본 글은 https://arxiv.org/abs/2108.10904 내용을 기반으로 합니다.
혹시 잘못된 부분이나 수정할 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
Abstract
최근 시각적 및 텍스트 표현의 공동 모델링의 진전으로 인해, Vision-Language Pretraining (VLP)은 많은 멀티모달 downstream task에서 인상적인 성능을 달성했다. 그러나 깨끗한 이미지 캡션과 regional label을 포함한 비싼 주석의 필요성은 기존 접근법의 확장성을 제한하고 여러 데이터셋별 objective의 도입으로 사전훈련 절차를 복잡하게 만든다. 이 연구에서는 이러한 제약을 완화하고 Simple Visual Language Model (SimVLM)이라는 최소한의 사전 훈련 프레임워크를 제시한다. 이전 연구와 달리, SimVLM은 대규모 weak supervision을 활용하여 훈련 복잡성을 줄이며 단일 prefix language modeling objective로 end-to-end로 훈련한다. 추가 데이터나 task별 맞춤화를 사용하지 않고도, 모델 결과는 이전 사전 훈련 방법을 크게 능가하며, VQA(+3.74% vqa-score), NLVR2(+1.17% accuracy), SNLI-VE(+1.37% accuracy) 및 image captioning tasks(+10.1% average CIDEr score)를 포함한 다양한 판별 및 생성 vision-language benchmark에서 SOTA 성능을 달성한다. 더욱이, SimVLM은 강력한 일반화 및 transfer 능력을 획득하여 open-ended visual question answering 및 cross-modality transfer와 같은 zero-shot 행동을 가능하게 함을 증명한다.
1. Introduction
Transformers를 기반으로 한 self-supervised 텍스트 표현 학습(BERT, GPT, VisualBERT, T5, GPT-2, GPT-3)은 광범위한 NLP task에서 SOTA 성능을 달성했다. 성공적인 접근 방식 중 하나는 대규모 라벨이 없는 텍스트 말뭉치에서 masked language modeling (MLM) objective를 사용하여 먼저 모델(e.g. BERT)을 사전훈련한 다음, downstream task에 대해 파인튜닝하는 것이다. 이 pretraining-finetuning 패러다임은 널리 채택되고 있지만, GPT-3와 같은 autoregressive language models (LM)에 대한 최근 연구는 few-shot prompt를 활용하여 파인튜닝 없이도 강력한 성능을 보여주었으며, text guided zero-shot 일반화가 유망한 대안임을 시사한다.
텍스트 표현 사전학습의 성공에 힘입어 멀티모달(visual and text) 대응을 구축하는 데 집중해왔다. 여러 연구들(VisualBERT, Oscar, VL-BERT 등)은 vision-language pretraining (VLP)을 탐구하여 visual question answering (VQA)와 같은 vision-language (VL) benchmark에 대해 파인튜닝될 수 있는 joint representation을 학습하는 방법을 연구해왔다. 이미지와 텍스트 간의 alignment를 포착하기 위해, 이전 방법들은 일반적으로 다음 단계를 포함하는 여러 출처의 두 가지 유형의 human-labeled 데이터셋을 광범위하게 활용했다. 첫째, object detection 데이터셋을 사용하여 supervised object detector (OD)를 훈련시켜, 이미지에서의 region-of-interest (ROI) 특징을 추출할 수 있도록 한다. 다음으로, 정렬된 image-text 쌍을 포함한 데이터셋을 사용하여, 추출된 ROI 특징과 쌍으로 된 텍스트를 입력으로 받는 융합 모델의 MLM 사전학습을 수행한다. 또한, human annotated 데이터의 규모가 제한되어 있기 때문에, 성능 향상을 위해 다양한 task별 auxiliary loss가 도입되었다. 이러한 설계 선택들은 VLP의 사전 학습 프로토콜을 복잡하게 만들어, 품질 향상의 병목 현상을 초래한다. 더욱이, 이러한 pretraining-finetuning 기반 접근 방식은 그들의 언어 대응 방식처럼 zero-shot 기능이 부족한 경우가 많다. 이에 비해, 또 다른 연구(CLIP, DALL-E 등)에서는 웹에서 크롤링한 weakly labeled/aligned 데이터를 활용하여 사전학습을 수행하고, image classification 및 image-text retrieval에서 좋은 성능과 특정 zero-shot learning 능력을 달성했다. 그럼에도 불구하고, 이러한 방법들은 주로 특정 task에 초점을 맞추기 때문에 VL benchmark를 위한 일반적인 pretraining-finetuning 표현으로는 적합하지 않을 수 있다.
* 일반적인 pretraining-finetuning 표현 : 특정 task에 국한되지 않고 범용적인 모델을 의미.
이러한 기존 기술의 단점들을 감안할 때, 본 연구는 다음과 같은 VLP 모델을 구축하는 데 관심이 있다. (1) pretraining-finetuning 패러다임에 원활하게 연결될 수 있고 표준 VL benchmark에서 경쟁력 있는 성능을 달성할 수 있으며 (2) 기존 방법처럼 복잡한 사전학습 프로토콜이 필요하지 않고 (3) cross-modal 설정에서 text guided zero-shot 일반화를 향한 잠재력을 가지고 있다. 이를 위해, weakly aligned image-text 쌍에 대한 언어 모델링 목표만을 활용하여 VLP를 크게 간소화하는 SimVLM(Simple Visual Language Model)을 제안한다. 요약하자면, SimVLM은 다음과 같은 구성 요소로 이루어져 있다.
- Objective. SimVLM은 Prefix Language Modeling (PrefixLM)의 단일 목표로 end-to-end로 훈련되며, 이는 GPT-3처럼 텍스트 생성을 자연스럽게 수행할 뿐만 아니라 BERT처럼 양방향으로 문맥 정보를 처리할 수 있다.
- Architecture. 이 프레임워크는 ViT/CoAtNet을 사용하며 원시 이미지를 직접 input으로 받는다. 이러한 모델은 대규모 데이터에 적합하며, PrefixLM 목표와도 쉽게 호환될 수 있다.
- Data. 이러한 설정은 object detection의 필요성을 줄이고 zero-shot 일반화에 대한 잠재력이 더 큰 대규모 weakly labeled 데이터셋을 활용할 수 있도록 한다.
SimVLM은 object detection pretraining이나 auxiliary loss가 필요하지 않을 만큼 단순할 뿐만 아니라, 이전 연구보다 더 나은 성능을 얻는다. 경험적으로, SimVLM은 기존의 VLP 모델을 일관되게 능가하며, 추가 데이터나 task별 customization 없이 6개의 VL benchmark에서 SOTA 성능을 달성한다. 또한, visual-language understanding에서 강력한 일반화를 획득하여 zero-shot image captioning과 open-ended VQA를 가능하게 한다. 특히, SimVLM은 텍스트 전용 데이터로 파인튜닝되고 추가 훈련 없이 image-and-text 테스트 예제를 직접 평가할 수 있는 zero-shot cross-modality transfer를 가능하게 하는 통합된 멀티모달 표현을 학습한다. 결과는 생성적 VLP가 VL task에서 기존의 MLM 기반 방법과 일치할 뿐만 아니라 유망한 zero-shot 잠재력을 보여줄 수 있음을 시사한다.
2. Related Work
최근 몇 년간 vision-language pretraining에서 빠른 진전이 이루어졌다. 다양한 접근 방식이 제안되었지만, 그 중 많은 부분은 사전 학습 목표의 일환으로 이미지 영역 특징 회귀 또는 태깅을 위해 object detection을 필요로 한다 (LXMERT, VL-BERT, VisualBERT, Oscar 등). 이러한 방법들은 종종 Visual Genome과 같은 인간이 주석을 달아준 데이터셋에서 훈련된 Fast(er) R-CNN과 같은 강력한 객체 탐지 모델에 의존한다. 이러한 라벨링된 훈련 데이터를 전제 조건으로 사용하면 훈련 파이프라인을 구축하는 비용이 증가하고 접근 방식의 확장성이 떨어진다. 일부 최근 연구는 object detection 없이 VLP를 탐구하기도 했다. 하지만, 이들은 소규모의 깨끗한 사전학습 데이터만 사용하여 zero-shot 기능이 제한적이다.
한편, 여러 cross-modality loss function이 훈련 목표의 일환으로 제안되었다. 예를 들어, image-text matching, masked region classification/feature regression, object attribute prediction, contrastive loss, word-region alignment, word-patch alignment 등이 있다. 이러한 손실 함수들은 종종 image caption 생성 및 masked language modeling을 포함한 다른 목표들과 혼합되어 복합 사전 학습 loss를 형성한다. 이는 다양한 loss와 데이터셋 간의 균형을 맞추는 문제를 야기하며 최적화 절차를 복잡하게 만든다.
이에 비해, 본 연구는 원시 이미지를 input으로 받아 언어 모델링 loss만을 사용하는 minimalist 접근 방식을 따르며, 이미지 영역 검출을 위한 Faster R-CNN과 같은 보조 모델을 사용하지 않는다. 특정 image-text task에서 zero-shot 학습을 보여주는 최근 연구들에 힘입어, 본 연구는 대규모 weakly labeled 데이터만을 사용하여 모델을 훈련시킨다. concurrent 연구는 이러한 데이터셋으로 사전 학습된 모델을 기반으로 구축하는 것을 탐구했지만, 본 연구는 생성적 VLP의 한계를 탐구하기 위해 처음부터 사전 학습에 집중한다.
3. SimVLM
3.1 Background
양방향 Masked Language Modeling (MLM)은 텍스트 표현 학습을 위한 가장 인기 있는 self-supervised 학습 목표 중 하나였다. BERT에 의해 입증된 바와 같이, 이는 문서에서 손상된 토큰을 복원하도록 모델을 훈련시키는 denoising autoencoder의 아이디어를 기반으로 한다. 구체적으로, 주어진 텍스트 시퀀스 x에서 토큰 하위 집합 xm을 무작위로 샘플링하고 xm의 토큰을 special token [MASK]로 대체하여 손상된 시퀀스 x\m을 구성한다. 훈련 목표는 negative log-likelihood를 최소화하여 문맥 x\m에서 xm으로 재구성하는 것이다.

여기서 세타는 모델의 학습 가능한 파라미터이고 D는 사전학습 데이터이다. 이 접근 방식은 downstream task를 위해 추가로 파인튜닝될 수 있는 문맥화된 표현을 학습한다. MLM 스타일의 사전학습은 이전 VLP 모델에서 널리 채택되었으며, input은 이미지-텍스트 쌍이고 모델은 이미지 ROI 특징을 활용하여 마스킹된 토큰을 예측해야 한다.
또한, 단방향 Language Modeling (LM)은 forward autoregressive 인수를 사용하여 시퀀스 x의 가능성을 최대화하도록 모델을 훈련시킨다.
MLM과 비교할 때, LM 사전학습은 여러 NLP task에 대해 매우 효과적인 것으로 나타났다(GPT-1). 더 중요한 점은, LM은 모델이 텍스트로 유도된 zero-shot 일반화를 파인튜닝 없이 수행할 수 있는 강력한 생성능력을 제공한다(GPT-3). 위에서 검토한 VLP 모델에서 MLM이 사실상 표준 접근 방식이 된 반면, 생성적 LM은 충분히 연구되지 않았다.
3.2 Proposed Objective: Prefix Language Modeling
LM loss로 사전학습된 zero-shot 능력에 영감을 받아, Prefix Language Modeling (PrefixLM)을 사용하여 vision-language 표현을 사전학습할 것을 제안한다. PrefixLM은 표준 LM과 달리 접두사 시퀀스(e.g. Eg.(3)에서 x<Tp)에 양방향 attention을 가능하게 하며, 나머지 토큰들(e.g. Eg.(3)에서 x>= Tp)에 대해서만 autoregressive 인수를 수행한다. 사전학습 과정에서, (무작위로 선택된) 길이 Tp의 토큰 접두사 시퀀스가 input 시퀀스에서 잘리고 훈련 목표는 다음과 같이 된다.
직관적으로, 이미지는 종종 웹 문서에서 텍스트보다 먼저 나타나기 때문에 텍스트 설명에 대한 접두사로 간주될 수 있다. 따라서, 주어진 이미지-텍스트 쌍에 대해, 길이 Ti의 이미지 특징 시퀀스를 텍스트 시퀀스에 앞서 붙이고, 모델이 텍스트 데이터에 대해서만 접두사 길이 Tp>=Ti를 샘플링하여 LM loss를 계산하도록 한다(예시는 Figure 1에 나와 있음). 이전의 MLM 스타일 VLP 방법과 비교하여, 본 연구의 PrefixLM 모델은 sequence-to-sequence 프레임워크에서 MLM처럼 양방향 문맥화된 표현을 누리면서도 LM처럼 텍스트 생성을 수행할 수 있다.
3.3 Architecture
language 및 vision task 모두에서 성공을 거둔 Transformer를 모델의 백본으로 채택한다. 표준 LM과 달리, PrefixLM은 접두사 시퀀스 내에서 양방향 attention을 가능하게 하여, 디코더 전용 모델과 인코더-디코더 sequence-to-sequence 언어 모델 모두에 적용할 수 있다. 예비 실험에서, 생성과 인코딩을 분리하는 인코더-디코더 모델이 도입한 귀납적 편향이 downstream task의 개선에 도움이 된다는 것을 발견했다.
* 인코더 디코더 모델의 귀납적 편향 : 모델 구조가 특정 방식으로 데이터를 처리하도록 설계되어, 이 설계가 모델의 성능을 향상시키는 데 도움이 되는 특성을 가지는 것을 의미.
SimVLM 모델 아키텍처의 개요는 Figure 1에 나와 있다. visual modality의 경우, ViT와 CoAtNet에서 영감을 받아 모델은 원시 이미지 R H x W x C를 받아 평탄화된 1D 패치 시퀀스 R Ti x D로 변환하여 Transformer의 input으로 사용한다. 여기서 D는 Transformer 레이어의 고정된 hidden size이고 Ti = HW/P^2는 주어진 패치 크기 P에 대한 이미지 토큰의 길이이다. Dai et al. (2021)을 따라, ResNet의 첫 세 블록으로 구성된 컨볼루션 단계를 사용하여 문맥화된 패치를 추출하며, 이는 ViT에서 사용된 naive linear projection(1x1 Conv 레이어와 동등)보다 유리하다는 것을 발견했다. textual modality의 경우, input 문장을 서브워드 토큰으로 토큰화하는 표준 방법을 따르며, 고정된 어휘에 대한 임베딩을 학습한다. 위치 정보를 유지하기 위해, 이미지와 텍스트 input에 대해 각각 두 개의 학습 가능한 1D 위치 임베딩을 추가하고, Transformer 레이어 내에서 이미지 패치에 대한 2D 상대적 attention을 추가한다. 실험에서 개선이 없음을 발견하여 추가 모달리티 타입 임베딩은 추가하지 않았다. 모델의 다양한 구성 요소의 효과는 4.4절에서 연구한다.
3.4 Datasets
본 연구의 접근 방식은 object detection 모듈에 의존하지 않으며 원시 이미지 패치 Input만으로 작동하기 때문에, 대규모 노이즈가 있는 이미지-텍스트 데이터를 사용하여 모든 모델 파라미터를 처음부터 학습한다. 이는 zero-shot 일반화에 대한 잠재력이 더 높다. 구체적으로, 최소한의 후처리로 웹에서 크롤링한 Jia et al. (2021)에서 소개된 이미지와 대체 대체 텍스트(alt-text) 쌍을 사용한다. 반면, PrefixLM 공식은 모달리티에 구애받지 않기 때문에, 대체 텍스트 데이터의 노이즈 있는 텍스트 supervision을 보완하기 위해 텍스트 전용 코퍼스를 추가로 포함할 수 있다. 나중에 실험에서 보듯이, 이 통합된 PrefixLM 공식은 모달리티 불일치를 줄이고 모델 품질을 향상시킨다. 이전의 VLP 방법들이 두 개의 사전학습 단계와 여러 보조 objective들을 포함하는 것과 비교하여, SimVLM 모델은 end-to-end 방식으로 단일 언어 모델링 loss를 사용한 one-pass 사전학습만을 필요로 하므로, Simple Visual Langue Model (SimVLM)이라는 이름이 붙여졌다.
4. Experiments
visual question answering, image captioning, visual reasoning, visual entailment, and multimodal translation을 포함한 다양한 visual-linguistic benchmark에 대해 체계적인 실험을 수행한다. pretraining-finetuning 패러다임에서 general-purpose의 VL 표현 학습으로서의 모델을 검토할 뿐만 아니라, open-ended VL 이해에 대한 zero-shot 일반화도 연구한다.
* pretraining-finetuning 패러다임에서 general purpose의 VL 표현 학습 : 특정 task나 데이터셋에 특화되지 않고, 다양한 VL task에 널리 적용될 수 있는 모델을 의미.
4.1 Setup
본 연구의 모델은 Lingvo 프레임워크를 사용하여 구현되었다. ViT의 설정을 따라 "Base", "Large", "Huge"의 세 가지 SimVLM 변형을 탐구하며, 각 변형은 해당 ViT 변형과 동일한 설정을 따른다. 모든 모델은 ALIGN의 훈련 세트와 Colossal Clean Crawled Corpus (C4) 데이터셋에서 약 100만 스텝 동안 처음부터 사전학습된다. 그리고 각 배치 내에서 두 개의 사전학습 데이터셋을 혼합하며, 각 배치는 4,096개의 이미지-텍스트 쌍 (ALIGN)과 512개의 텍스트 전용 문서 (C4)를 포함하고 512개의 TPU v3 칩에 분산된다. 추가적인 사전학습 설정은 부록 B.1에 자세히 나와있다.
* Lingvo 프레임워크 : 구글이 개발한 딥러닝 프레임워크로 TensorFlow를 기반으로 구축되었으며 대규모 분산 훈련을 지원하여 수천 개의 TPU와 GPU에서 효율적으로 실행할 수 있음.
사전학습이 완료된 후, 본 연구의 모델은 VQA v2, SNLI-VE, NLVR2와 같은 세 가지 판별 task와 CoCo captioning, NoCaps, Multi30k와 같은 세 가지 생성 task를 포함한 여섯 가지 vision-language benchmark에서 파인튜닝 및 평가된다. 또한, 단일 모달리티 task에 대한 zero-shot 일반화와 성능도 검토한다. 고려된 task와 파인튜닝 과정의 세부 사항은 부록 B.2에 나와 있다.
4.2 Comparison With Existing Approaches
vision-language 사전학습의 품질을 검토하기 위해, LXMERT, VL-T5, UNITER, OSCAR, Villa, SOHO, UNIMO, VinVL 등 SOTA VLP 방법들과 함께 인기 있는 멀티모달 task에서 SimVLM을 비교했다.
Table 1에서 볼 수 있듯이, SimVLM은 모든 기존 모델을 능가하며, 고려된 모든 task에서 새로운 SOTA 성능을 달성했다. 이는 생성적 사전학습 접근 방식이 MLM 기반 모델들과 경쟁할 수 있으며, weak supervision만으로도 고품질 멀티모달 표현을 학습하는 데 충분함을 보여준다.
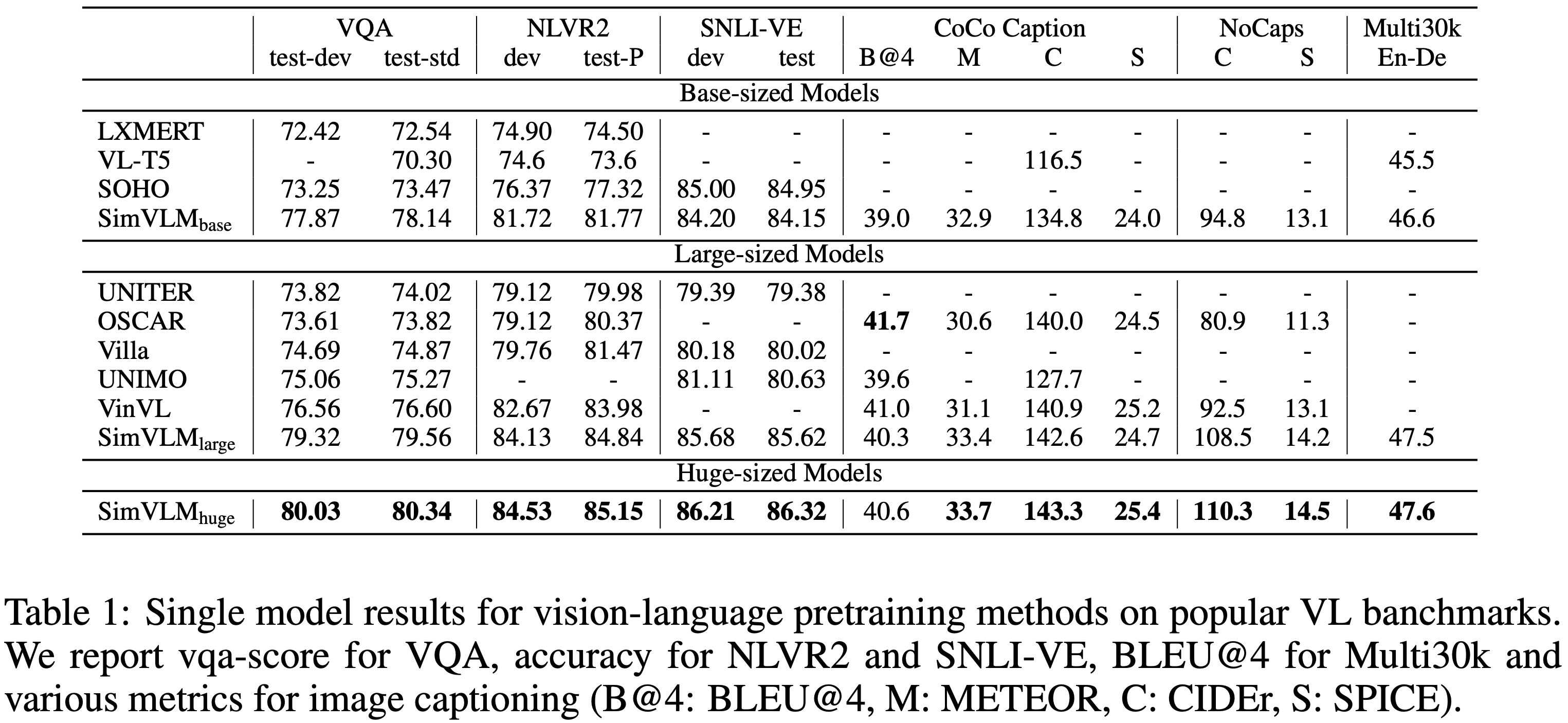
판별 task의 경우, SimVLM base는 더 적은 용량을 사용하면서도 모든 이전 방법들을 능가하며 SimVLM huge는 이전 SOTA (VinVL)보다 절대 점수 4점 가까이 개선되어 처음으로 VQA에서 단일 모델 성능을 80% 이상으로 끌어올렸다. 또한, SimVLM은 NLVR2와 SNLI-VE에서도 이전 방법을 일관되게 능가하여, 더 복잡한 vision-linguistic 추론을 처리할 수 있는 능력을 보여준다. image captioning 및 image translation을 포함한 생성 task에서도 SimVLM은 단순한 파인튜닝 기법을 사용하여 큰 개선을 보였다. 본 연구의 모델은 CoCo captioning의 공개 "Karpathy" 5k test 분할에서 4가지 metric 중 3가지에서 이전 방법을 능가했으며, NoCaps benchmark에서도 CIDEr 최적화의 복잡한 강화 학습 접근 방식으로 훈련된 이전 방법보다 뛰어난 성능을 보였다. 마지막으로, SimVLM은 Multi30k에서 영어에서 독일어로의 이미지 번역에도 효과적이다. 이러한 실험들을 본 연구의 모델이 최소한의 사전학습 및 파인튜닝 절차를 사용하여 pretraining-finetuning 패러다임에 원활하게 통합되어 우수한 성능을 발휘할 수 있음을 입증한다.
4.3 Zero-shot Generalization
weak supervision을 통한 생성 모델링 및 확장의 중요한 이점은 zero-shot 일반화의 잠재력이다. 이전 연구들은 사전학습된 모델에서 downstream 데이터셋으로 few-shot 또는 zero-shot transfer를 수행할 수 있는 능력을 보여주었으며, 언어 경계를 넘어서도 이를 수행할 수 있음을 입증했다. 이 섹션에서는 이전 VLP 연구에서 덜 탐구된 세 가지 zero-shot 응용 설정을 소개하며, 여기에는 보지못한 task, 모달리티 및/또는 테스트 인스턴스로의 전이가 포함된다.
* 테스트 인스턴스 : 모델의 성능을 평가하기 위해 사용하는 데이터 예제. 테스트 데이터셋에 포함된 각 샘플로, 모델이 훈련되지 않은 상태에서 예측을 수행해야 하는 데이터.
4.3.1 Zero-shot / Few-shot Image Captioning
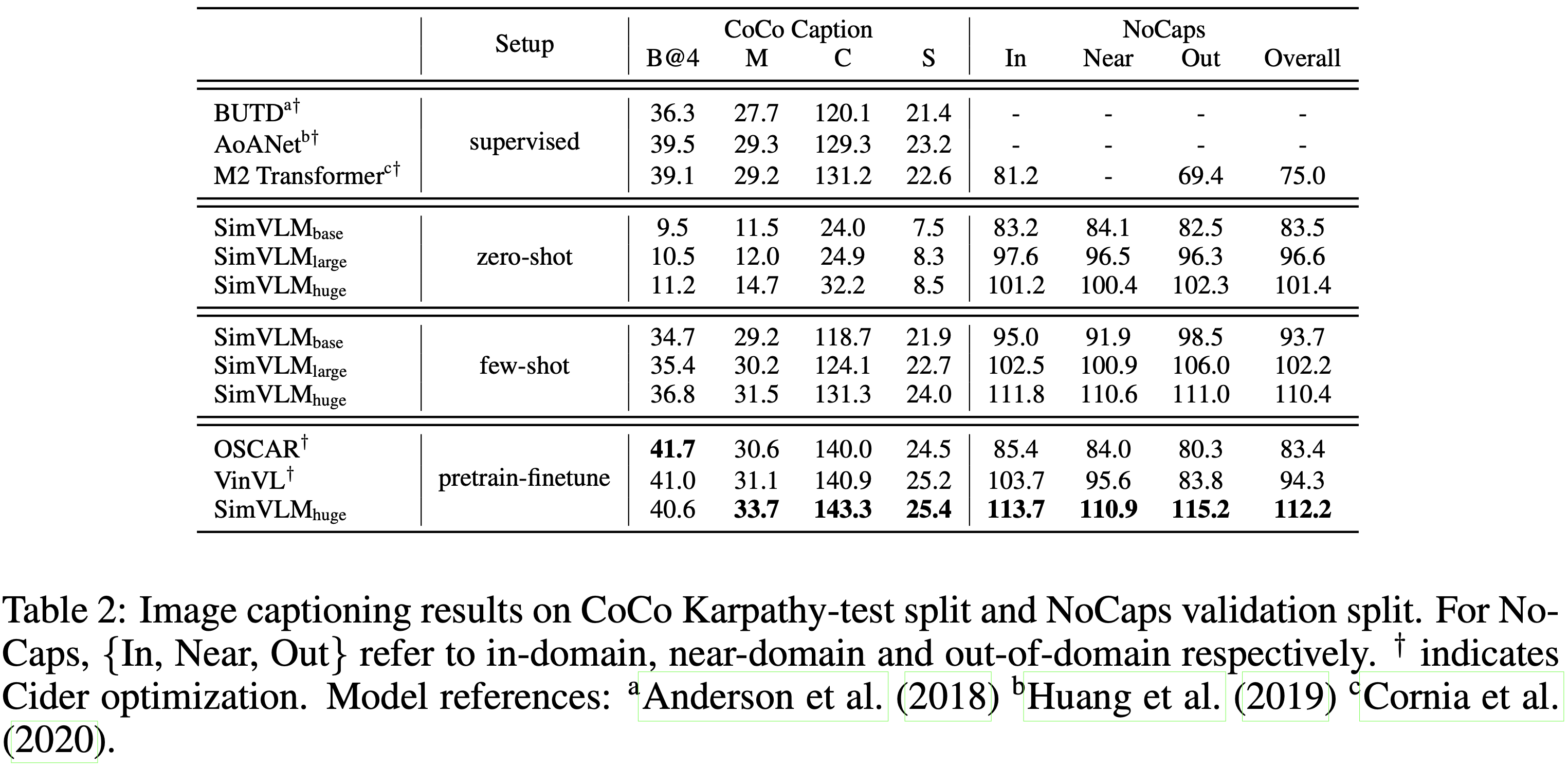
SimVLM의 사전학습 절차는 실제 웹 코퍼스에서의 노이즈가 있는 image captioning 목표로 해석될 수 있다. 따라서 이 caption 생성 능력이 zero-shot/few-shot 방식으로 다른 데이터셋에 얼마나 잘 일반화되는지 묻는 것은 자연스러운 일이다. 이를 위해, 사전학습된 SimVLM 모델을 사용하여 zero-shot 설정에서는 image captioning benchmark에서 직접 디코딩하고 few-shot 설정에서는 훈련 데이터의 1%로 5 epoch 동안 파인튜닝한다. 또한, "A picture of"라는 접두사 프롬프트를 사용하면 디코딩된 캡션의 품질이 향상된다는 것을 발견했으며, 이는 CLIP 연구에서의 발견과 유사하다.
Table 2에 나와 있듯이, SimVLM의 zero-shot/few-shot 성능 (Appendix D)은 CoCo에서 fully supervised baseline 모델들과 경쟁할 만하며, 사전학습된 모델들보다 더 나은 점수를 달성하여 개념이 풍부한 NoCaps 벤치마크에서 강력한 일반화를 보여준다. Figure 2 (a)는 본 연구의 모델이 생성한 샘플 캡션을 보여준다 (Appendix A). SimVLM은 실제 세계의 개념을 포착할 뿐만 아니라 visual input에 대한 자세한 설명을 제공할 수 있다. 예를 들어, 디코딩된 샘플은 "people", "table with drinks", "dark restaurant" 등 여러 객체가 있는 복잡한 장면을 설명할 수 있다. 또한, 모델은 특정 자동차 브랜드 및 모델 (e.g. "Aston Martin", "Vantage")과 같은 세밀한 추상 개념도 이해하고 있음을 보여준다. SimVLM은 추상적이거나 어두운 이미지와 같이 인간에게 까다로울 수 있는 도전적인 이미지에서도 견고한 성능을 발휘한다. 이는 본 연구의 모델이 zero-shot 방식으로 잘 일반화되는 다양한 실제 세계의 개념을 학습했음을 보여준다.

4.3.2 Zero-shot Cross-modality Transfer
기존의 사전학습 방법들은 이질적인 데이터 공간 간의 지식을 성공적으로 전이할 수 있음을 보여주었다. 예를 들어, 다국어 언어 모델은 모델이 소스 언어(일반적으로 영어)의 훈련 데이터만을 사용하여 파인튜닝되고 추가 학습없이 대상 언어에게 평가되는 zero-shot cross-modality transfer를 가능하게 한다. 이러한 설정에서 영감을 받아, VLP 모델을 활용한 새로운 zero-shot cross-modality transfer 패러다임을 탐구하고, 모델이 모달리티 간에 얼마나 잘 일반화되는지를 평가한다. 텍스트 훈련 데이터는 시각 데이터에 비해 얻기 쉬운 경우가 많기 때문에, SimVLM을 텍스트 전용 downstream 데이터로 파인튜닝한 다음, joint VL task에서 zero-shot 전이를 직접 평가한다.
구체적으로, SNLI-VE와 Multi30k를 활용하여 zero-shot 전이 성능을 검사한다. SNLI-VE의 경우, 세 가지 텍스트 전용 NLI 데이터셋에서 전제를 인코더의 input으로 사용하고 가설을 디코더에 입력하여 파인튜닝한다. 디코더의 마지막 토큰의 임베딩에 유사한 classifier head를 훈련시킨다. 추론 시에는 파인튜닝된 모델을 평가할 때 전제 이미지를 인코더 input으로 사용하고 해당 가설 문장을 디코더에 입력한다. Table 3에서 볼 수 있듯이, SimVLM은 zero-shot 설정에서 UNITER를 포함한 fully supervised baseline 모델들과 경쟁력 있는 성능을 발휘한다. 검증을 위해 이미지 특징을 마스킹하고 가설만으로 예측한 결과, 모델이 무작위 추측에 가까운 결과(average score 34.31 / 34.62)를 얻을 수 있음을 발견했다. 이는 무작위 추측에 가까운 성능을 나타내며, SimVLM의 cross-modality transfer 능력의 유효성을 입증한다.
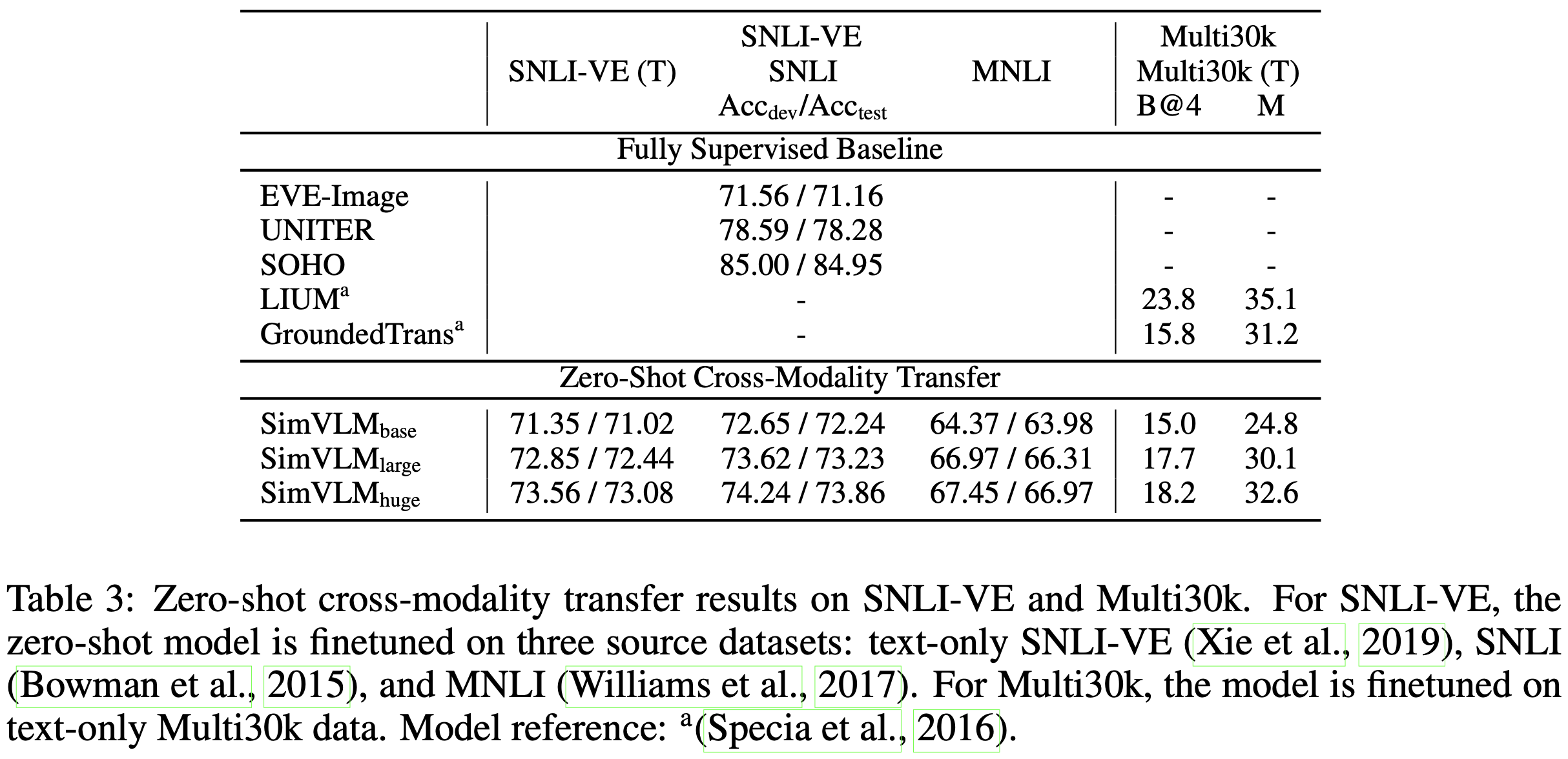
또한, SimVLM은 MNLI 데이터셋에서 SNLI-VE로 전이함으로써 도메인 적응도 가능하다. 여기서 데이터는 다른 모달리티뿐만 아니라 다른 도메인에서도 나온다. 본 연구는 SimVLM을 사용하여 다른 언어와 모달리티 간의 전이도 가능함을 발견했다. 구체적으로, Multi30k의 WMT 2016에서 독일어 image captioning task를 평가에 활용하였으며, 모델을 영어-독일어 텍스트 전용 번역 데이터로 파인튜닝한 후 인코더에 이미지 input만으로 디코딩했다. Table 3은 SimVLM이 생성 task에서 모달리티와 언어 간 지식을 전이할 수 있음을 보여주며, supervised baseline 모델들과 비교할 만한 성능을 달성했음을 나타낸다(디코딩된 예시는 Figure (b)에 나와 있음). 이러한 결과는 weakly labeled 데이터의 규모가 커짐에 따라 zero-shot cross-modality 전이가 나타날 수 있음을 시사한다.
4.3.3 Open-ended VQA
VQA 벤치마크에서 현재까지 가장 성능이 좋은 모델들은 3,129개의 사전 정의된 정답 후보에 대한 다중 라벨 분류의 판별 task로 문제를 공식화하며, 이는 종종 짧은 사실적 용어로 구성된다. 그러나 실제 응용에서는 모든 가능한 시나리오를 포함하는 closed 정답 후보 집합을 정의하는 것이 어려워, 진정한 open-ended VQA는 도전적인 설정이 된다.
SimVLM과 같은 생성 모델은 사전 정의된 정답에 제한되지 않고 자유 형식의 텍스트 정답을 생성함으로써 이 문제에 대한 솔루션을 제공한다. 이를 위해, 이미지와 질문의 결합을 접두사로 간주하고, 정답을 생성하도록 모델을 훈련하는 PrefixLM loss를 사용하여 SimVLM을 파인튜닝한다.
그 다음, Table 4에서 생성 접근 방식과 분류 방법을 비교한다. 먼저, Cho et al. (2021)을 따라 Karpathy 테스트 분할에서 드문 정답이 있는 질문에 대해 모델 성능을 평가한다. 여기서 out-of-domain 질문은 3,129개의 후보 정답에 포함되지 않고 최고 점수의 정답을 가진 질문으로 정의된다. 결과는 SimVLM이 모든 분할에서 판별 및 생성 기준 모델들을 능가함을 보여준다. 더 중요한 것은, 생성적 SimVLM이 out-of-domain 외 분할에서 17점 이상 개선되어 강력한 일반화 능력을 입증했다는 것이다. 그러나 이 설정은 주로 드문 정답에 초점을 맞추고 있어 모델이 일반적인 보지 못한 정답에 얼마나 잘 일반화되는지는 불분명하다. 따라서 3,129개의 후보 정답 중 2/3에 해당하는 2,085개를 무작위로 선택하고 최고 점수를 받은 정답이 선택된 집합에 포함되는지 여부에 따라 훈련 및 검증 세트를 두 개의 분할로 나누는 더 도전적인 설정을 조사한다. 그런 다음 훈련 세트의 도메인 내 분할에서만 SimVLM을 파인튜닝하고 전체 검증 세트에서 평가한다. Table 4의 "Partial Train" 열은 생성적 SimVLM이 1,000개 이상의 보지 못한 정답에 대해 합리적인 성적을 내면서 이 설정에서도 유능함을 보여준다. 전반적으로, 생성적 SimVLM이 표준 설정에서 판별 모델과 경쟁력 있는 성능을 발휘하며 out-of-domain 경우에서 일반적으로 더 나은 성능을 보인다는 것을 발견했다.
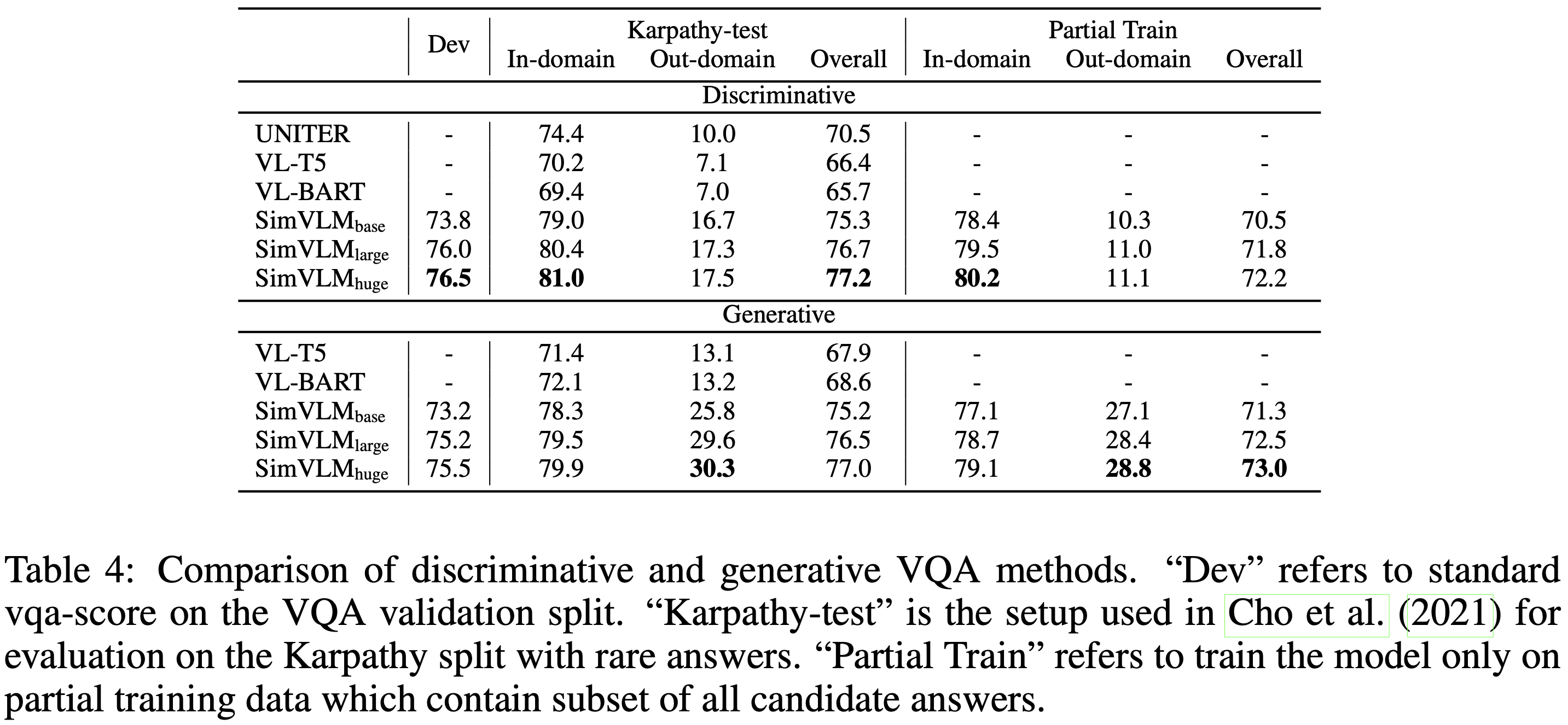
위 실험에서 점수 계산을 위해 생성된 답변과 인간 레이블 간의 정확한 일치를 사용했지만, 모델이 다른 형식이나 동의어로 적절한 답변을 생성할 가능성도 있다. 따라서, 위의 정량적 연구에 추가하여 Figure 2 (c)에 질적 생성 결과를 보여준다. SimVLM이 3,129개의 후보 정답 집합에 포함되지 않은 답변(e.g. "surgeon" 및 "wood carving")을 생성할 수 있음을 확인할 수 있으며, 이는 SimVLM이 사전학습 코퍼스에서 VQA로 지식을 전이할 수 있음을 보여준다. 따라서 SimVLM이 전혀 파인튜닝 없이 zero-shot VQA를 수행할 수 있는지 묻는 것은 자연스러운 일이다. 실험에서, SimVLM이 프롬프트 문장을 완성하여 "answer"할 수 있음을 발견했다(Figure 2 (d) 참조). 그럼에도 불구하고, 모델이 실제 질문에 대해 의미 있는 답변을 생성하는 데 부족함이 있음을 또한 관찰했다. 이는 대부분의 텍스트 설명이 짧고 노이즈가 많은 사전 학습 데이터의 낮은 품질 때문이라고 가정한다. 본 연구의 가정을 검증하기 위해, 더 깨끗한 WIT 데이터셋에서 50k step 동안 사전학습 과정을 계속했다. Figure 2 (e)의 예시는 SimVLM이 지식이 풍부한 위키피디아 데이터셋에서 파인튜닝한 후 관련된 응답을 생성할 수 있게 되면서 open-ended VQA 능력이 나타남을 보여준다.
4.4 Analysis
Single-Modality Tasks.
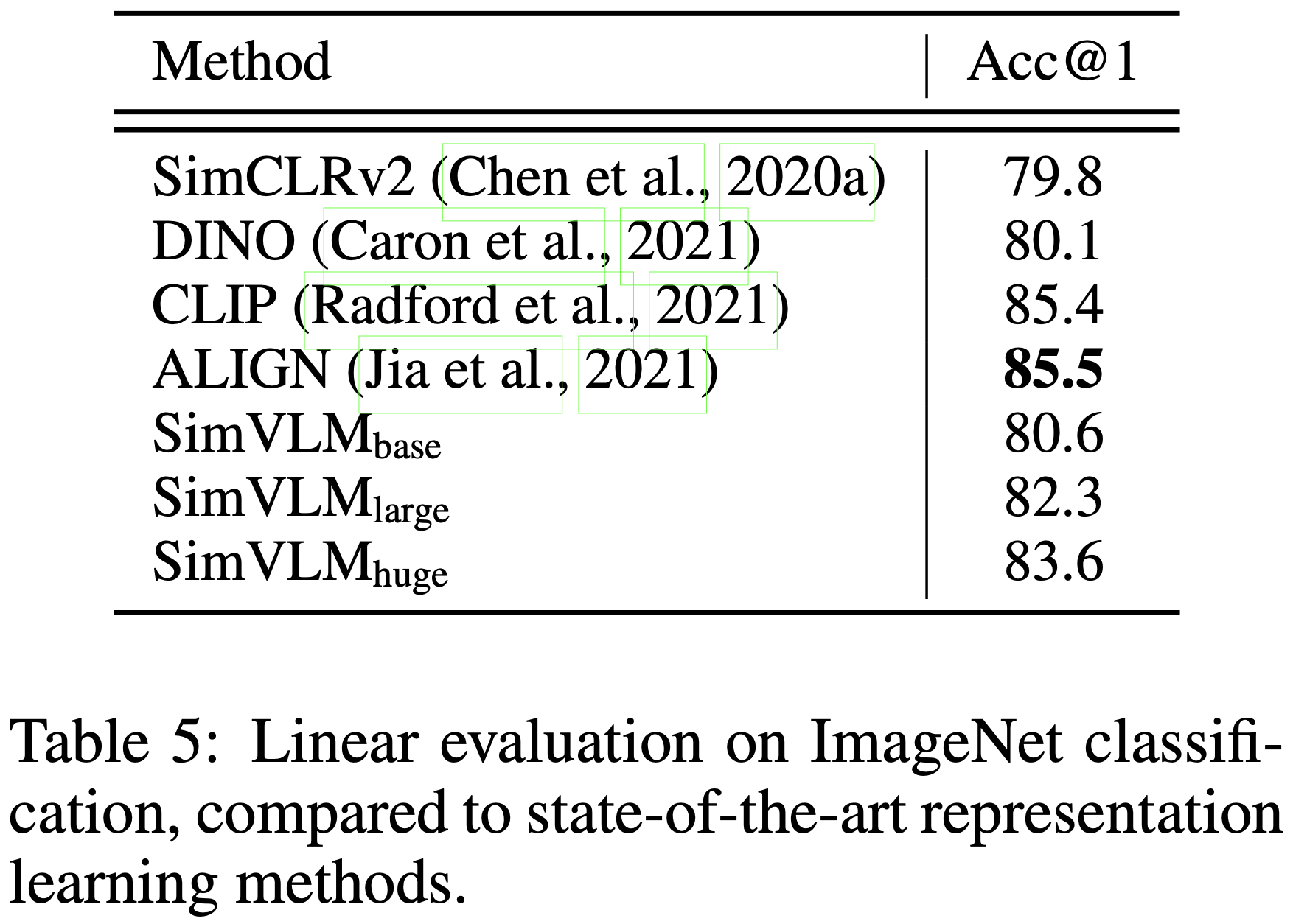
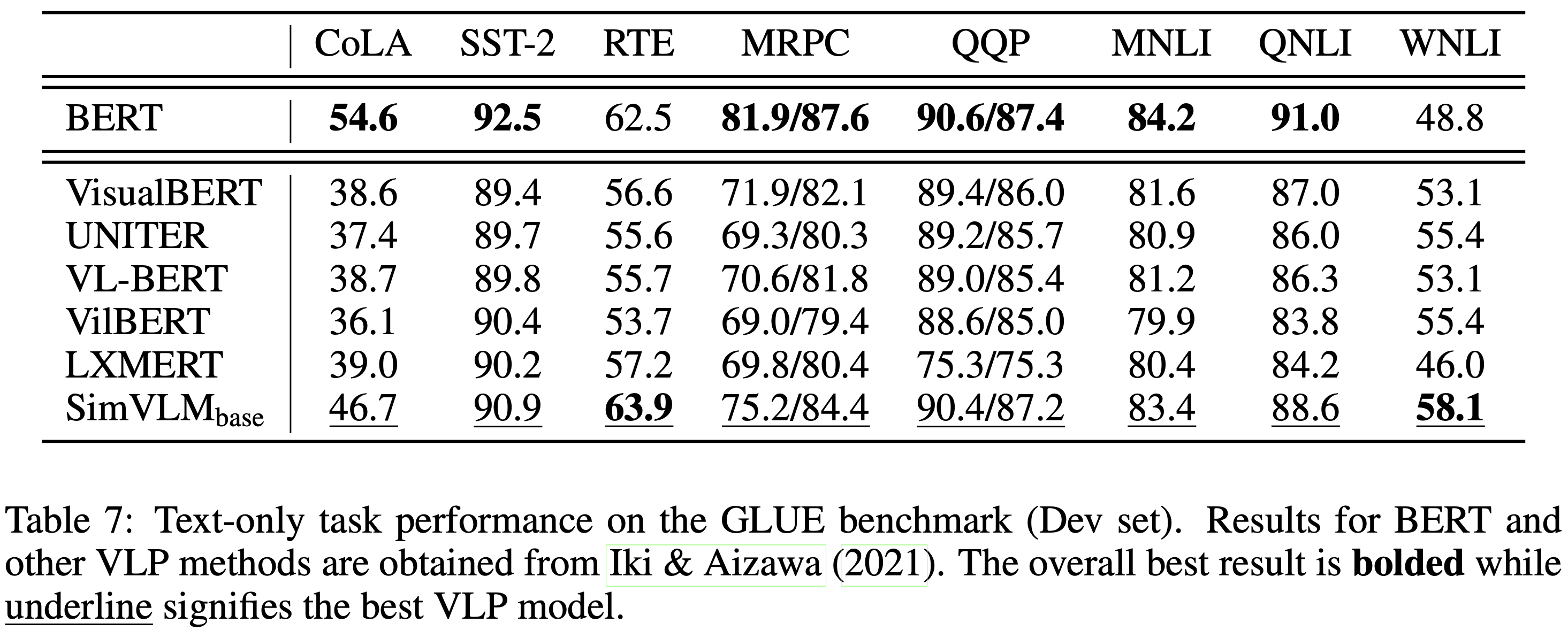
SimVLM이 joint vision-language benchmark에서 좋은 성능을 보이므로, 학습된 표현이 단일 모달리티 task에서 얼마나 잘 수행되는지 묻는 것은 자연스러운 일이다. 이러한 벤치마크에서 모델의 성능을 검토하여 모델 동작에 대한 더 깊은 통찰을 얻고자 하지만, 단일 모달리티 SOTA 성능을 달성하는 것이 본 연구의 의도는 아니다. Appendix C의 Table 7에서, SimVLM을 기존의 VLP 모델들과 GLUE 벤치마크에서 비교한다. 여기서 주로 T5의 텍스트 처리 절차를 따르며 토큰 타입 임베딩 없이 완전히 형식화된 input을 분류하도록 모델을 훈련시킨다. SimVLM은 기존의 VLP 방법들보다 더 나은 성능을 보이며, BERT와 경쟁력 있는 성능을 발휘하여 우수한 언어 이해 능력을 가지고 있음을 나타낸다. 추가적으로, Table 5의 linear evaluation protocol을 따라 ImageNet에서 top-1 accuracy를 계산한다. 본 연구의 모델은 contrastive loss와 같은 판별 task로 사전학습되지 않았기 때문에, 인코더 출력의 평균 풀링을 이미지 특징으로 사용한다. 결과는 본 연구의 모델이 고품질의 이미지 표현도 학습했음을 확인시켜준다.
* linear evaluation protocol : 사전 학습된 모델이 학습한 표현의 품질을 평가하는 데 사용되는 방법으로, 복잡한 모델을 다시 학습시키는 대신 간단한 선형 분류기를 사용하여 모델이 학습한 특징이 얼마나 유용한지를 평가. 사전학습 -> 특징 추출 -> 선형 분류기 학습 -> 평가
Ablation Study.
각 모델 구성 요소의 기여도를 연구하기 위해, 임베딩 차원이 512이고 8개 레이어로 구성된 SimVLM small 모델을 대상으로 소거 연구를 수행했다. VQA에서의 비교 결과는 Table 6에 나와 있다. 먼저, 인코더-디코더 모델과 유사한 모델 크기의 디코더 전용 모델을 비교한 결과, 디코더 전용 모델이 VQA에서 현저히 더 나쁜 성능을 보였다. 이는 양방향 인코딩과 단방향 디코딩을 분리하는 귀납적 편향이 joint VL 표현 학습에 유익하다는 것을 시사한다. 다음으로, 사전학습 목표의 효과를 연구한 결과 Prefix 목표가 span corruption 및 단순 LM 모두를 능가하여 이미지-텍스트와 텍스트 전용 데이터 모두에 대해 통합된 목표 공식을 사용하는 것이 중요함을 보여준다. 또한, 데이터셋의 기여도를 소거한 결과 시각적 및 텍스트적 표현 간의 격차를 줄이기 위해 weakly aligned 이미지-텍스트 데이터가 필요하지만 텍스트 전용 코퍼스도 모델 품질을 향상시킨다는 것을 확인했다. 이는 전자가 매우 노이즈가 많은 텍스트 신호를 포함하고 있어 모델이 후자를 통해 더 나은 언어 이해를 얻기 때문일 가능성이 크다. 추가로, ALIGN 및 CC-3M 데이터셋의 10%를 사용한 실험은 데이터 규모 확장의 중요성을 확인시켜준다. 그 다음으로, 컨볼루션 단계의 효과를 연구한 결과 VL 성능에 중요하다는 것을 발견했다. Dai et al. (2021)을 따라 ResNet Conv 블록의 첫 2/3/4개를 사용하는 실험을 한 결과, 3개 Conv 블록 설정이 가장 잘 작동함을 경험적으로 관찰했다. 이는 이미지와 텍스트가 다른 수준의 표현 세분성을 가지고 있으며, 따라서 문맥화된 패치를 활용하는 것이 유익함을 나타낸다.

5. Conclusion
이 연구에서는 간단하면서도 효과적인 vision-language 사전학습 프레임워크를 제시한다. 객체 제안 시스템과 보조 손실을 사용하는 이전 연구들과 달리, 본 연구의 모델은 전체 이미지를 패치로 처리하고 단일 접두사 언어 모델링 목표로 end-to-end로 훈련된다. 본 연구는 기존의 VLP 패러다임에 대한 유망한 대안을 제시하며, 본 연구가 생성적 VLP에 대한 미래 연구에 영감을 줄 수 있기를 바란다.



