본 글은 https://arxiv.org/abs/2102.12092 내용을 기반으로 합니다.
혹시 잘못된 부분이나 수정할 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
Abstract
text-to-image 생성은 전통적으로 고정된 데이터셋으로 학습할 때 더 나은 모델링을 찾는 것에 중점을 둔다. 이러한 가정은 복잡한 아키텍처, auxiliary loss, 또는 학습 중에 제공되는 객체 부분 레이블이나 segmentation mask와 같은 부가 정보를 포함할 수 있다. 텍스트와 이미지 토큰을 single stream of data로 autoregressive하게 모델링하는 transformer에 기반한 간단한 접근 방식을 설명한다. 충분한 데이터와 규모가 주어지면, 본 연구의 접근 방식은 zero-shot 방식으로 평가할 때 이전의 domain 특화 모델들과 경쟁할 수 있다.
* single stream of data : 데이터를 일련의 연속적인 토큰으로 취급하여 하나의 흐름으로 처리하는 방식. 즉, 텍스트와 이미지 데이터를 별도로 구분하지 않고 모두 동일한 방식으로 취급하여 하나의 연속적인 시퀀스로 모델링하는 것.
1. Introduction
텍스트에서 이미지로 변환하는 현대 machine learning 접근 방식은 Mansimov et al. (2015) 연구에서 시작되었다. 이들은 DRAW Gregor et al. (2015) 생성 모델을 이미지 캡션 조건으로 확장할 경우 새로운 시각적 장면을 생성할 수 있음을 보여주었다. 이후 Reed et al. (2016b)는 recurrent variational auto-encoder 대신 generative adversarial network (GAN)를 사용하면 이미지 품질이 향상된다는 것을 증명하였다. Reed et al. (2016b)는 이 시스템이 인식 가능한 속성을 가진 객체를 생성할 뿐만 아니라 학습되지 않은 카테고리에도 zero-shot 일반화를 할 수 있음을 보여주었다.
지난 몇 년동안, 이러한 방법들에 대한 결합을 통해 발전이 계속되어왔다. 여기에는 multi-scale generator와 같은 수정사항을 통해 생성 모델 아키텍처를 개선하고 attention과 auxiliary loss를 통합하며 텍스트 외의 추가적인 조건 정보 출처를 활용하는 것들이 포함된다.
별도로, Nguyen et al. (2017)은 현대적인 방법들에 비해 샘플 품질에서 큰 향상을 가져온 조건부 이미지 생성에 대한 에너지 기반 프레임워크를 제안했다. 이들의 접근법은 사전 학습된 판별 모델을 통합할 수 있으며, MS-COCO에서 사전학습된 captioning 모델에 적용할 때 test-to-image 생성을 수행할 수 있음을 보여주었다. 최근에 Cho et al. (2020) 또한 사전 학습된 cross-modal masked language model에 input을 최적화하는 방법을 제안했다. Mansimov et al. (2015) 이후의 연구 결과로 시각적 품질이 크게 향상되었지만, 샘플은 여전히 객체 왜곡, 비논리적인 객체 배치, 전경과 배경 요소의 부자연스러운 혼합과 같은 심각한 결함이 발생할 수 있다.
최근 대규모 생성 모델에 의해 촉진된 발전은 추가적인 개선을 위한 가능한 경로를 시사한다. 구체적으로, 계산 능력, 모델 크기 및 데이터가 확장될 때, autoregressive transformer는 text, image, audio 등 여러 도메인에서 인상적인 결과를 달성했다.
이에 비해, text-to-image 생성은 주로 MS-COCO 및 CUB-200과 같은 비교적 작은 데이터셋에서 평가되었다. 데이터셋 크기와 모델 크기가 현재 접근 방식의 제한 요인일 수 있을까? 이 연구에서는 인터넷에서 수집한 2억 5천만 쌍의 image-text 쌍을 사용하여 120억개의 파라미터의 autoregressive transformer를 훈련시키는 것이 자연어를 통해 제어 가능한 유연하고 high fidelity의 이미지 생성 모델을 만들어낸다는 것을 보여준다.
* high fidelity : "높은 충실도"라는 뜻으로 생성한 이미지가 품질 면에서 매우 우수하고 시각적으로 자연스러우며 현실적이라는 뜻.
결과는 인기 있는 MS-COCO 데이터셋에서 zero-shot으로 높은 품질의 이미지 생성을 달성하며 training label을 전혀 사용하지 않는다. 인간 평가자들의 90%가 이 데이터셋에서 훈련된 이전 연구보다 이 시스템을 선호했다. 또한 이 시스템은 image-to-image와 같은 복잡한 task를 기본 수준에서 수행할 수 있음을 발견했다. 이는 이전에 맞춤형 접근 방식이 필요했던 작업이었지만, 이제는 단일 대규모 생성 모델의 기능으로 나타나고 있다.
2. Method
본 연구의 목표는 transformer를 훈련시켜 텍스트와 이미지 토큰을 single stream of data로 autoregressive하게 모델링하는 것이다. 그러나 이미지 토큰으로 픽셀을 직접 사용하는 것은 고해상도 이미지의 경우 과도한 메모리를 필요로 한다. likelihood objective는 픽셀 간의 단거리 의존성을 모델링하는 데 우선 순위를 두는 경향이 있어, 많은 모델링 용량이 객체를 시각적으로 인식할 수 있게 하는 low-frequency 구조 대신 high-frequency 세부 사항을 캡처하는 데 사용될 것이다.
* low-frequency : 큰 구조적인 요소로 이미지의 전반적인 형태와 구조를 결정짓는 중요한 정보들을 포함. 이러한 요소들은 이미지에서 큰 특징을 구별하는 데 중요.
* high-frequency : 이미지의 세부 사항과 디테일을 구성. 이미지 전체의 큰 구조보다는 작은 차이를 강조.
이러한 문제를 해결하기 위해 (Oord et al., 2017; Razavi et al., 2019)와 유사한 two-stage 훈련 절차를 사용한다.
- Stage 1. 각 256 x 256 RGB 이미지를 8192개의 가능한 값을 가질 수 있는 이미지 토큰의 32 x 32 grid로 압축하기 위해 discrete variational autoencoder(dVAE)를 훈련시킨다. 이는 시각적 품질의 큰 저하 없이 transformer의 문맥 크기를 192배 줄인다(Figure 1 참조).
- Stage 2. 최대 256개의 BPE로 인코딩된 텍스트 토큰을 32 x 32 = 1024개의 이미지 토큰과 연결하고 텍스트와 이미지 토큰의 joint distribution을 모델링하도록 autoregressive transformer를 훈련시킨다.
* discrete variational autoencoder (dVAE) : variational autoencoder (VAE)의 한 종류로 이산적인 잠재 공간을 사용하는 변형된 버전. VAE는 이미지나 텍스트 같은 데이터를 저차원 잠재 공간(latent space)에 압축하고 이를 다시 원래의 데이터 형태로 복원하는 신경망 모델. 일반적인 VAE는 연속적인 잠재 벡터를 사용하여 데이터를 인코딩하는 반면, dVAE는 이산적인 잠재 벡터, 즉 코드북에서 선택된 특정 벡터를 사용. 이는 데이터를 고정된 개수의 코드(토큰)로 변환.
* joint distribution : 두 개 이상의 변수들이 동시에 발생할 확률을 나타내는 분포. 특정 텍스트와 해당 이미지가 함께 나타날 확률을 모델링한다는 의미. 이를 통해 텍스트와 이미지 간의 상호 의존성을 학습
* autoregressive transformer : 데이터를 순차적으로 생성하는 모델로, 이전에 생성된 데이터를 기반으로 다음 데이터를 예측. 텍스트와 이미지 토큰의 결합된 시퀀스를 하나씩 생성하며, 각 단계에서 이전에 생성된 토큰을 바탕으로 다음 토큰을 예측. 이를 통해 텍스트와 이미지의 관계를 학습하고 자연스러운 텍스트와 일치하는 이미지를 생성.

전반적인 절차는 모델 분포가 이미지 x, 캡션 y 및 인코딩된 RGB 이미지의 토큰 z에 대해 갖는 joint likelihood에 대한 evidence lower bound (ELB)를 최대화하는 것으로 볼 수 있다. 이 분포를 다음과 같이 분해하여 모델링한다.
* evidence lower bound (ELB) : 주어진 데이터에 대한 잠재 변수 모델을 최적화하기 위해 도입된 하한값. 이는 VAE와 같은 모델의 학습 과정에서 사용되며 ELB는 모델의 log-likelihood를 근사하고 이를 최대화하는 방향으로 모델을 학습.
이는 다음과 같은 하한을 제공한다.
- q는 RGB 이미지 x가 주어졌을 때, dVAE 인코더에 의해 생성된 32 x 32 이미지 토큰 분포를 나타낸다.
- p세타는 이미지 토큰이 주어졌을 때 dVAE 디코더에 의해 생성된 RGB 이미지 분포를 나타낸다.
- p는 트랜스포머에 의해 모델링된 텍스트와 이미지 토큰에 대한 joint distribution을 나타낸다.
이 하한은 베타가 1인 경우에만 성립하지만, 실제로는 더 큰 값을 사용하는 것이 도움이 됨을 발견했다. 다음 subsection에서는 두 단계를 더 자세히 설명한다.
2.1 Stage One: Learning the Visual Codebook
training 첫 번째 단계에서 ELB를 최대화하여 이미지만을 사용하여 dVAE를 훈련시킨다. 초기 사전 분포 p는 K = 8192개의 codebook vector에 대한 균일한 범주 분포로 설정하고 q는 인코더가 출력하는 32 x 32 grid의 동일한 공간 위치에 있는 8192개의 logit에 의해 파라미터화된 범주 분포로 설정한다.
이제 ELB는 최적화하기 어려워진다. q가 이산 분포이기 때문에 reparameterization gradient를 사용하여 이를 최대화할 수 없다. Oord et al. (2017) 및 Razavi et al. (2019)는 온라인 클러스터 할당 절차와 straight-through estimator를 결합하여 이 문제를 해결했다. 본 논문은 대신 gumbel-softmax 완화를 사용하여 q에 대한 기대를 q세타에 대한 기대로 대체한다. 여기서 타우가 0에 가까워질수록 완화는 엄밀해진다. p세타에 대한 likelihood는 log-laplace distribution을 사용하여 평가된다(유도 과정은 Appendix A.3을 참조).
이완된 ELB는 지수적으로 가중된 반복 평균을 사용하는 Adam을 통해 최대화된다. Appendix A.2에는 하이퍼파라미터에 대한 완전한 설명이 있지만, 안정적인 훈련을 위해 다음 사항들이 특히 중요하다는 것을 발견했다.
- 이완 온도와 스텝 크기에 대한 특정 annealing schedule : 타우를 1/16까지 annealing하는 것이 q세타타우 대신 q세타로 이완된 검증 ELB와 실제 검증 ELB 간의 격차를 해소하는 데 충분하다는 것을 발견했다.
- 인코더의 끝 부분과 디코더의 시작 부분에서 1 x 1 컨볼루션을 사용. 이완 주위의 컨볼루션 수용 영역 크기를 줄이는 것이 실제 ELB로 일반화하는 데 더 좋다는 것을 발견했다.
- 초기화 시 안정적인 훈련을 보장하기 위해 인코더와 디코더의 resblock에서 나오는 활성화값에 작은 상수를 곱한다.
* annealing schedule : 훈련 과정에서 특정 매개변수(이완 온도와 스텝 크기)의 값을 점진적으로 조정하는 방법.
* exponentially weighted iterate averaging 지수 가중 평균 : 학습 과정에서 매 반복마다 가중 평균을 계산하여 최적화하는 방법.
또한 KL 가중치를 베타 = 6.6으로 증가시키는 것이 더 나은 코드북 사용을 촉진하고 궁극적으로 훈련 종료 시 더 작은 재구성 오류로 이어진다는 것을 발견했다.
2.2 Stage Two: Learning the Prior
두 번째 단계에서는 파이와 세타를 고정하고 프사이에 대해 ELB를 최대화하여 텍스트와 이미지 토큰에 대한 사전 분포를 학습한다. 여기서 p프사이는 120억 개의 매개변수를 가진 sparse transformer로 표현된다.
text-image 쌍이 주어지면, 소문자로 변환된 캡션을 BPE로 최대 256개의 토큰으로 인코딩하며 어휘 크기는 16,384이다. 이미지는 32 x 32 = 1024개의 토큰으로 인코딩하며 어휘 크기는 8192이다. 이미지 토큰은 dVAE 인코더 logit에서 argmax sampling을 사용하여 얻으며, 여기에는 어떤 gumbel 노이즈도 추가되지 않는다. 마지막으로, 텍스트와 이미지 토큰을 연결하여 single stream data로 autoregressive하게 모델링한다.
transformer는 디코더 전용 모델로, 각 이미지 토큰은 64개의 self-attention layer 중 어느 하나에서도 모든 텍스트 토큰에 attend할 수 있다. 전체 아키텍처는 Appendix B.1에 설명되어 있다. 모델에서 사용되는 self-attention mask에는 세 가지 종류가 있다. text-to-text attention에 해당하는 부분은 standard causal mask를 사용하고 image-to-image attention에 해당하는 부분은 row, column, or convolutional attention mask를 사용한다.
* argmax sampling : 주어진 확률 분포에서 가장 높은 확률을 가진 값을 선택하는 방법.
* causal mask : 시퀀스 데이터에서 현재 토큰 이후의 토큰들을 참조하지 않도록 하는 마스킹 기법.
* row, column, or convolutional attention mask : 이미지 데이터를 처리할 때, 행, 열, 또는 지역적인 패턴을 중심으로 주의를 기울이는 마스킹 기법.
텍스트 캡션의 길이는 256개의 토큰으로 제한하지만, 마지막 텍스트 토큰과 이미지 시작 토큰 사이의 "padding" 위치에 대해 어떻게 처리할지는 명확하지 않다. 하나의 옵션은 self-attention 연산에서 이러한 토큰들의 로짓을 -무한으로 설정하는 것이다. 대신, 본 논문은 256개의 텍스트 위치 각각에 대해 별도의 특수 패딩 토큰을 학습하는 방법을 선택했다. 이 토큰은 텍스트 토큰이 없을 때만 사용된다. Conceptual Captions에 대한 초기 실험에서 이는 검증 손실을 높였지만 out-of-distribution caption에 대해서는 더 나은 성능을 보였다.
텍스트와 이미지 토큰에 대한 cross-entropy loss는 데이터 배치에서 각 종류의 총 수로 정규화한다. 주로 이미지 모델링에 관심이 있기 때문에, 텍스트의 cross-entropy loss에 1/8을 곱하고 이미지의 cross-entropy loss에 7/8을 곱한다. 이 목표는 지수 가중 평균을 사용하는 Adam으로 최적화되며 훈련 절차에 대한 자세한 설명은 Appendix B.2에 나와 있다. 약 606,000개의 이미지를 검증용으로 예약했고 수렴시 과적합의 징후는 발견되지 않았다.
2.3 Data Collection
최대 12억 개의 파라미터를 가진 모델에 대한 초기 실험은 MS-COCO를 확장한 데이터셋인 Conceptual Captions에서 수행되었다. 이 데이터셋은 330만 쌍의 text-image pair로 구성되어 있다.
12억 개의 파라미터로 확장하기 위해, JFT-300M과 유사한 규모의 데이터셋을 만들기 위해 인터넷에서 2억 5천만 쌍의 text-image pair를 수집했다. 이 데이터셋은 MS-COCO는 포함되지 않지만, Conceptual Captions와 YFCC100M의 필터링된 하위 집합이 포함되어 있다. MS-COCO는 YFCC100M에서 생성되었기 때문에, 본 연구의 훈련 데이터에는 MS-COCO 검증 이미지의 일부가 포함되어 있지만, 캡션은 포함되지 않았다. section 3에서 제시된 정량적 결과에서 이를 통제하였고 결과에 유의미한 영향을 미치지 않았음을 발견했다. 데이터 수집 과정에 대한 자세한 내용은 Appendix C에서 제공한다.
2.4 Mixed-Precision Training
GPU 메모리를 절약하고 처리량을 증가시키기 위해 대부분의 파라미터, Adam moment, 활성화 값을 16-bit 정밀도로 저장한다. 또한 activation checkpointing을 사용하여 역전파 과정에서 resblock 내의 활성화 값을 재계산한다. 10억 개 이상의 파라미터를 가진 모델을 16-bit 정밀도로 훈련하면서 발산하지 않도록 하는 것이 이 프로젝트에서 가장 어려운 부분이었다.
* mixed-precision training : 훈련 속도를 높이고 메모리 사용을 줄이기 위해 16-bit와 32-bit 정밀도를 혼합하여 사용하는 기법.
* activation checkpointing : 메모리를 절약하기 위해 순전파 시 활성화값을 저장하지 않고, 필요할 때 다시 계산하는 방법.
이러한 불안정성의 근본 원인이 16-bit gradient의 underflow라고 믿는다. Appendix D에는 대규모 생성 모델을 훈련할 때 underflow를 방지하기 위해 개발한 일련의 지침이 나와 있다. 여기서는 이러한 지침 중 하나인 per-resblock gradient scaling을 설명한다.
* underflow : 매우 작은 수가 컴퓨터가 표현할 수 있는 최소값보다 작아져 0으로 반올림되는 현상.
* per-resblock gradient scaling : 각 resblock의 gradient를 개별적으로 scaling하여 underflow를 방지하는 기법.
이전 연구 Liu et al., (2020)과 유사하게, 초기 resblock에서 후반 resblock으로 이동할수록 activation gradient의 norm이 단조롭게 감소하는 것을 발견했다. 모델이 더 깊고 넓어질수록 후반 resblock의 activation gradient의 실제 지수는 16-bit 형식의 최소 지수보다 낮아질 수 있다. 결과적으로, 이는 0으로 반올림되는 underflow 현상을 초래한다. underflow를 제거하면 안정적인 훈련을 통해 수렴할 수 있음을 발견했다.
* norm : 벡터의 크기를 나타내는 수치. gradient의 크기를 측정하는 데 사용.
standard loss scaling은 가장 작은 activation gradient와 가장 큰 activation gradient(절대값 기준)의 범위가 16-bit 형식의 지수 범위 내에 맞을 때 underflow를 피할 수 있다. NVIDIA V100 GPU에서는 이 지수 범위가 5-bit로 지정된다. 이는 동일한 크기의 기본 언어 모델을 훈련하는 데는 충분하지만, text-image 모델에는 범위가 너무 작다는 것을 발견했다.
* loss scaling : 작은 gradient 값이 underflow되는 것을 방지하기 위해 loss 값을 scaling하는 방법.
본 연구에서 제안한 해결책은 각 resblock에 대해 별도의 "gradient scale"을 사용하는 것이다. 이는 mixed-precision training을 위한 보다 일반적인 프레임워크인 Flexpoint의 실용적인 대안으로 볼 수 있으며 특수한 GPU 커널을 필요로 하지 않는 장점이 있다. 본 연구에서 Sun et al. (2020)이 4-bit 정밀도로 컨볼루션 네트워크를 훈련시키기 위해 유사한 절차를 독립적으로 개발했다는 것을 발견했다.
* Flexpoint : mixed-precision 훈련을 위한 일반적인 프레임워크로 다양한 정밀도를 효율적으로 사용할 수 있도록 설계됨.
2.5 Distributed Optimization
120억 개의 파라미터를 가진 모델은 16-bit 정밀도로 저장할 때 약 24GB의 메모리를 소비하며, 이는 16GB NVIDIA V100 GPU의 메모리를 초과한다. 본 연구는 parameter sharding을 사용하여 이 문제를 해결한다. Figure 5에서 볼 수 있듯이, parameter sharding을 통해 compute-intensive operation과 동시에 기기 내 통신의 지연 시간을 거의 완전히 숨길 수 있다.
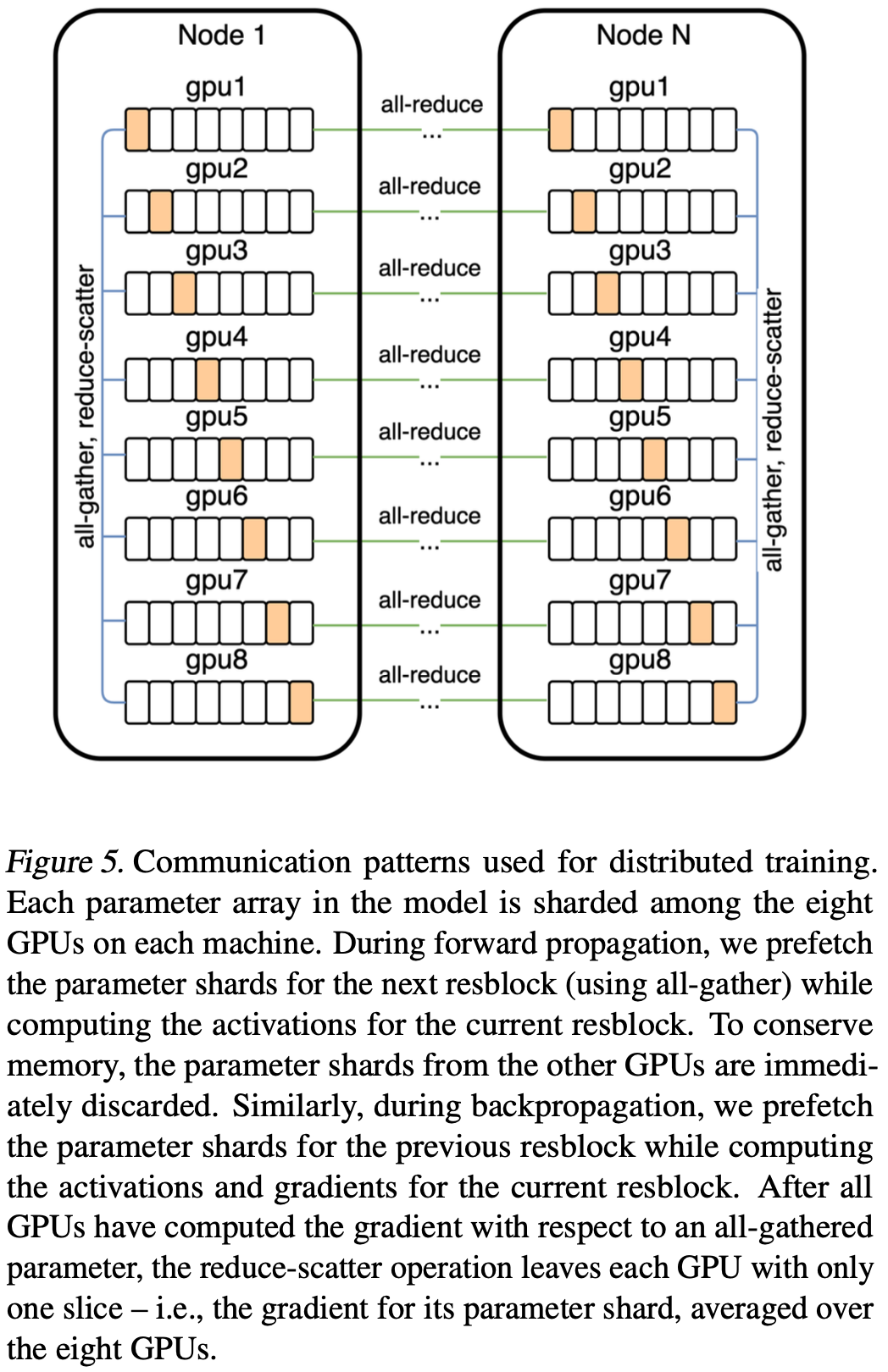
* parameter sharding : 모델의 파라미터를 여러 GPU에 나누어 저장하고 처리하는 기술로 메모리 사용량을 줄이고 병렬 처리를 향상.
* compute-intensive operation : 많은 계산 자원을 필요로 하는 작업을 의미.
모델을 훈련시키는 클러스터에서는 기기 간 대역폭이 같은 기기 내 GPU 간 대역폭보다 훨씬 낮다. 이는 기기 간 gradient를 평균화하는 작업(all-reduce)의 비용이 훈련 중 주요 병목이 된다는 것을 의미한다. PowerSGD를 사용하여 gradient를 압축함으로써 이 비용을 크게 줄일 수 있다.
* gradient 평균화 (all-reduce) : 분산된 여러 기기에서 계산된 gradient를 평균화하여 동기화하는 작업.
* PowerSGD : 고차원 gradient를 저차원으로 압축하여 통신 비용을 줄이는 기술.
본 연구의 구현에서, 각 기기 내의 각 GPU는 이웃 GPU와 독립적으로 parameter shard gradient에 대한 low-rank factor를 계산한다. low-rank factor가 계산되면, 각 기기는 자신의 error buffer를 8개의 GPU에서 평균화된 비압축 gradient(reduce-scatter에서 얻음)와 low-rank factor로부터 얻은 비압축 gradient 사이의 잔차로 설정한다.
* low-rank factor : 고차원 행렬을 더 작은 저차원 행렬로 근사화한 것.
* reduce-scatter : 여러 기기에서 데이터를 모으고 분산시키는 통신 패턴.
PowerSGD는 압축되지 않은 parameter gradient에 대한 대규모 통신 작업을 low-rank factor에 대한 두 개의 훨씬 작은 통신 작업으로 대체한다. 주어진 압축 rank r과 transformer activation size dmodel에 대해 압축률은 1 - 5r / (8dmodel)로 계산된다(Appendix E.1 참조). Table 1은 모델 크기와 관계없이 약 85%의 압축률을 달성할 수 있음을 보여준다.
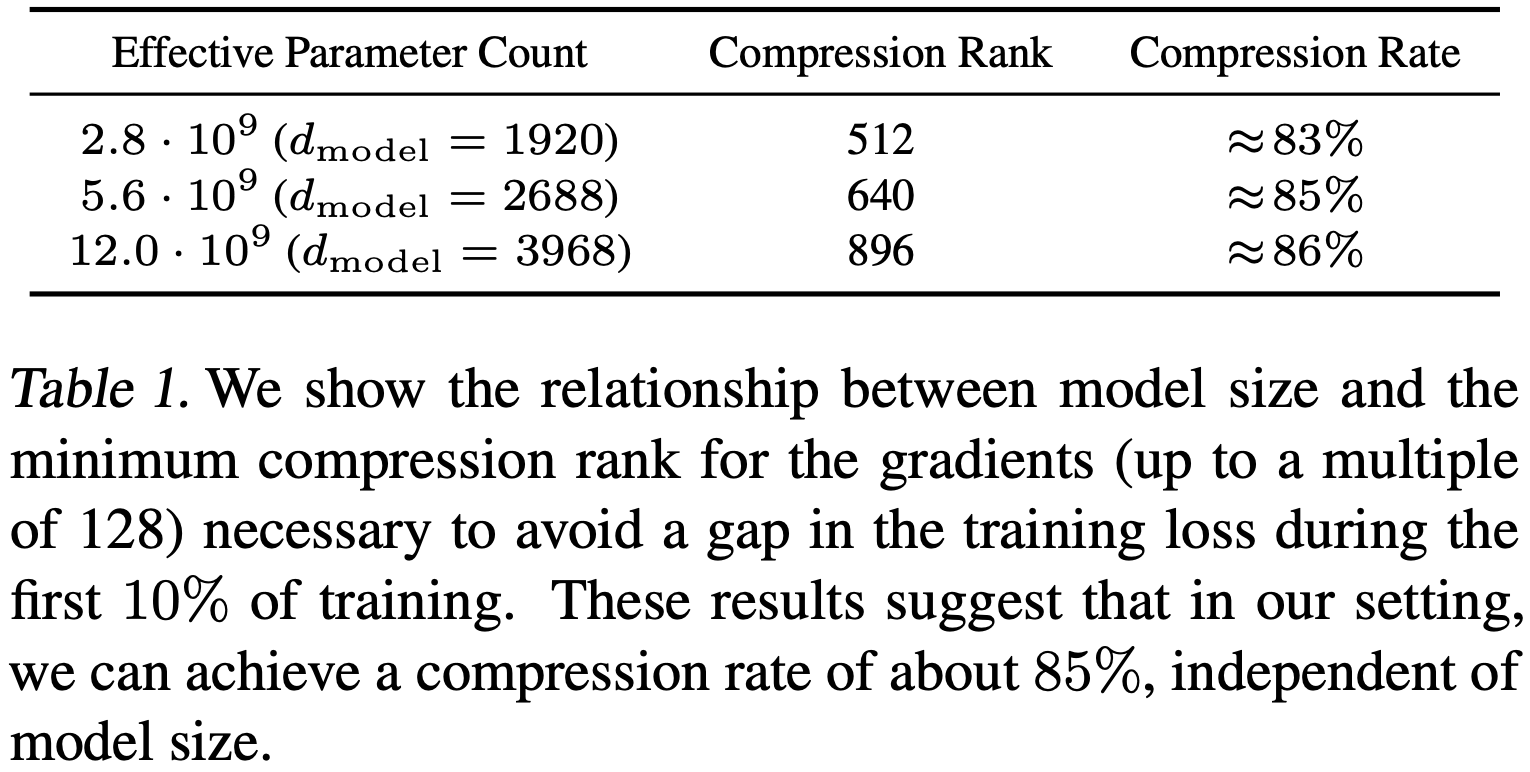
Appendix E.2에서는 PowerSGD를 대규모로 잘 작동시키기 위해 필요한 다양한 세부 사항을 설명한다. 여기에는 이런 것들이 포함된다.
- backpropagation 과정에서 gradient를 error buffer에 누적시켜 별도의 buffer를 할당하는 대신 메모리를 절약한다.
- mixed-precision backpropagation 중에 발생하는 비유한 값으로 인해 또는 checkpoint에서 훈련을 재개할 때 error buffer를 0으로 초기화하는 사례를 최소화한다.
- Gram-Schmidt 대신 Householder 직교화를 사용하고 입력에 소량의 단위 행렬을 추가하여 수치적 안정성을 향상시킨다.
- error buffer, low-rank factor 및 이와 관련된 all-reduce 통신 작업에 대해 맞춤형 16-bit 부동 소수점 형식을 사용하여 underflow를 방지한다.
* buffer : 데이터를 임시로 저장하는 메모리 공간을 의미.
* error buffer : gradient 업데이트 시 발생하는 오차를 누적시키는 buffer.
* Householder 직교화 : 수치적 안정성을 위해 사용되는 직교화 방법.
* Gram-Schmidt : 또 다른 직교화 방법으로, Householder 직교화보다 덜 안정적.
또한 Vogels et al. (2019)에서 설명한 Q 행렬에 대한 warm-start 절차가 불필요하다는 것을 발견했다. 훈련 시작 시 Q를 랜덤 가우시안 행렬로 고정하고 절대 업데이트하지 않음으로써 동등한 결과를 얻을 수 있었다.
2.6 Sample Generation
Razavi et al. (2019)와 유사하게, 사전 학습된 contrastive 모델(Radford et al., 2021)을 사용하여 transformer에서 생성된 샘플을 재정렬한다. 캡션과 후보 이미지가 주어졌을 때, contrastive 모델은 이미지가 캡션과 얼마나 잘 맞는지에 따라 점수를 할당한다. Figure 6은 선택할 상위 k개의 이미지를 고를 샘플 수 N을 증가시킨 효과를 보여준다. 이 과정은 일종의 언어 유도 검색(language-guided search)으로 볼 수 있으며, Xu et al. (2018)이 제안한 auxiliary text-image matching loss와도 유사하다. 달리 명시되지 않는 한, 정성적 및 정량적 결과에 사용된 모든 샘플은 온도 감소 없이(i.e., t = 1 사용) 얻어지며 (Figure 2 제외), N = 512의 재정렬을 사용한다.

* 샘플 재정렬 : 생성된 여러 샘플을 평가하여 가장 적합한 샘플을 선택하는 과정.
3. Experiments
3.1 Quantitative Results
모델을 zero-shot 방식으로 평가하여 세 가지 기존 접근 방식 AttnGAN, DM-GAN, DF-GAN과 비교한다. 이 중 마지막은 MS-COCO에서 최고의 Inception Score (IS)와 Frechet Inception Distance (FID)를 보고한다. Figure 3은 모델의 샘플을 기존 작업의 샘플과 정성적으로 비교한다.
* Inception Score (IS) : 생성된 이미지의 품질과 다양성을 평가하는 지표. 높을수록 좋음.
* Frechet Inception Distance (FID) : 생성된 이미지와 실제 이미지 간의 유사성을 평가하는 지표. 낮을수록 좋음.

또한 Koh et al. (2021)에서 사용된 것과 유사한 인간 평가를 수행하여 본 연구의 접근 방식과 DF-GAN을 비교한다. 그 결과는 Figure 7에 나와 있다. 캡션이 주어졌을 때, 본 연구 모델에서 생성된 샘플은 93%의 경우 캡션과 더 잘 맞는 것으로 다수결 투표에서 선택되었다. 또한 90%의 경우 더 현실적인 것으로 다수결 투표에서 선택되었다.
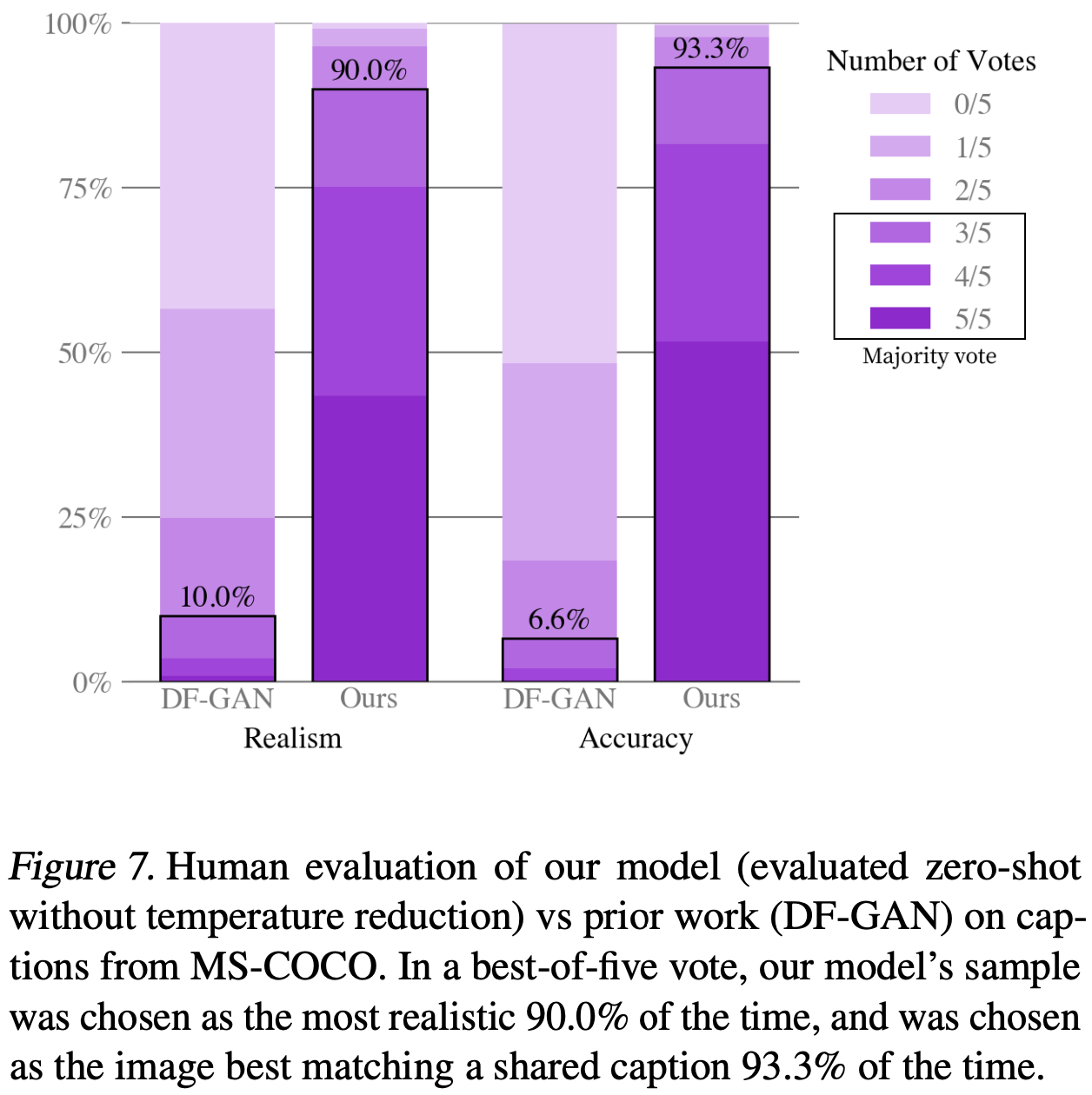
Figure 9(a)는 본 연구 모델이 캡션에 대해 훈련된 적이 없더라도 MS-COCO에서 최고의 기존 접근 방식보다 2점 이내의 FID 점수를 얻는다는 것을 보여준다. 훈련 데이터는 YFCC100M의 필터링된 하위 집합을 포함하며, 다음 section에서 설명하는 중복 제거 절차를 통해 MS-COCO 검증 세트 이미지의 약 21%를 포함하고 있다. 이 효과를 분리하기 위해, 이러한 이미지를 포함한 검증 세트(실선)와 이를 제외한 검증 세트(점선)에 대한 FID 통계를 계산하여 결과에 유의미한 변화가 없음을 발견했다.
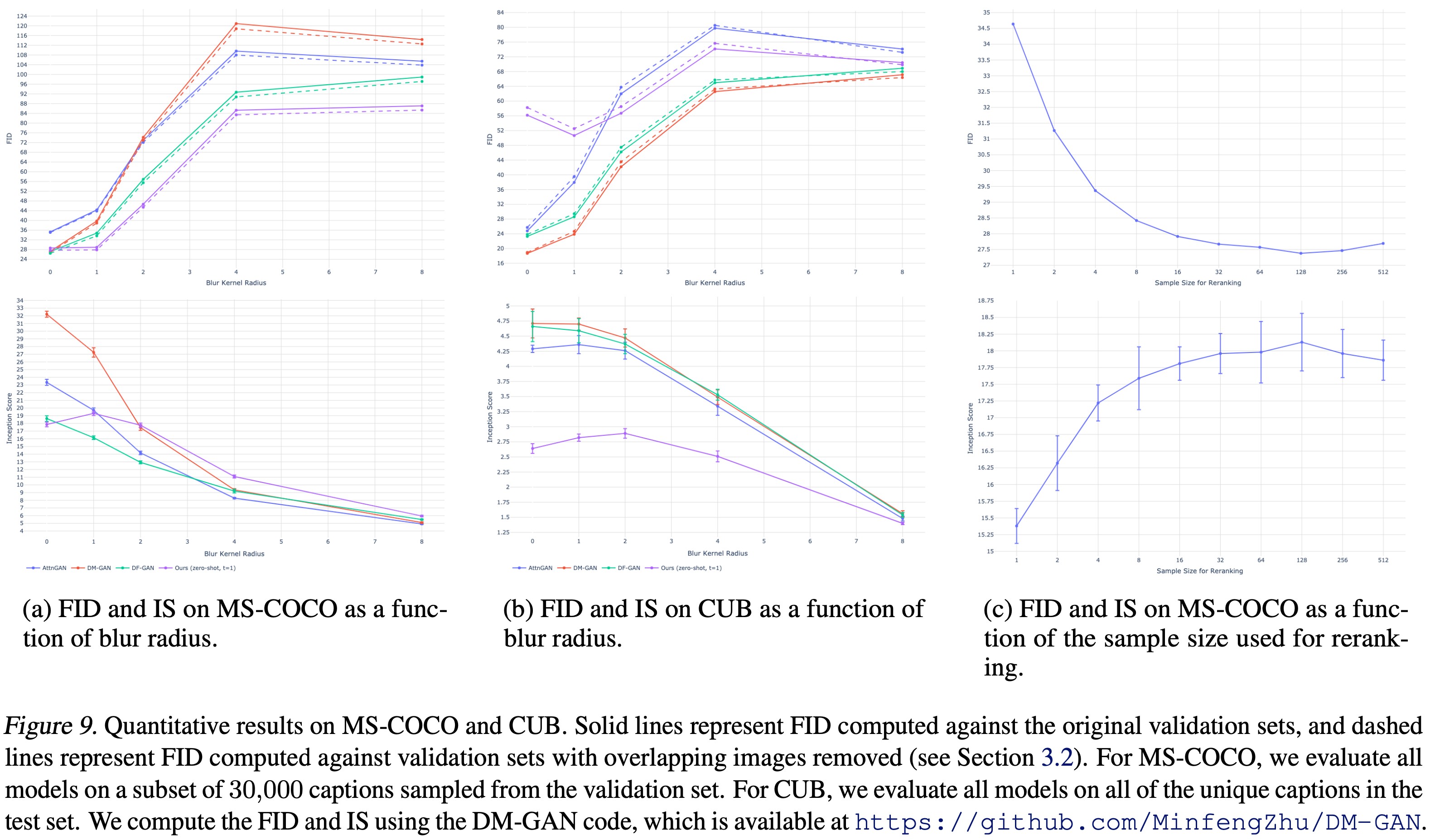
dVAE 인코더의 토큰을 사용하여 트랜스포머를 훈련하는 것은 이미지가 시각적으로 인식될 수 있게 하는 low-frequency 정보를 모델링하는 데 용량을 할당할 수 있게한다. 그러나 이는 모델에 불리한 점도 있는데, 이는 high-frequency 세부 사항을 생성할 수 없게 되기 때문이다. 이러한 효과를 정량적 평가에 미치는 영향을 테스트하기 위해, 검증 이미지와 모델 샘플 모두에 가우시안 필터를 다양한 반경으로 적용한 후 Figure 9(a)에서 FID와 IS를 계산했다. 본 연구의 접근 방식은 반경 1의 약간의 blur를 통해 약 6점 차이로 최고의 FID를 달성했다. blur 반경이 증가함에 따라 본 연구의 접근 방식과 다른 접근 방식 간의 격차가 더 커지는 경향이 있다. 또한 blur 반경이 2 이상일 때 가장 높은 IS를 얻었다.
* Gaussian Filter : 이미지에 blur 효과를 주기 위해 사용되는 필터로 저주파 정보를 강조.
* 반경 : gaussian filter의 적용 범위를 결정하는 파라미터로 반경이 클수록 더 많은 blur가 적용.
본 연구의 모델은 CUB 데이터셋에서 훨씬 더 나쁜 성능을 보였으며, 이 데이터셋에서는 본 연구의 모델과 기존 최고의 접근 방식 간에 FID에서 거의 40점 차이가 있었다(Figure 9(b)). 이 데이터셋의 중복율은 12%로 나타났으며, 이러한 이미지를 제거한 후에도 결과에 유의미한 차이는 없었다. 본 연구의 zero-shot 접근 방식이 CUB와 같은 특수한 분포에서는 상대적으로 더 나은 성능을 보이기 어렵다고 추측한다. fine-tuning이 개선을 위한 유망한 방향이라고 생각하며, 이 조사는 향후 작업으로 남겨둔다. 이 데이터셋의 캡션에 대한 본 연구의 모델의 샘플은 Figure 8에 나와 있다.

마지막으로, Figure 9(c)는 contrastive 모델을 사용한 재정렬에 사용된 샘플 크기가 증가함에 따라 MS-COCO에서 FID와 IS가 명확하게 개선되는 것을 보여준다. 이 추세는 샘플 크기가 32에 도달할 때까지 계속되며, 그 이후로는 diminishing returns 현상이 관찰된다.
* diminishing returns : 일정 지점 이후로 추가적인 노력이 점점 적은 성과를 가져오는 현상.
3.2 Data Overlap Analysis
Radford et al. (2021)에서 설명한 중복 제거 절차를 사용하여 제거할 이미지를 결정했다. 각 검증 이미지에 대해, 이 작업을 위해 특별히 훈련된 contrastive 모델을 사용하여 훈련 데이터에서 가장 가까운 이미지를 찾는다. 그런 다음, 훈련 데이터에서 가장 가까운 일치 항목과의 유사도에 따라 이미지를 내림차순으로 정렬한다. 결과를 직접 검사한 후, false negative 비율을 최소화하기 위해 보수적인 임계값을 수동으로 선택하여 제거할 이미지를 결정한다.
* false negative : 실제로는 중복된 이미지인데 중복되지 않은 것으로 잘못 판단되는 경우의 비율.
3.3 Qualitative Findings
본 연구의 모델이 처음에 예상하지 못했던 방식으로 일반화할 수 있는 능력을 가지고 있음을 발견했다. "a tapir made of accordion..."이라는 캡션을 주었을 때(Figure 2a), 모델은 아코디언을 몸으로 가진 테이퍼나, 키보드나, 베이스가 테이퍼의 코나 다리 모양인 아코디언을 그리는 것처럼 보인다. 이는 모델이 고도의 추상화 수준에서 특이한 개념을 조합할 수 있는 기본적인 능력을 개발했음을 시사한다.

본 연구의 모델은 또한 텍스트를 렌더링할 때 (Figure 2b)나 "an illustration of a baby hedgehog in a christmas sweater walking a dog"와 같은 문장에서 (Figure 2c) 조합적 일반화 능력을 갖추고 있는 것으로 보인다. 후자의 prompt는 모델이 variable binding을 수행해야 한다.(크리스마스 스웨터를 입고 있는 것은 개가 아니라 고슴도치이다.) 그러나 모델은 이 작업에서 일관되게 수행하지 못하며 때로는 두 동물 모두 크리스마스 스웨터를 입고 있는 그림을 그리거나 고슴도치가 작은 고슴도치를 산책시키는 그림을 그리는 경우도 있다.
* variable binding : 특정 특성이 특정 객체에 속하게 하는 능력. 예를 들어 고슴도치가 크리스마스 스웨터를 입는 경우.
제한된 신뢰도로, 본 연구의 모델이 자연어로 제어할 수 있는 zero-shot image-to-image 변환을 수행할 수 있음을 발견했다(Figure 2d). 모델에 "the exact same cat on the top as a sketch at the bottom"이라는 캡션과 고양이 사진의 이미지 토큰 그리드 중 상단 15 x 32 부분을 제공하면, 유사한 고양이를 아래에 스케치로 그릴 수 있다.
이 방식은 이미지 변환(e.g., 이미지 색상 변경, grayscale로 변환, 뒤집기)과 스타일 전환(e.g., 고양이를 축하 카드, 우표, 휴대전화 케이스에 그리기) 등의 여러 다른 종류의 변환에서도 작동한다. 동물의 색상만 변경하는 것과 같은 일부 변환은 모델이 기초적인 객체 분할을 수행할 수 있음을 시사한다. Appendix G에서 zero-shot image-to-image 변환의 추가 예제들을 제공한다.
* grayscale : 색상 정보를 제거하고 밝기 정보만으로 이미지를 표현하는 방식.
4. Conclusion
본 연구는 대규모로 실행될 때 autoregressive transformer를 기반으로 한 text-to-image 생성에 대한 간단한 접근 방식을 조사한다. 본 연구는 규모가 커질수록 이전의 도메인 특화 접근 방식에 비해 zero-shot 성능 측면에서 그리고 단일 생성 모델에서 나타나는 다양한 능력 측면에서 일반화가 개선될 수 있음을 발견했다. 본 연구에서의 발견은 모델의 크기나 훈련 데이터의 양을 증가시킴으로서 일반화를 개선하는 것이 이 작업의 진전을 위한 유용한 동인이 될 수 있음을 시사한다.



