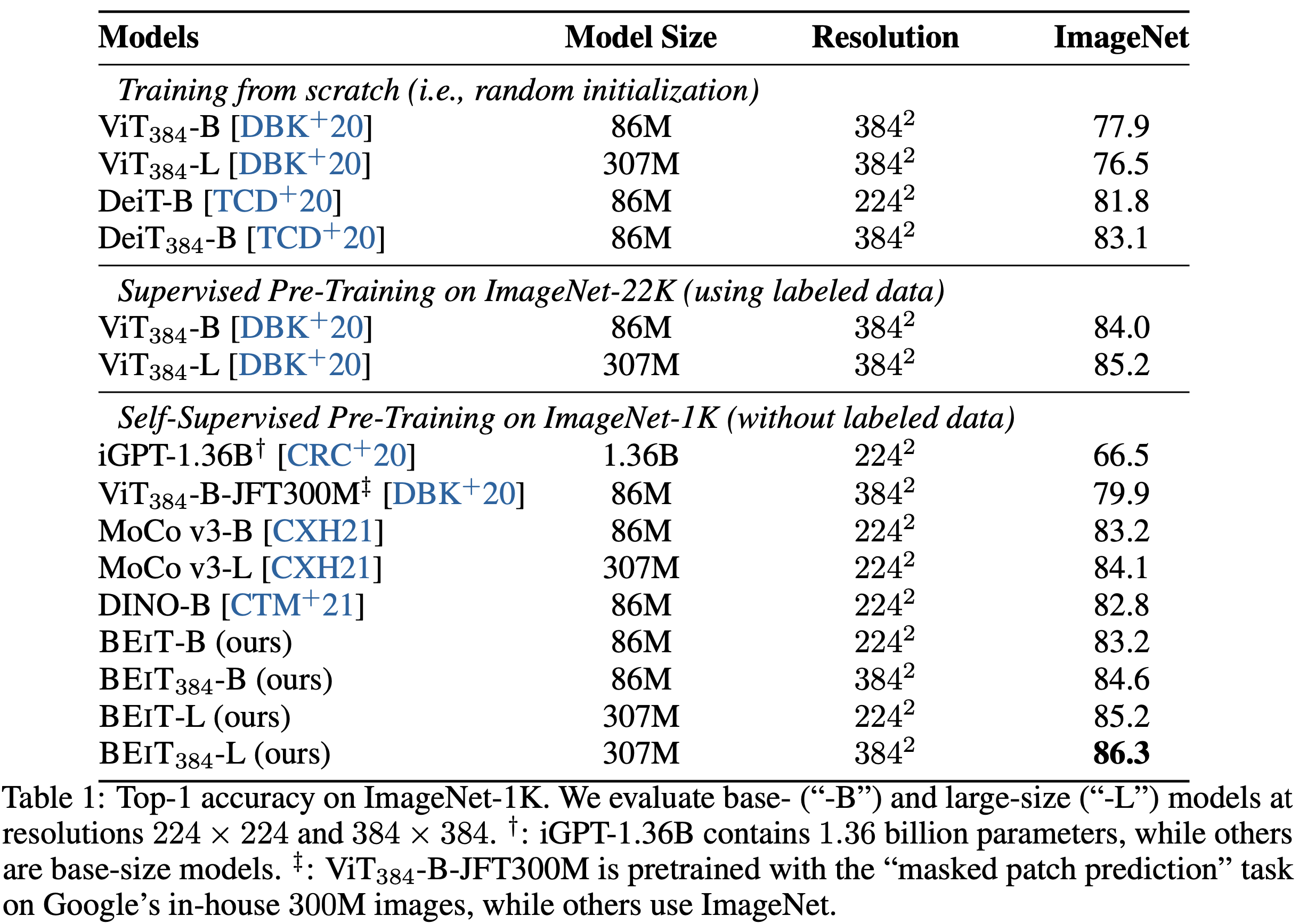
Table 1은 이미지 분류에 대한 top-1 정확도를 보고한다. BEIT를 무작위로 초기화, supervised pre-training 및 이전 self-supervised learning으로 훈련된 vision Transformer와 비교한다. 비교된 모든 모델은 기본 크기이며 iGPT는 13억 6천만 개의 파라미터를 가진다. 비교 목적으로 사전 훈련은 ImageNet에서 수행되며, ViT-JFT300M은 구굴의 3억 개 이미지에서 사전 훈련된다.
무작위 초기화로 훈련된 모델과 비교했을 때, 사전 훈련된 BEIT가 두 데이터셋 모두에서 성능을 크게 향상시킨다는 것을 발견했다. BEIT는 ImageNet에서 성능을 향상시켜 풍부한 리소스 설정에서의 효과를 보여준다.
또한, DINO 및 MoCo v3과 같은 Transformer를 위한 이전 SOTA 성능을 보여주던 self-supervised 방법과 BEIT를 비교한다. 본 연구에서 제안된 방법은 ImageNet 파인 튜닝에서 이전 모델을 능가한다. 그 중 iGPT-1.36B는 훨씬 더 많은 파라미터(즉, 13억 6천만 개 vs 8천 6백만 개)를 사용하고, ViT-JFT300M은 더 큰 코퍼스(즉, 3억 개 vs 130만 개)에서 사전 훈련되지만, 다른 모델들은 ImageNet-1K에서 ViT-Base를 사전 훈련한다. iGPT-1.36B과 ViT-JFT300M은 vision Transformer를 위한 auto-encoding 사전 훈련을 따르는 가장 비교 가능한 방법이다. 구체적으로, iGPT는 image GPT 또는 image BERT를 위해 cluster된 이미지 토큰을 input 및 output으로 사용한다. 반면에 본 논문은 원시 픽셀을 유지하기 위해 이미지 패치를 입력으로 사용하고 prediction bottleneck으로 discrete 시각적 토큰을 사용한다. ViT-JFT300은 discrete VAE가 학습한 시각적 토큰이 아닌 각 마스킹된 패치의 평균 3-bit 색상을 예측한다. 또한 부록 E에 제시된 바와 같이 BEIT와 DINO의 self-supervised task를 multi-task 학습 방식으로 사전 훈련한다.
또한, 중간 미세 조정을 사용하여 제안된 방법을 평가한다. 즉, self-supervised 방식으로 BEIT를 먼저 사전 훈련한 다음, 레이블이 있는 데이터를 사용하여 ImageNet에서 사전 훈련된 모델을 파인 튜닝한다. 결과는 BEIT가 supervised 사전 훈련과 보완적이며 ImageNet에서 중간 미세 조정 후 추가적인 이득을 얻을 수 있음을 보여준다.
Fine-tuning to 384 x 384 resolution.
해상도 224 x 224로 파인 튜닝한 후, 384 x 384 이미지에서 10 epoch 더 파인 튜닝한다. DeiT의 표준 고해상도 설정을 따르며, epoch 수는 적게 사용한다. 224 x 224 및 384 x 384 이미지에 대해 패치 크기를 동일하게 유지한다. 따라서 Transformer의 입력 시퀀스 길이는 더 높은 해상도를 위해 길어진다. Table 1은 더 높은 해상도가 ImageNet에서 BEIT 결과를 1점 이상 향상시킨다는 것을 보여준다. 더 중요한 것은, ImageNet-1K에서 사전 훈련된 BEIT 384가 동일한 입력 해상도를 사용할 때 ImageNet-22K를 사용하는 supervised 사전 훈련 ViT 384보다도 뛰어나다.
Scaling up to larger size.
BEIT를 큰 크기(즉, ViT-L과 동일)로 확장한다. Table 1에 나타난 바와 같이, ViT 384-L는 ImageNet에서 초기부터 훈련할 때 ViT 384보다 성능이 떨어진다. 결과는 vision Transformer의 데이터 부족 문제를 확인한다. ImageNet-22K에서 지도 사전 훈련은 이 문제를 부분적으로 해결하여 ViT 384-L가 결국 ViT 384보다 1.2배 더 뛰어나다. 비교적으로, BEIT-L는 BEIT보다 2배 더 뛰어나고 BEIT 384-L는 BEIT 384보다 1.7배 더 뛰어나다. 즉, BEIT를 기본에서 큰 크기로 확장하는 이점이 ImageNet-22K를 사용한 지도 사전 훈련보다 크다. 더 중요한 것은, BEIT 384와 ImageNet-22K에서 지도 사전 훈련을 수행하는 VIT 384를 비교할 때, 기본 크기(i.e.,0.6)에서 큰 크기(i.e., 1.1)로 확장할 때 BEIT의 개선이 더 커진다는 것이다. 결과는 BEIT가 매우 큰 모델(예: 10억 또는 100억)을 위해 특히 레이블 데이터가 부족한 경우에 더 도움이 될 수 있음을 시사한다.
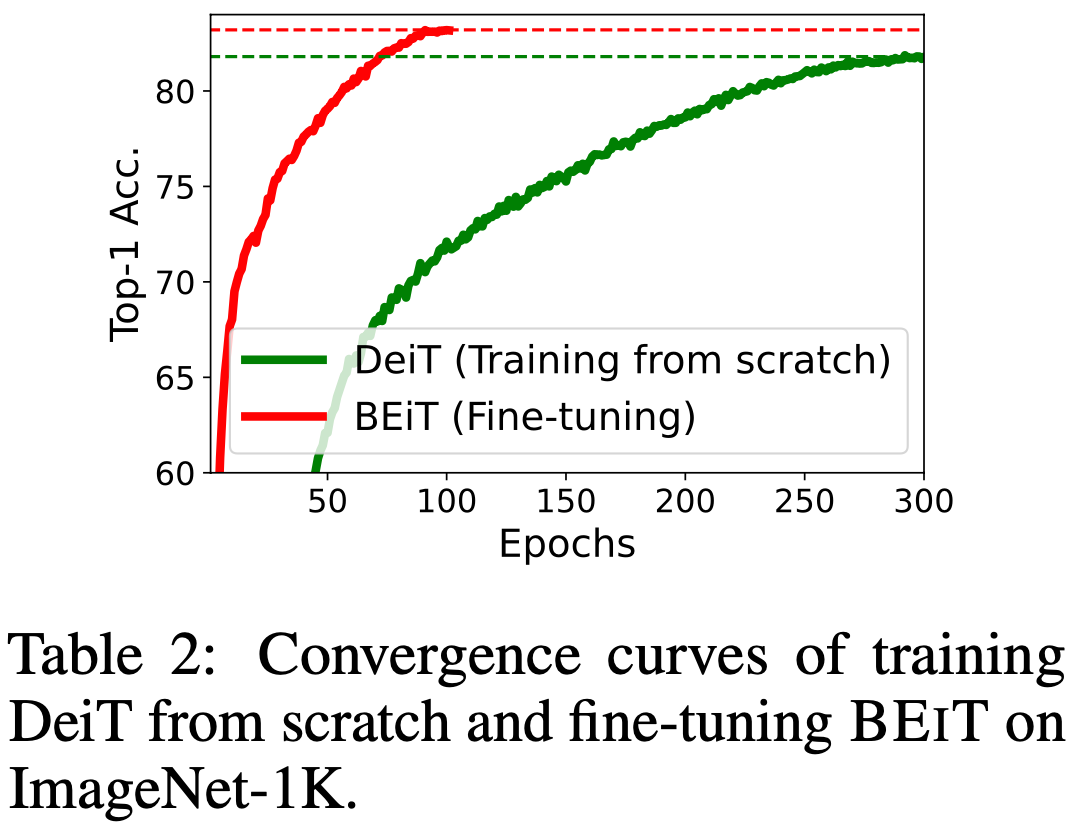
Convergence curves.
Figure 2는 초기부터 훈련하는 패러다임과 pre-training-then-fine-tuning 패러다임의 수렴 곡선을 비교한다. BEIT를 파인 튜닝하면 더 나은 성능을 달성할 뿐만 아니라 초기부터 DeiT를 훈련할 때보다 훨씬 더 빨리 수렴한다는 것을 발견했다. 게다가, BEIT를 파인 튜닝하면 매우 적은 epoch 내에 합리적인 수치를 도달할 수 있다.
3.2 Semantic Segmentation
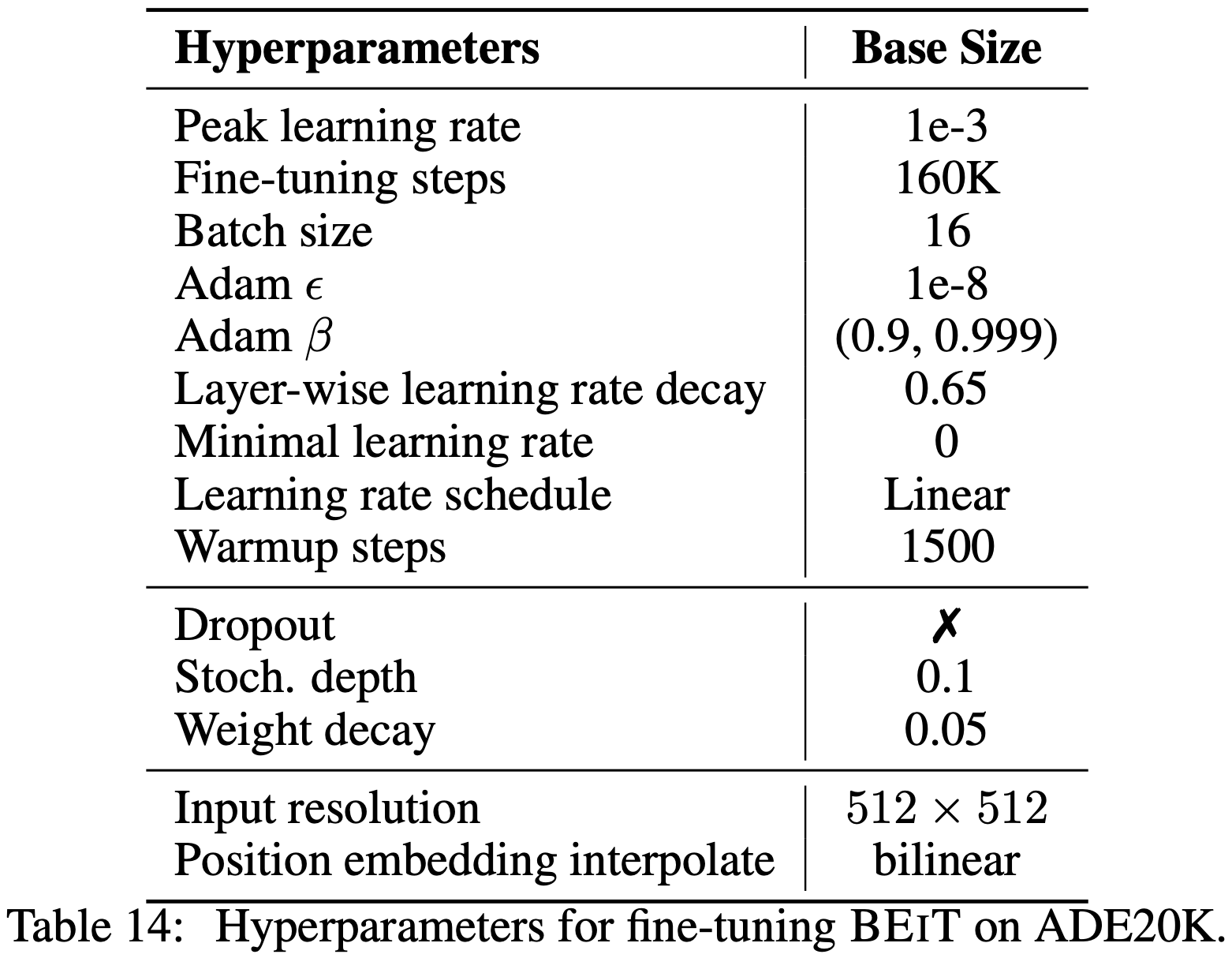
semantic segmentation은 input 이미지의 각 픽셀에 해당하는 클래스를 예측하는 것을 목표로 한다. ADE20K 벤치마크에서 BEIT를 평가하며 이 데이터셋은 25,000개의 이미지와 150개의 의미론적 범주를 포함한다. 모든 의미론적 범주에 대해 mean Intersection of Union(mIoU) 지표를 보고한다. section 2.6에서 설명한 바와 같이, SETR-PUP에서 설명된 task layer와 대부분의 하이퍼파라미터를 직접 따른다. ADE20K에서는 Adam을 최적화기로 사용한다. 학습률은 계층별 감소와 유사하게 1e-3으로 설정된다. 160,000 step동안 파인 튜닝을 수행한다. batch size는 16이다. 자세한 하이퍼파라미터는 부록 I에 설명되어 있다.
Table 3에서 알 수 있듯이, ImageNet의 레이블이 지정된 데이터를 사용하는 supervised 사전 훈련과 BEIT를 비교한다. 본 연구에서 제안된 방법이 사전 훈련을 위해 수작업 주석을 필요로 하지 않음에도 불구하고 supervised 사전 훈련보다 더 나은 성능을 달성한다는 것을 발견했다. 게다가, BEIT를 ImageNet에서 중간 파인 튜닝을하여 즉, 사전 훈련된 BEIT를 먼저 ImageNet에서 파인 튜닝한 후 ADE20K에서 모델을 다시 파인 튜닝한다. 결과는 중간 파인 튜닝이 semantic segmentation에서 BEIT를 더욱 향상시킨다는 것을 나타낸다.

3.3 Ablation Studies
BEIT의 각 구성 요소의 기여도를 분석하기 위해 ablation study를 수행한다. 모델은 이미지 분류(즉, ImageNet)와 semantic segmentation(즉, ADE20K)에서 평가된다. ablation study를 위해 사전 훈련 단계를 300 epoch으로 설정했으며 이는 이전 실험에서 사용한 총 단계의 37.5%이다.
Table 4는 다양한 모델 변형의 결과를 보고한다. 먼저, 무작위로 마스킹된 위치를 샘플링하여 블록 단위 마스킹을 소거한다. 블록 단위 마스킹은 두 task에서 특히 semantic segmentation에서 유익하다는 것을 발견했다. 둘째, 마스킹된 패치의 원시 픽셀을 예측하여 시각적 토큰의 사용을 소거한다. 즉, 사전 훈련 task가 마스킹된 패치를 복원하기 위한 픽셀 회귀 문제가 된다. 제안된 masked image modeling task는 단순한 픽셀 수준 auto-encoding보다 훨씬 뛰어나다. Table 1의 결과와 비교했을 때, ablation 결과는 두 작업 모두에서 초기부터 vision Transformer를 훈련하는 것보다 더 나쁘다. 결과는 시각적 토큰의 예측이 BEIT의 핵심 요소임을 나타낸다. 셋째, 시각적 토큰과 블록 단위 마스킹의 사용을 함께 소거한다. 블록 단위 마스킹이 단거리 의존성 문제를 완화하여 픽셀 수준 auto-encoding에도 더 도움이 된다는 것을 발견했다. 넷째, 모든 시각적 토큰을 복원하는 것은 downstream task의 성능을 해친다. 다섯째, 다른 훈련 단계와 BEIT를 비교한다. 모델을 더 오래 사전 훈련하면 downstream task의 성능이 더욱 향상될 수 있다.

3.4 Analysis of Self-Attention Map
BEIT의 self-attention 메커니즘이 전혀 수작업 주석에 의존하지 않고도 객체를 분리할 수 있음을 보여준다. 유사한 특성이 다른 연구에서도 관찰되었다. 탐사 이미지는 사전 훈련 데이터에 포함되지 않기 위해 MS COCO 코퍼스에서 가져온다.
Figure 2에서 나타난 바와 같이, 이미지 내의 다른 기준점에 대한 self-attention map을 그린다. 시각화는 마지막 layer의 query-key 곱셈을 통해 계산된 attention score에 의해 생성된다. 각 기준점에 대해 해당 패치를 쿼리로 사용하고 어떤 패치가 주의하는지 보여준다. 사전 훈련 후, BEIT는 task-specific supervision 없이 self-attention head를 사용하여 의미 영역을 구별하는 법을 배운다. 이 특성은 BEIT가 downstream task에 도움이 되는 이유를 부분적으로 나타낸다. BEIT가 습득한 이러한 지식은 특히 소규모 데이터셋에서 파인 튜닝된 모델의 일반화 능력을 향상시킬 가능성이 있다.

4. Related Work
Self-supervised visual represenation learning.
여러 해에 걸쳐 vision 모델들을 self-supervised 방식으로 사전 훈련하기 위한 다양한 방법이 소개되었다. 선구적인 연구들은 패치 순서 예측, 색상화, 회전 각도 예측과 같은 기발한 사전 과제를 설계했다. 또한 다른 연구에서는 이미지 내 일부 패치를 마스킹하고 각 마스킹된 위치에 대해 마스킹된 패치가 진짜인지 가짜인지 분류하는 방법을 제안했다. 이 방법은 Jigsaw 사전 훈련의 마스킹 버전과 유사하다. 최근 연구는 contrastive 패러다임을 따른다. 이러한 모델은 일반적으로 다양한 데이터 증강을 이미지의 다른 뷰로 간주한 다음, positive pair의 표현을 유사하게 만들고 negative pair를 멀리 떨어뜨린다. contrastive 학습에서 충분한 정보가 담긴 negative 샘플을 얻기 위해, 이러한 방법은 일반적으로 큰 메모리 뱅크나 큰 batch size에 의존한다. BYOL과 SimSiam은 표현 붕괴를 피하기 위해 다양한 기술을 사용하여 negative 샘플의 요구를 제거한다. 또 다른 방법으로는 클러스터링을 사용하여 이미지 예제를 구성하는 방법이 있다.
Self-supervised vision Transformers.
데이터 부족 문제로 인해 최근 vision Transformers 사전 훈련이 큰 주목을 받고 있다. iGPT는 먼저 RGB 픽셀을 k-means 클러스터링하여 9-bit 색상 팔레트를 만들고 클러스터링된 토큰을 사용하여 이미지를 표현한다. 그 다음 iGPT는 BERT와 GPT의 task를 사용하여 Transformers를 사전 훈련한다. 비교해보면, 제안된 방법은 픽셀 수준의 정보를 잃지 않고 이미지 패치를 입력으로 사용한다. 또한, 시각적 토큰은 클러스터링 대신 discrete VAE에 의해 얻어진다. ViT는 마스킹된 패치의 3-bit 평균 색상을 예측하는 마스킹도니 패치 예측 작업을 통해 예비 탐색을 수행한다. ViT는 픽셀 수준의 auto-encoding이 더 나쁜 성능을 보인다고 보고하지만 이는 BERT를 NLP에서 CV로 가장 직관적으로 번역한 것이다. 기계적으로 설계된 사전 훈련 task를 사용하는 대신, 제안된 모델은 discrete VAE에 의해 학습된 시각적 토큰을 활용하여 더 나은 성능을 달성할 뿐만 아니라 이론적으로도 더 잘 설명된다. 마스킹된 auto-encoding 외에도 다른 주류 연구들은 contrastive learning과 self-distillation을 사용한다. 비교해보면, BEIT는 사전 훈련 처리량(부록 E) 및 메모리 소비 측면에서 몇 배의 개선을 달성할 수 있다. 이러한 장점은 BEIT를 vision Transformers 확장에 매력적으로 만든다.
5. Conclusion
본 논문은 vision Transformer를 위한 self-supervised pre-training 프레임워크를 소개하며 이미지 분류 및 semantic segmentation과 같은 downstream task에서 강력한 파인 튜닝 결과를 달성했다. 제안된 방법이 image Transformer에 대해 BERT와 유사한 사전 훈련(즉, 마스킹된 입력으로 자동 인코딩)이 잘 작동하게 하는 데 중요함을 보여주었다. 또한, 인간이 주석을 달지 않은 데이터로 의미 영역에 대한 지식을 자동으로 획득하는 흥미로운 특성을 제시했다. 앞으로는 데이터 크기와 모델 크기 측면에서 BEIT 사전 훈련을 확장하고자 한다. 또한, 유사한 목표와 텍스트 및 이미지를 위한 공유 아키텍처를 사용하여 더 통합된 방식으로 멀티모달 사전 훈련을 수행할 예정이다.
Appendix
A. Architecture Variants of Vision Transformer
공정한 비교를 위해 실험에서 standard vision Transformer(ViT)를 사용한다. 추가적으로, LayerScale과 상대적 position bias가 downstream task에서 ViT의 성능을 향상시킨다는 것을 발견했다. ImageNet-1K에서 300 epoch 동안 base-size 모델을 사전 훈련하는 소거 연구를 위해 section 3.3과 동일한 설정을 사용한다.
Table 5에서 알 수 있듯이, LayerScale과 상대적 position bias 모두 ImageNet 분류와 ADE20K semantic segmentation 성능을 향상시킨다. 향상된 아키텍처를 BEIT+로 표시하고 부록 B의 실험에 사용한다. vanilla Transformer가 수십억 개의 파라미터로 모델을 확장할 때 가장 안정적이라는 것을 경험적으로 알게 되었기 때문에 초대형 모델에는 LayerScale을 사용하지 않는다.

B. Comparison with Large-Scale SUpervised Pre-Training
SOTA supervised pre-training과 규모 면에서 비교한다. 이전 연구와의 공정한 비교를 위해 ImageNet-1K를 사용하는 것 외에도 성능을 높이기 위해 ImageNet-22K에서 BEIT를 사전 훈련한다. 부록 A에서 설명한 아키텍처 개선(즉, LayerScale과 상대적 position bias)을 적용하며 Table 6과 Table 6에서 이를 BEIT+로 표시한다. section 2.5와 동일한 사전 훈련 설정을 따르되, ImageNet-22K에서는 150 epoch 동안 사전 훈련한다. self-supervised pre-training 후, ImageNet-22K에서 90 epoch 동안 중간 미세 조정을 수행한다. 또한, 약 7000만 개의 레이블된 이미지를 포함하는 자체 데이터셋을 ImageNet-22K의 대체로 사용한다.
Table 6은 ImageNet 파인 튜닝에서 BEIT와 이전 SOTA supervised pre-training을 비교한다. 구굴의 자체 JFT-300M 및 JFT-3B와 같은 매우 큰 규모의 레이블된 데이터에 크게 의존하는 대신, BEIT 사전 훈련이 ImageNet-22K(1400만)만으로 따라잡을 수 있음을 증명한다. 구체적으로, ImageNet-22K에서 파인 튜닝된 BEIT-L는 구글 JFT-3B에서 훈련된 ViT-L와 비슷한 성능을 달성한다. 게다가, BEIT-L는 자체 7000만 데이터셋에서 중간 미세 조정 후 ImageNet에서 89.5%의 top-1 정확도를 얻는다. 결과는 BEIT 사전 훈련이 필요한 레이블링 노력을 크게 줄이고 대형 vision Transformer의 새로운 SOTA 성능을 발전시킨다는 것을 나타낸다.
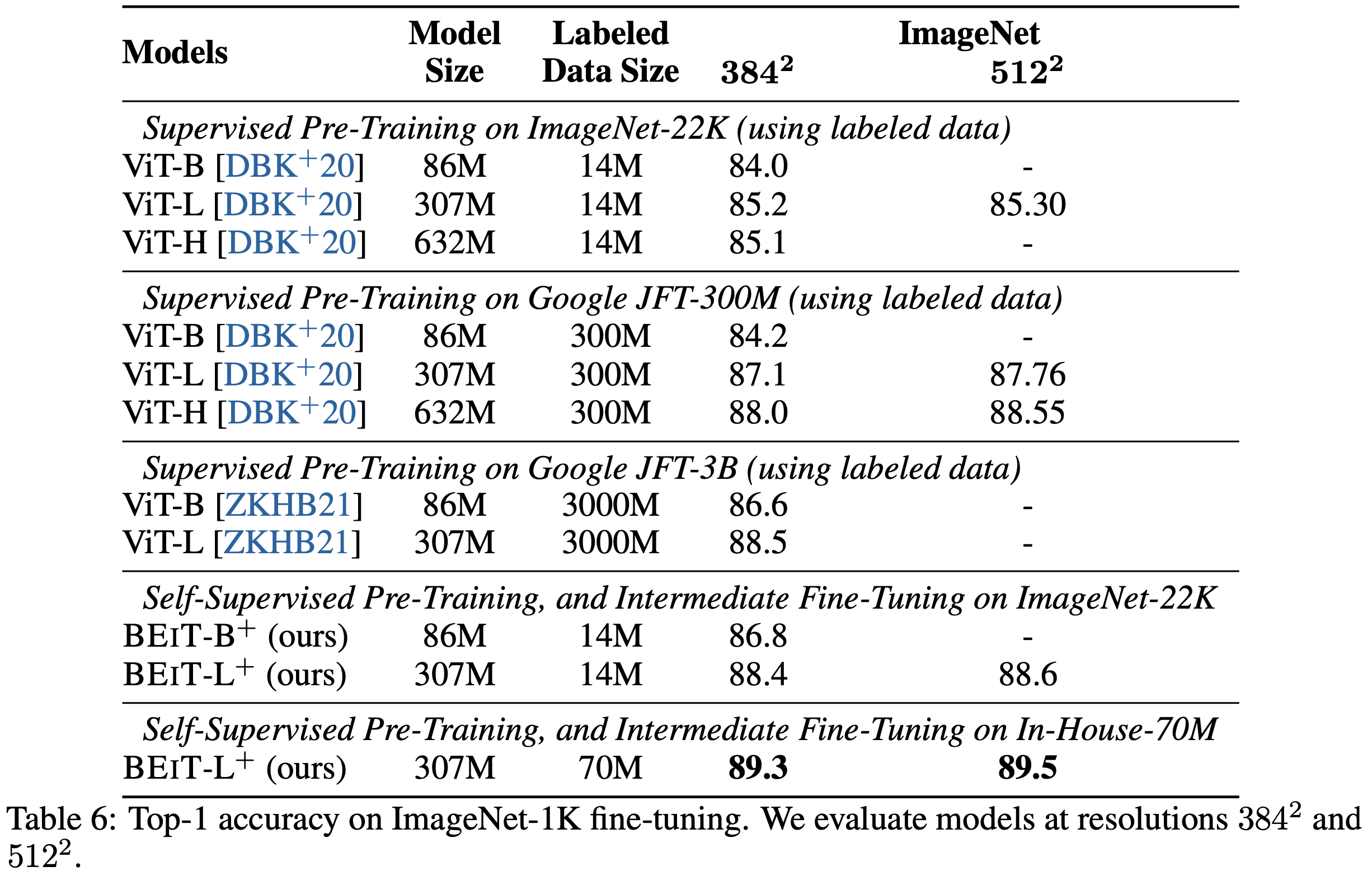
Table 7에서 볼 수 있듯이, ADE20K semantic segmentation 벤치마크에서 파인 튜닝 결과를 보고한다. Swin을 따라, 동일한 task layer(UperNet)를 사용하고 해상도 640 x 6400에서 모델을 평가한다. BEIT-L 모델은 ADE20K에서 SOTA 성능을 달성한다.

C. Ablation Studies of Image Tokenizer
비교를 위해 ImageNet-1K에서 이미지 토크나이저를 다시 훈련했다. 재구현은 https://github.com/lucidrains/DALLE-pytorch를 기반으로 한다. DALL-E에서와 동일한 8K 크기의 코드북을 사용한다. 그런 다음 토크나이저를 사전 훈련 과정에 연결한다. section 3.3의 소거 연구와 동일한 실험 설정을 따른다. Table 8은 재구현한 토크나이저가 기존의 DALL-E 토크나이저와 비교하여 유사한 재구성 손실 및 ImageNet 파인 튜닝 성능을 얻음을 보여준다.

D. Linear Probes on ImageNet
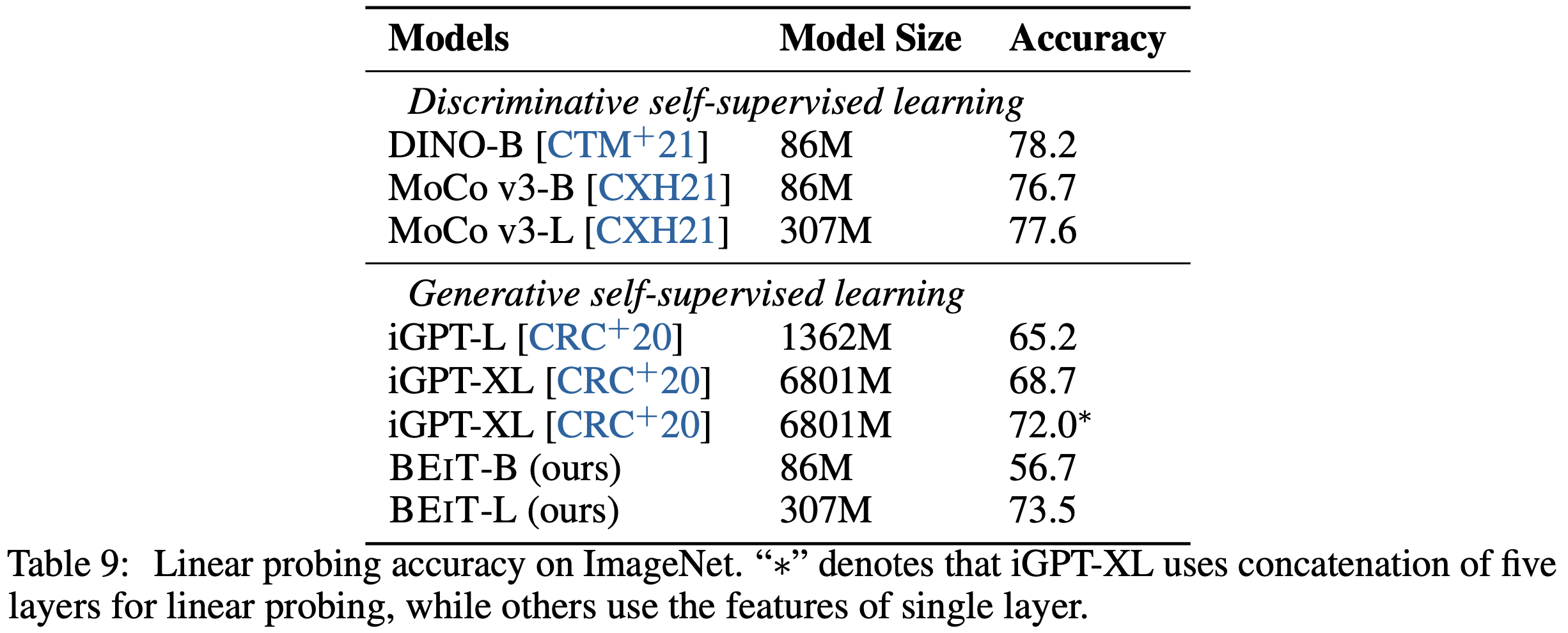
다양한 사전 훈련된 vision Transformer에 대해 ImageNet에서 linear probe를 평가한다. BEIT를 두 가지 주요 연구, 즉 discriminative 및 generative self-supervised 학습과 비교한다. 첫 번째는 contrastive 학습과 self distillation과 같은 판별 학습을 사전 훈련에 적용한다. 위의 방법들은 일반적으로 이미지 수준의 특징을 전역 벡터로 집계하는 법을 배우며, 이는 linear probing에 비교적 적합하다. 반면에 iGPT와 본 논문 방법과 같은 두 번째 작업은 일반적으로 이러한 전역 특징 집계를 사전 훈련하지 않아 linear probing을 어렵게 만든다.
iGPT를 따라, 각 이미지 패치의 hidden state를 집계하기 위해 평균 풀링을 사용하고 항상 final layer가 아닌 중간 layer에 probing layer를 추가한다. 유사하게, BEIT-B의 경우 9번째 layer, BEIT-L의 경우 14번째 layer가 최적의 layer임을 발견했다. 구체적으로, AdamW를 사용하여 50 epoch 동안 linear probe layer를 업데이트한다. 학습률은 cosine decay와 함께 4e-3으로 설정된다. batch size는 1024이고 weight decay는 1e-4로 설정된다. DINO에서 사용된 데이터 증강을 따르며, 훈련 중 무작위 크기 조정 자르기와 수평 뒤집기 증강을 사용하고 중앙 자르기로 평가한다.
Table 9에 나타난 바와 같이, self-supervised learning을 위해 ImageNet-1K에서 linear probe를 평가한다. 전반적으로, discriminative 방법이 generative 사전 훈련보다 linear probing에서 더 나은 성능을 발휘한다. linear probe는 Transformer 파라미터를 고정하고 linear layer만 업데이트한다. 따라서 이미지 수준 특징의 전역 집계를 사전 훈련하는 것이 DINO와 MoCo v3에서 linear probing에 유리하지만, 완전한 파인 튜닝은 격차를 제거한다. 또한, 결과는 기본(86M)에서 큰(304M) 크기로 모델 크기를 늘리면 제안된 방법의 정확도가 크게 향상됨을 나타낸다. 반면, MoCo v3의 기본 크기와 큰 크기 간의 차이는 더 작다. 또한 BEIT가 훨씬 적은 파라미터를 사용하면서도 iGPT를 크게 능가함을 발견했다.
E. Multi-Task Pre-Training with DINO
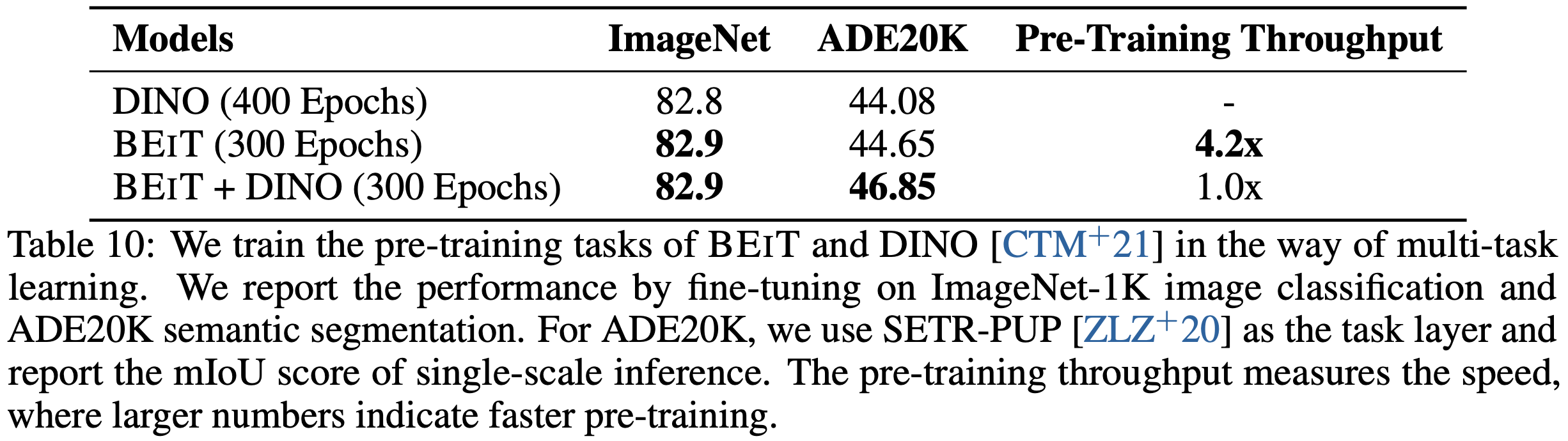
BEIT와 DINO의 pre-training task를 multi-task 방식으로 함께 훈련한다. Table 10에 나타난 바와 같이, masked image modeling을 DINO와 결합하면 ADE20K에서 semantic segmentation이 향상되고 ImageNet 분류에서는 유사한 결과를 얻는다. 게다가, BEIT는 사전 훈련 속도 측면에서 더 효율적인데, 이는 DINO self-distillation과 multi-crop 증강을 위해 Transformer 파라미터의 두 복사본을 사용하기 때문이다. BEIT와 BEIT+DINO 간의 처리량 비교를 위해 batch size를 동일하게 설정했다. BEIT는 또한 메모리 효율성이 더 높기 때문에 더 큰 배치 크기를 사용하여 GPU 카드를 완전히 활용할 수 있으며 이는 실제로 보고된 숫자보다 더 큰 속도 향상을 얻을 수 있다.
F. Image Classification on CIFAR-100
ImageNet 분류 외에도 100개의 클래스와 60,000개의 이미지를 가진 CIFAR-100 벤치마크에서 파인 튜닝 실험을 수행한다. 실험 설정은 section 3.1과 동일하다.
Table 11은 CIFAR-100에서의 top-1 정확도를 보고한다. 특히, 더 작은 CIFAR-100 데이터셋에서는 처음부터 훈련된 ViT가 48.5%의 정확도에만 도달한다. 이에 비해, BEIT는 사전 훈련의 도움으로 90.1%를 달성한다. 결과는 BEIT가 주석 작업의 필요성을 크게 줄일 수 있음을 나타낸다. BEIT는 또한 MoCo v3을 능가한다. 게다가, ImageNet-1K에서의 중간 미세 조정은 CIFAR-100에서의 결과를 더욱 향상시킨다.

G. Hyperparameters for Pre-Training

H. Hyperparameters for Image Classification Fine-Tuning
I. Hyperparameters for ADE20K Semantic Segmentation Fine-Tuning