본 글은 https://arxiv.org/abs/2301.12597 내용을 기반으로 합니다.
혹시 잘못된 부분이나 수정할 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
Abstract
큰 모델을 end-to-end 학습하는 것으로 인해 VLP 비용은 점점 증가하고 있다. 본 논문은 frozen pre-trained image encoder와 frozen LLM을 사용하여 VLP를 bootstrap하는 일반적이고 효율적인 사전학습 전략이 BLIP-2를 제안한다. BLIP-2는 two-stage로 경량 Querying Transformer를 이용해 모달리티 격차를 줄인다. first stage는 frozen image encoder로부터 vision-language representation learning을 bootstrap한다. second stage는 frozen language model로부터 vision-to-language generative learning을 bootstrap한다. BLIP-2는 다양한 task에서 적은 파라미터로 SOTA 성능을 달성한다. 자연어 instruction을 따를 수 있는 zero-shot image-to-text 생성에 대한 새로운 능력을 보여준다.
* bootstrap : 기존에 있는 자원을 사용하여 새로운 것을 시작하거나 개선하는 방법을 의미. 여기서는 기존의 사전학습된 모델을 활용해 VLP를 효과적으로 강화한다는 의미.
1. Instroduction
대부분의 state-of-the-art vision-language 모델들은 큰 규모의 모델과 데이터셋을 사용하여 end-to-end로 학습하기 때문에 사전학습 과정에서 높은 비용이 발생한다. 본 논문에서는 off-the-shelf pre-trained vision models and language models로부터 generic하고 계산 효율적인 VLP 방법을 제안한다. 계산 비용을 줄이고 catastrophic forgetting 문제를 완화하기 위해, unimodal pre-trained 모델들은 사전학습과정에서 frozen된다.
VLP를 위한 pre-trained unimodal 모델을 활용하기 위해, cross-modal alignment를 잘 맞추는 것이 핵심이다. 그러나, LLM들은 unimodal 사전학습과정에서 이미지를 보지 않기 때문에 LLM을 freeze하는 것은 vision-language alignment를 어렵게 만든다. 이와 관련하여, 기존 방법들(e.g. Flamingo)는 image-to-text generation loss에 의존하지만 이는 모달리티 격차를 줄이기에는 부족하다.
* alignment : 시각적 정보와 언어적 정보가 서로 잘 연결되고 일치하도록 만드는 것.
frozen unimodal 모델들을 사용해 vision-language alignment를 효과적으로 달성하기 위해, 새로운 two-stage pre-training 전략으로 pre-trained Querying Transformer (Q-Former)를 제안한다. Figure 1에서 볼 수 있듯이, Q-Former는 경량 transformer로 frozen image encoder로부터 visual feature를 추출하기 위해 학습가능한 query vector를 활용한다. 이는 frozen image encoder와 frozen LLM 간의 information bottleneck으로 LLM에게 원하는 text를 출력하기 위해 가장 유용한 visual feature를 제공한다. first pre-training stage에서, visual representation과 가장 관련있는 text를 학습하는 Q-Former를 강화하는 vision-language representation learning을 수행한다. second pre-training stage에서, frozen LLM에게 Q-Former의 output을 연결해줌으로써 vision-to-language generation learning을 수행하고 Q-Former의 output visual representation이 LLM에 의해 해석될 수 있도록 Q-Former를 훈련한다.
* information bottleneck : 정보 병목이라는 개념으로 시스템 내에서 정보의 흐름을 제한하거나 조절하는 역할.

본 논문의 VLP 프레임워크를 BLIP-2: Bootstrapping Language-Image Pre-training with frozen unimodal models라고 명한다. BLIP-2의 주요 장점은 다음과 같다.
- BLIP-2는 frozen pre-trained image models and language models를 효율적으로 활용한다. two-stage(representation learning stage and generative learning stage)로 사전학습된 Q-Former를 사용하여 모달리티 격차를 해소한다. BLIP-2는 visual question answering, image captioning, and image-text retrieval를 포함한 다양한 vision-language task에서 SOTA 성능을 달성한다.
- LLMs (e.g. OPT, FlanT5)에 의해 구동되는 BLIP-2는 자연어 instruction에 따라 zero-shot image-to-text generation을 수행하도록 프롬프트될 수 있으며, 이를 통해 visual knowledge reasoning, visual conversation과 같은 새로운 기능을 발휘할 수 있다(see Figure 4 for examples).
- frozen unimodal model들과 경량 Q-Former 덕분에 BLIP-2는 기존 SOTA 보다 계산 효율적이다. 예를 들어, BLIP-2는 학습가능한 파라미터를 54배 덜 쓰면서 zero-shot VQAv2에서 8.7% Flamingo를 능가한다. 추가적으로, BLIP-2는 더 나은 VLP 성능을 위해 보다 발전된 unimodal 모델들을 활용하는 범용적인 방법임을 보여준다.
2. Related Work
2.1 End-to-end Vision-Language Pre-training
vision-language pre-training은 다양한 vision-and-language task에서 성능이 향상된 multimodal foundation model 학습을 목표로 한다. downstream task에 따라, dual-encoder architecture, fusion-encoder architecture, encoder-decoder architecture를 포함한 다양한 모델 아키텍쳐가 제안되었다. 최근에는 unified transformer 아키텍쳐도 제안되었다. 다양한 pre-training objective들도 몇년동안 제안되었고 시간이 지나면서 image-text contrastive learning, image-text matching, (masked) language modeling 방법으로 수렴했다.
대부분의 VLP 방법들은 큰 규모의 image-text pair 데이터셋을 사용하여 end-to-end pre-training을 수행한다. 모델 사이즈가 증가함에 따라 사전학습은 높은 계산 비용이 발생할 수 있다. 게다가, end-to-end pre-trained 모델들은 LLM과 같이 쉽게 이용할 수 있는 unimodal pre-trained 모델들을 활용하는 것이 어렵다.
2.2 Modular Vision-Language Pre-training
off-the-shelf pre-trained 모델들을 활용하고 그것들을 VLP 과정에서 freeze하는 방법들이 본 연구와 비슷하다. 일부 방법들은 vision-to-language generation task에서 LLM의 지식을 사용하기 위해 language model을 freeze한다. frozen LLM을 사용할 때의 주요 과제는 시각적 특징을 텍스트 표현과 일치하도록 하는 것이다. 이를 달성하기 위해, 기존 방법들(Frozen, Flamingo)은 language modeling loss를 채택하고 언어 모델이 이미지 조건에 맞게 텍스트를 생성하도록 훈련된다.
기존 방법들과 다르게, BLIP-2는 다양한 vision-language task에서 낮은 계산 비용과 강한 성능을 달성하면서 효율적이고 효과적으로 frozen image encoders and frozen LLMs를 활용한다.
3. Method
frozen pre-trained unimodal 모델들로부터 bootstrap하는 새로운 vision-language pre-training 방법인 BLIP-2를 제안한다. 모달리티 격차를 해소하기 위해, two-stage에서 사전학습된 Querying Transformer (Q-Former)를 제안한다.
(1) first stage : vision-language represenation learning stage with a frozen image encoder
(2) second stage : vision-to-language generative learning stage with a frozen LLM
이 섹션에서는 먼저 Q-Former 아키텍처를 소개하고 two-stage pre-training 절차를 묘사한다.
3.1 Model Architecture
frozen image encoder와 frozen LLM 간의 격차를 해소하기 위해 학습가능한 모듈로 Q-Former를 제안한다. input image 해상도와 상관없이, image encoder로부터 고정된 output 특징들을 추출한다. Figure 2와 같이, Q-Former는 같은 self-attention layers를 공유하는 two transformer submodules가 존재한다.
(1) an image transformer that interacts with the frozen image encoder for visual feature extraction
(2) a text transformer that can function as both a text encoder and a text decoder
image transformer에 input으로 사용할 학습가능한 query embedding을 고정된 수만큼 생성한다. query들은 self-attention layers를 통해 서로 상호작용하고 cross-attention layers를 통해 frozen image features와 상호작용한다(inserted every other transformer block). query들은 추가적으로 같은 self-attention layers를 통해 text와 함께 상호작용한다. pre-training task에 따라 query-text 상호작용을 제어하기 위해 다양한 self-attention mask들을 적용한다. Q-Former를 BERT base의 사전학습도니 가중치로 초기화하고 cross-attention layer들은 랜덤하게 초기화한다. 전체적으로, Q-Former은 188M 파라미터를 가지며 query들은 모델 파라미터로 고려된다.
3.2 Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder
representation learning stage에서, frozen image encoder에 Q-Former를 연결하고 image-text pairs를 이용해 사전학습을 수행한다. query들이 text의 가장 유익한 visual representation을 추출하기 위해 학습할 수 있도록 Q-Former를 학습하는 것을 목표로 한다. BLIP에 영감을 받아, 동일한 input 형태와 모델 파라미터들을 공유하는 세 가지 pre-training objectives를 동시에 최적화한다. 각 objective는 query들과 text 간의 상호작용을 제어하기 위해, 다양한 attention masking 전략을 적용한다(see Figure 2).
Image-Text Contrastive Learning (ITC)
ITC는 이미지와 텍스트 표현간의 mutual information이 최대화하기 위해 image representation과 text representation을 align하는 방법을 학습한다. 이미지와 대응하는 텍스트(positive pair) 간의 유사성은 높이는 동시에, negative pair 간의 유사성은 낮추는 방식으로 mutual information을 최대화한다. image transformer로부터 얻은 output query representation Z를 text transformer로부터 얻은 text representation t와 align한다. 여기서 t는 [CLS] token의 output embedding이다. Z는 multiple output embeddings를 포함(one from each query)하기 때문에, 먼저 각 query output과 t 간의 pairwise 유사성을 계산한다. 그 후, image-text 유사성으로 가장 높은 것을 선택한다. information leak을 피하기 위해, query들과 text가 서로를 볼 수 없도록 unimodal self-attention mask를 적용한다. frozen image encoder를 사용하기 때문에, end-to-end 방법들에 비해 GPU 당 더 많은 샘플들을 처리할 수 있다. 그러므로, BLIP에서 momentum queue 대신에 in-batch negative를 사용한다.
* information leak: 정보 누출, 정보 유출이라는 의미로 모델의 학습 과정에서 서로 의도하지 않은 방식으로 정보가 전달되어 학습에 영향을 미치는 상황.
** 왜 query들과 text가 서로 보면 어떻게 되길래 볼 수 없도록할까? 즉, 왜 uni-modal self-attention mask를 적용하는 것일까? **
uni-modal self-attention mask를 사용해 query와 text가 서로를 보지 못하도록 설정한 이유는 서로의 정보에 의존하지 않고 독립적으로 학습하도록 하기 위해서이다.
1. information leak 방지 : 이미지와 텍스트가 각자의 정보를 독립적으로 표현하도록 하는 것이 중요하다. 만약 query와 text가 서로의 정보를 볼 수 있게 된다면, 학습이 왜곡될 가능성이 있다. 이미지 정보와 텍스트 정보를 독립적으로 학습하지 않고 서로의 정보에 지나치게 의존하게 될 수 있다. 예를 들어, image transformer가 text를 의존하면 image transformer에서 이미지 자체에서 추출해야 할 정보가 텍스트를 통해 학습되어 모델이 의존성을 가지게 된다. 결과적으로 모델이 각 모달리티를 제대로 이해하지 못하고 두 정보 사이의 연관성만 학습하게 될 위험이 있다.
2. 올바른 alignment 학습 : 이미지와 텍스트 간의 alignment를 학습하려면, 쿼리와 텍스트가 각자 고유한 방식으로 표현되고 그 표현이 독립적으로 유지되는 것이 중요하다. 이를 통해 두 모달리티를 올바르게 연결하는 방법을 배울 수 있다.
Image-grounded Text Generation (ITG)
ITG loss는 텍스트 생성을 위해 주어진 input image를 조건으로 Q-Former를 학습한다. Q-Former의 아키텍처는 frozen image encoder와 text token 간의 직접적인 상호작용을 허용하지 않기 때문에, 텍스트 생성에 필요한 정보는 query들에 의해 먼저 추출된다. 그 후, self-attention layers를 통해 text token에 전달된다. 그러므로, query들은 텍스트에 관한 모든 정보들을 포착하는 visual feature들을 추출하기 위해 집중한다. query-text 상호작용을 제어하기 위해 UniLM에서 사용한 것과 유사하게 multimodal causal self-attention mask를 적용한다. query들은 서로 attend할 수 있을 뿐만 아니라 text token에도 attend할 수 있다.각 text token은 모든 query들과 이전 text token들에 attend할 수 있다. decoding task를 알리는 첫 번째 text token으로 [DEC] token을 사용한다.
Image-Text Matching (ITM)
ITM은 이미지와 텍스트 표현 간의 fine-grained alignment를 학습하는 것을 목표로 한다. 이는 binary classification task로 모델은 image-text pair가 positive (일치) 한지 negative (비일치) 한지 예측하도록 요청받는다. 모든 query들과 텍스트들이 서로 attend할 수 있도록 bi-directional self-attention mask를 사용한다. 그러므로 output query embedding Z는 multimodal 정보를 포착한다. 로짓값을 얻기위해 각 output query embedding을 two-class linear classifier에 제공한 후, 모든 query들에 대한 로짓값을 평균화하여 output matching score를 계산한다. 유용한 negative pair를 생성하기 위해 hard negative mining strategy를 채택한다.
3.3 Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
generative pre-training stage에서 Q-Former(frozen image encoder에 부착된)를 frozen LLM에 연결하여 LLM의 언어 생성 능력을 활용한다. Figure 3에서 볼 수 있듯이, fully-connected (FC) layer를 사용하여 output query embeddings Z를 LLM의 text embedding에 같은 차원으로 선형 변환한다. 선형 변환된 query embedding들은 input text embedding 앞에 추가된다. 이들은 LLM이 Q-Former에 의해 추출된 visual representation을 기반으로 동작하도록 soft visual prompt로 기능을 한다. Q-Former는 언어 정보가 포함된 visual representation을 추출하도록 사전학습되기 때문에, 관련없는 시각적 정보를 제거하면서 LLM에게 가장 유용한 정보를 제공하는 information bottleneck으로서 효과적으로 작동한다. 이는 vision-language alignment를 학습시키는 LLM의 부담을 감소시켜 catastrophic forgetting 문제를 완화한다.
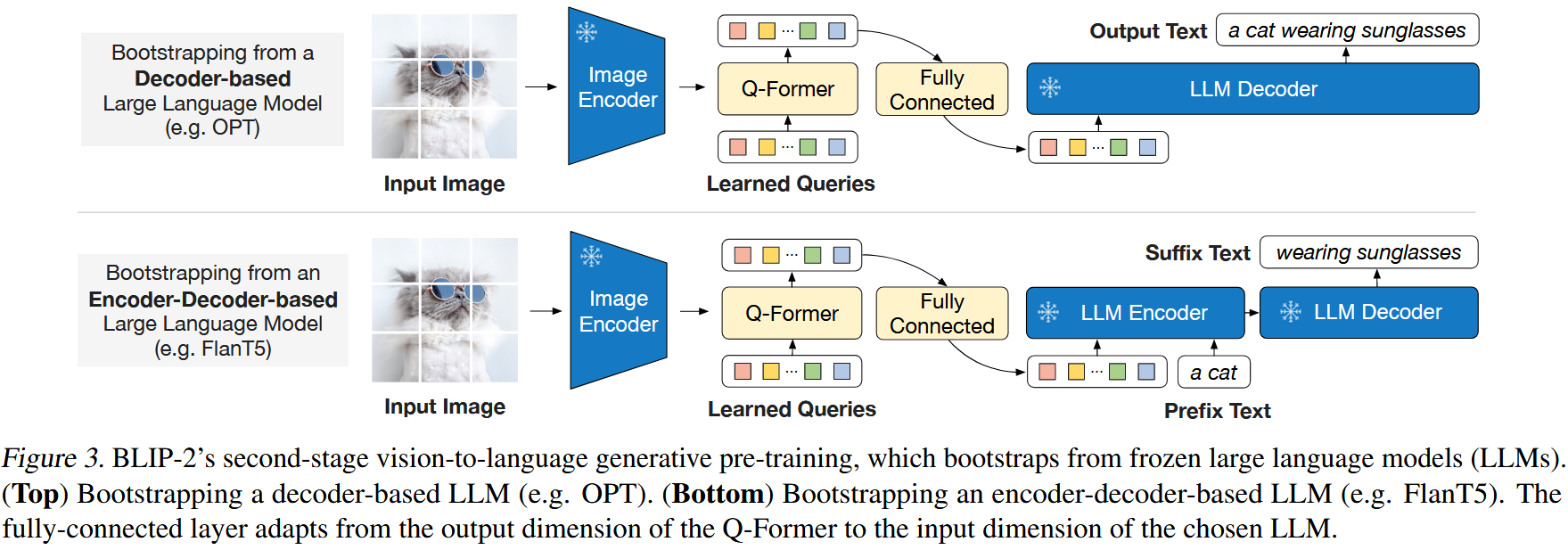
두 가지 유형의 LLMs(decoder-based LLMs and encoder-decoder-based LLMs)를 실험한다. decoder-based LLMs의 경우, language modeling loss로 사전학습하고 여기서 frozen LLM은 Q-Former로부터 얻은 visual representation를 바탕으로 텍스트를 생성하는 task를 수행한다. encoder-decoder-based LLMs의 경우, prefix language modeling loss로 사전학습하고 여기서 텍스트를 두 파트로 분할한다. prefix text는 LLM's encoder에 input으로 visual representation과 함께 연결된다. suffix text는 LLM의 디코더에 생성 타겟으로 사용된다.
3.4 Model Pre-training
Pre-training data.
COCO, Visual Genome, CC3M, CC12M, SBU, and 115M images from LAION400M dataset을 포함하여 총 129M 이미지들로 BLIP pre-training dataset과 동일하게 사용한다. 웹 이미지들로부터 synthetic caption들을 생성하기 위해 CapFilt 방법을 채택한다. 구체적으로, BLIP large captioning model을 사용하여 10개의 캡션을 생성한다. 그리고 CLIP ViT-L/14 모델이 계산한 image-text similarity를 기반으로 original web caption과 함께 synthetic caption에 대해 순위를 매긴다. 이미지 당 top-two captions를 훈련 데이터로 유지하고 각 pre-training step마다 랜덤하게 하나를 샘플링한다.
Pre-trained image encoder and LLM.
frozen image encoder의 경우, 두 가지 SOTA pre-trained vision transformer 모델들을 사용한다.
(1) ViT-L/14 from CLIP
(2) ViT-g/14 from EVA-CLIP
ViT의 마지막 layer를 제거하고 마지막에서 두 번째 layer의 output features를 사용한다. 이는 성능이 약간 향상된다. frozen language model의 경우, decoder-based LLMs에서는 unsupervised-trained OPT model family를 사용하고 encoder-decoder-based LLMs에서는 instruction-trained FlanT5 model family를 사용한다.
Pre-training settings.
first stage에서 250k step, second stage에서 80k step을 사전학습한다. first stage에서 ViT-L/ViT-g에 대해 2320/1680 batch size를 사용하고 second stage에서 OPT/FlanT5에 대해 1920/1520 batch size를 사용한다. 사전학습 과정에서, FlanT5를 제외한 frozen ViTs와 LLMs의 파라미터를 FP16으로 변환하고 FlanT5의 경우에는 BFloat16을 사용한다. 32-bit 모델을 사용하는 것과 비교해도 성능 저하가 없었다는 것을 발견했다. frozen model을 사용하기 때문에, 사전학습은 기존 large-scale VLP 방법들보다 계산 친화적이다. 예를 들어, 단일 16-A100(40G) machine을 사용하는 ViT-g 및 FlangT5-XXL을 갖춘 본 논문의 가장 큰 모델은 first stage에서 6일 미만, second stage에서 3일 미만이 소요된다. (GPT-3 175B 모델은 V100 GPU로 학습하면 약 288년.. 3072개의 A100 GPU로 end-to-end로 학습하면 84일.. 걸린다고 한다. feat by. "Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM" paper)
* FP16은 Float16(16-bit floating-point)로 16비트 부동소수점이다. FP16은 주로 딥러닝 모델의 학습과 추론 과정에서 메모리를 절감하고 더 빠른 연산을 위해 사용된다.
* BFloat16(Brain Floating Point 16-bit)은 Google에서 개발한 16비트 부동소수점 형식으로 FP16과 유사한 메모리 절감 효과를 제공하면서도 더 넓은 표현 범위를 갖는 것이 특징이다.
* FlanT5에서는 BFloat16의 안전성을 활용하여 텍스트 생성에서 긴 문맥을 처리하고 오버플로우나 언더플로우를 줄이기 위해 BFloat16을 사용하지만 다른 모델에서는 Float16의 더 높은 정밀도와 하드웨어 효율성을 활용하는 것이 더 적합할 수 있다.
4. Experiment
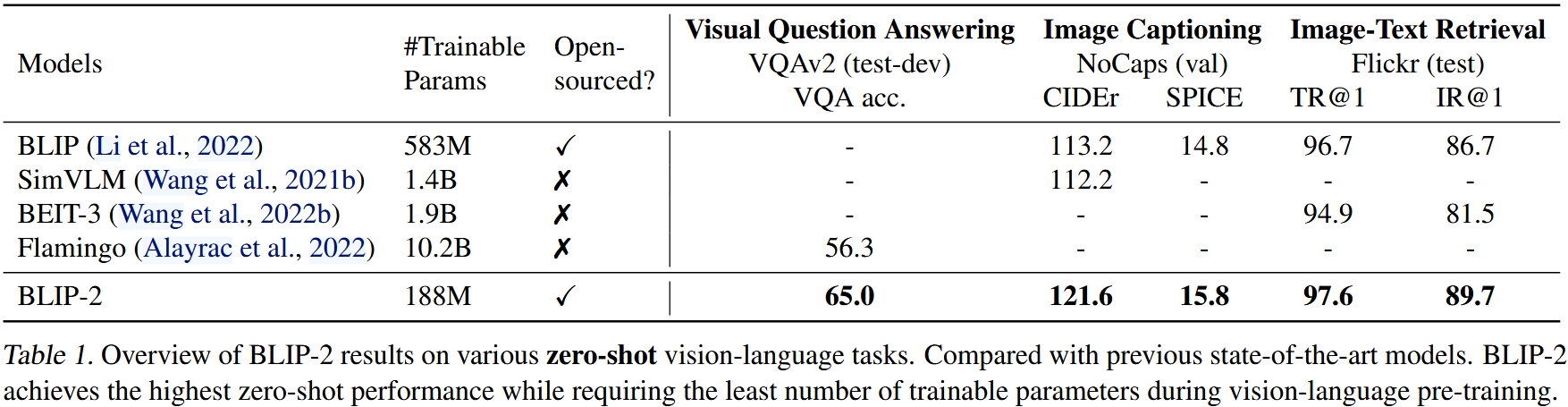
Table 1은 다양한 zero-shot vision-language task에서 BLIP-2의 전체적인 성능을 제공한다. 이전 SOTA 모델들과 비교했을 때, BLIP-2는 vision-language 사전학습과정에서 학습가능한 파라미터 수가 훨씬 적으면서 향상된 성능을 달성한다.
4.1 Instructed Zero-shot Image-to-Text Generation
BLIP-2는 LLM이 이미지를 이해하면서 텍스트 프롬프트를 따르는 능력을 유지하도록 하여 instruction과 함께 image-to-text generation을 제어할 수 있게한다. 간단하게 LLM의 input으로 visual prompt 뒤에 text prompt를 추가한다. Figure 4는 visual knowledge reasoning, visual commensense reasoning, visual conversation, personalized image-to-text generation 등을 포함한 다양한 zero-shot image-to-text 능력들을 보여주는 예시들이다.
Zero-shot VQA.
zero-shot visual question answering task에서 정량적인 평가를 수행한다. OPT 모델들의 경우, "Question: {} Answer:" prompt를 사용한다. FlanT5 모델들의 경우, "Question: {} Short answer:" prompt를 사용한다. generation 과정에서 beam width는 5로 하여 beam search를 사용한다. length-penalty를 -1로 설정하여 human annotation과 더 잘 맞게 짧은 답변을 생성하도록 유도한다.
Table 2에서 볼 수 있듯이, BLIP-2는 VQAv2 및 GQA dataset에서 SOTA 성능을 달성한다. VQAv2에서 Flamingo80B 모델보다 학습가능한 파라미터를 54배 줄이면서 8.7% 능가한다. OK-VQA dataset에서 BLIP-2는 Flamingo80B에 이어 두 번째로 성능이 좋다. 이는 OK-VQA가 visual understanding보다 open-world knowledge에 더 중점을 두고 Flamingo80B의 70B Chinchilla 언어 모델이 11B FlanT5XXL보다 더 많은 지식을 보유하고 있기 때문이라고 가정한다.
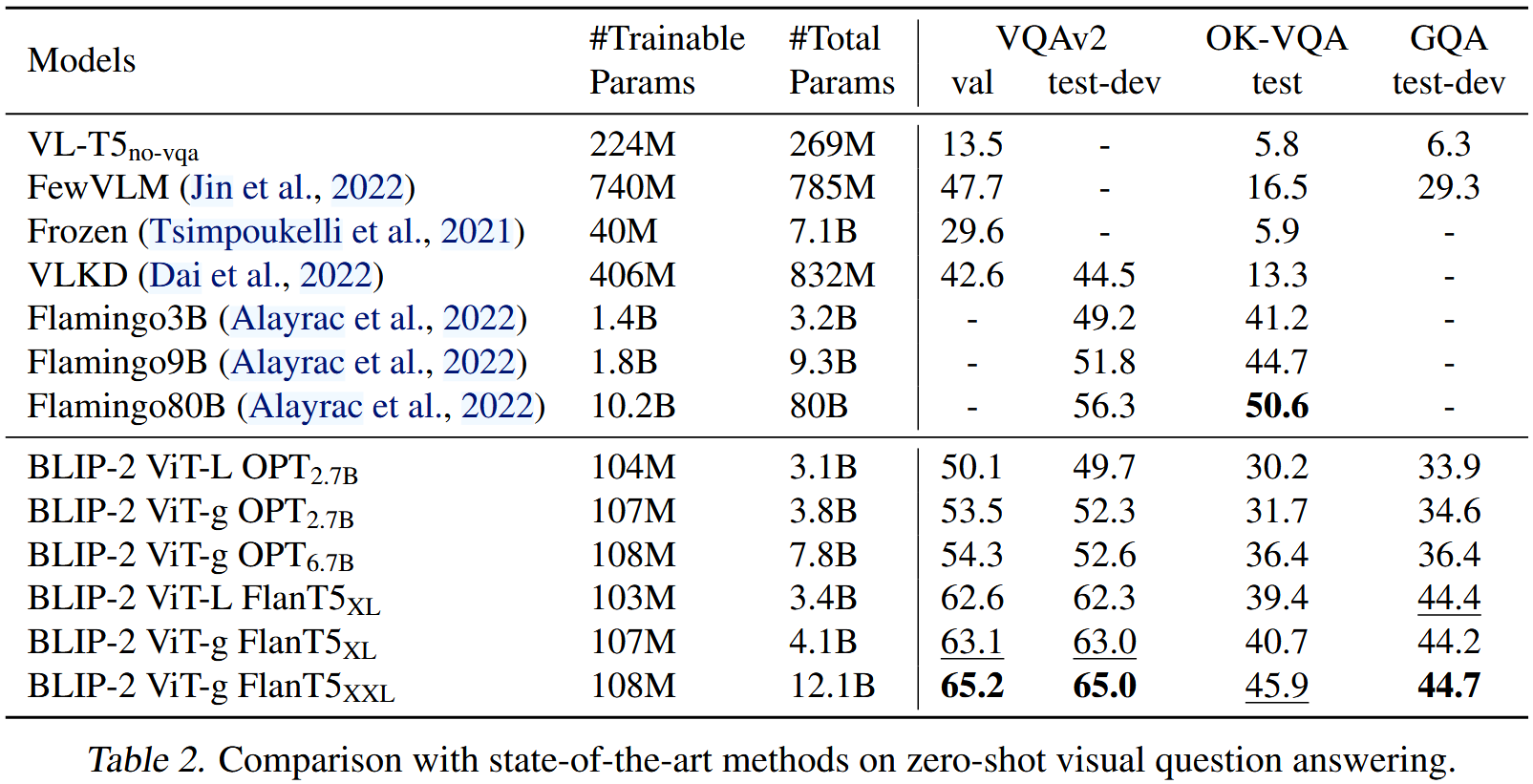
Table 2에서 더 강력한 image encoder 혹은 더 강력한 LLM을 사용할수록 더 좋은 성능을 이끈다는 유망한 관찰을 하였다.
* 더 좋은 image encoder or LLM을 사용하는 것은 당연히 더 좋은 성능을 이끄는 것 아닐까? 이걸 왜 유망한 관찰이라고 표현..? => BLIP-2의 구조가 향후 기술 발전과 호환되어 성능을 확장할 수 있는 가능성을 보여줌.
- 성능 개선의 일관된 영향 확인 : 더 강력한 모델을 사용한 결과가 일관되게 성능 향상으로 이어진다는 것은 이 모델 구조가 성능 확장에 잘 대응할 수 있음을 보여준다. 즉, 향후 더 강력한 인코더나 LLM이 개발되면 이 아키텍처에 적용하면 성능이 안정적으로 더 좋아질 것이라는 기대를 증명.
- 기존 접근법과 차별화된 아키텍처 확인 : 기존 VLP 모델들은 end-to-end 방식으로 학습하지만, BLIP-2는 frozen 모델을 사용하는 아키텍처로 frozen 모델 구조에서도 더 강력한 모듈을 적용하면 성능이 향상된다는 것은 이 아키텍처가 성능 확장을 위한 유연성을 갖고 있음을 보여주는 유망한 가능성.
- 향후 연구 개발의 가능성 : 더 강력한 모듈을 사용할수록 성능이 좋아지는 경향은 BLIP-2의 구조가 새로운 이미지 인코더나 LLM의 발전에 맞춰 쉽게 성능을 개선할 수 있는 잠재력이 있음을 시사. 즉, BLIP-2 아키텍처가 다양한 task에서 더 높은 성능을 추구할 수 있는 가능성을 제시하는 유망한 결과.
=> 당연하다고 생각하는 것도 한 번 더 공부해보기..ㅎ
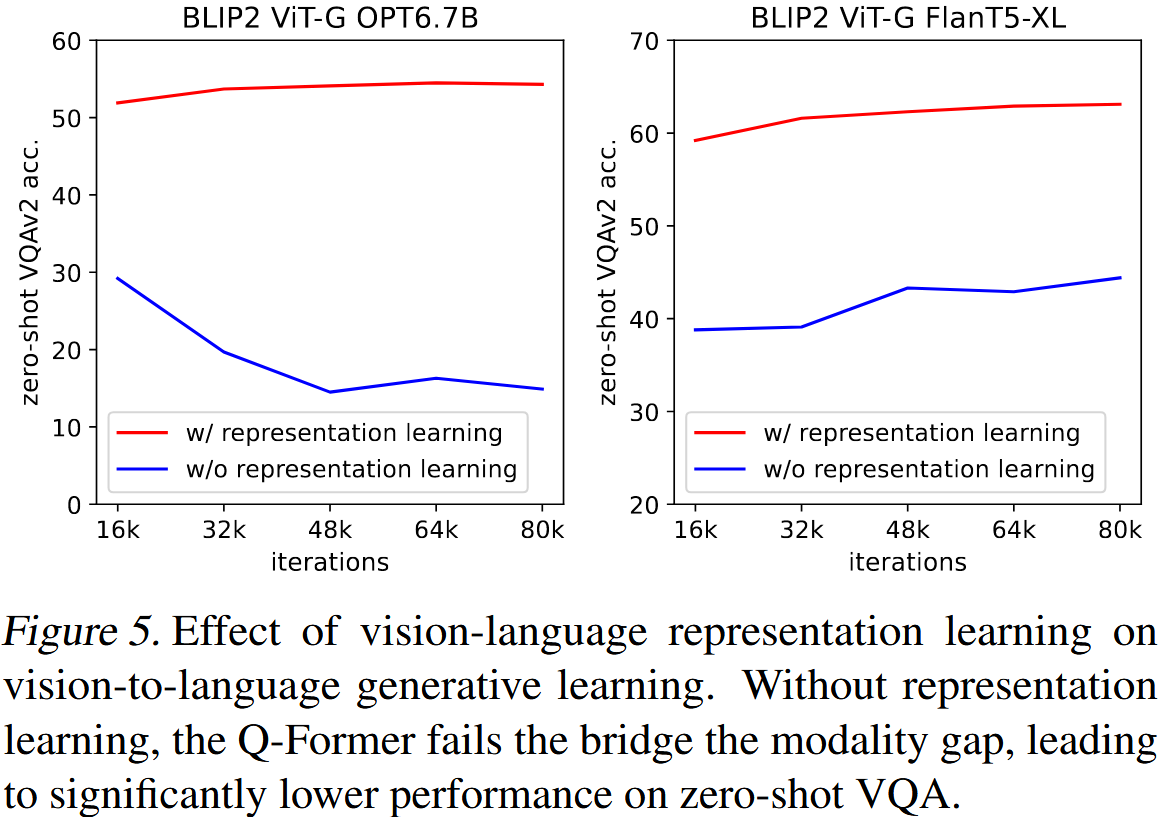
Effect of Vision-Language Representation Learning.
first-stage representation learning은 text와 관련된 visual features를 학습하기 위해 Q-Former를 사전학습하므로 vision-language alignment를 학습하는 데 있어 LLM의 부담을 감소시켜준다. representation learning stage가 없는 Q-Former는 모달리티 격차를 해소하기 위해 vision-to-language generative learning에만 의존한다. Figure 5는 generative learning에서 representation learning의 효과를 보여준다. representation learning 없이, 두 유형의 LLMs는 zero-shot VQA에서 훨씬 낮은 성능을 보여준다. 특히, OPT는 학습이 진행됨에 따라 성능이 급격히 저하되는 catastrophic forgetting으로 고통을 받는다.
4.2 Image Captioning
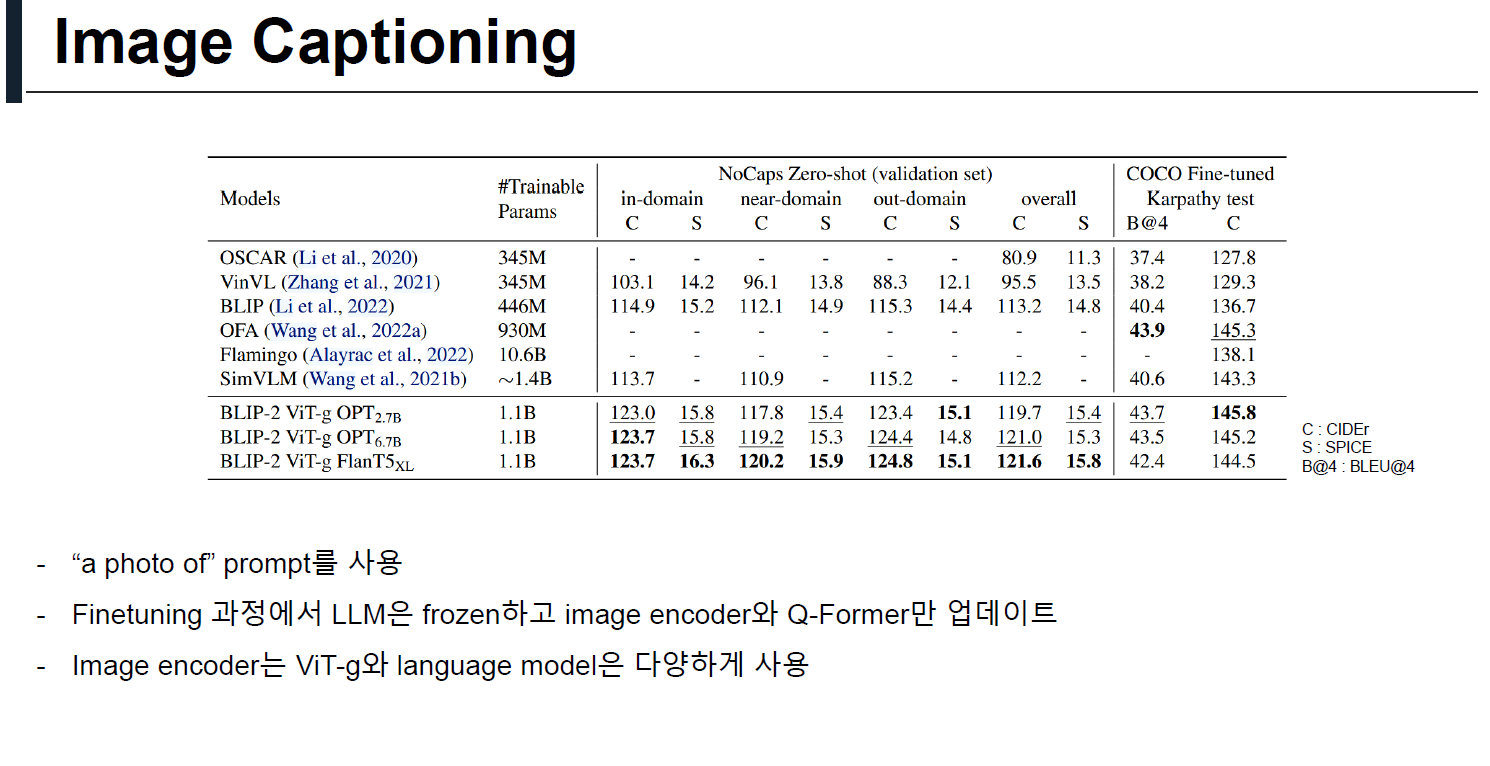
4.3 Visual Question Answering
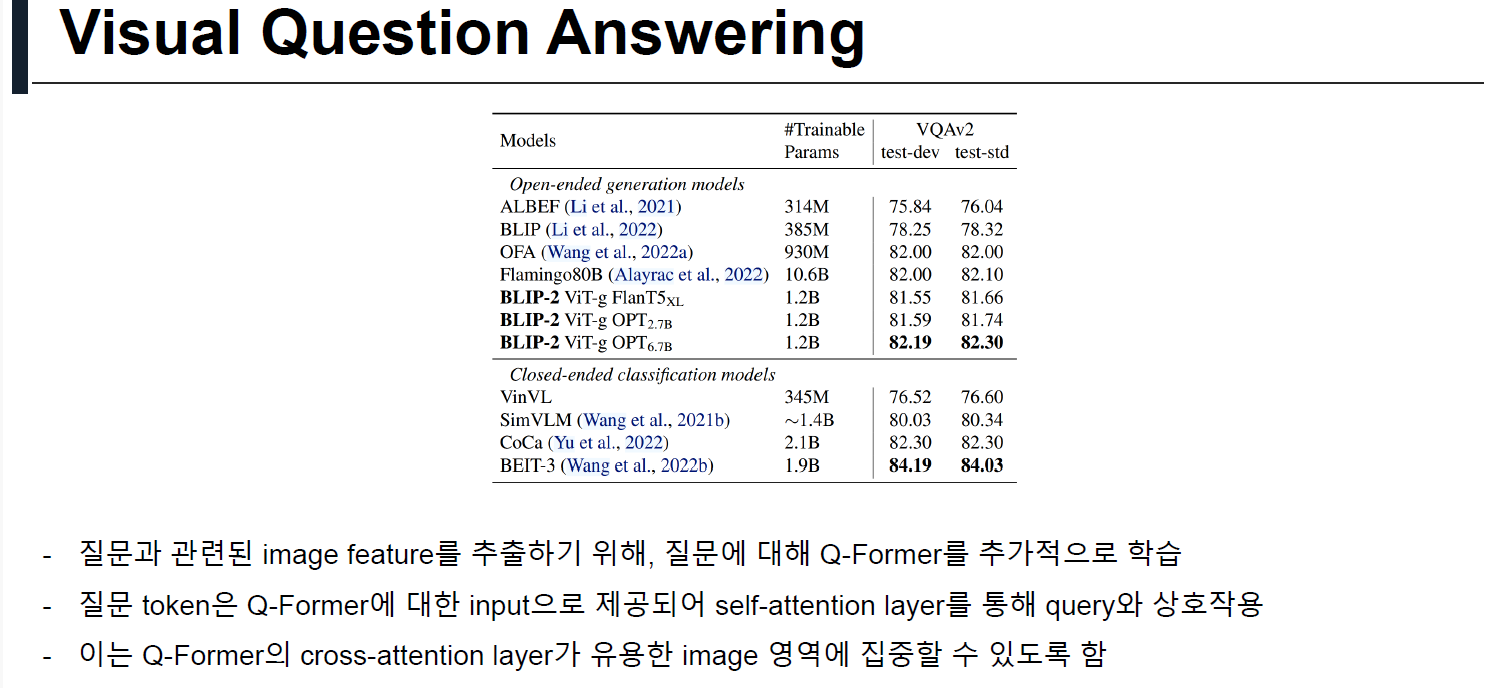
4.4 Image-Text Retrieval
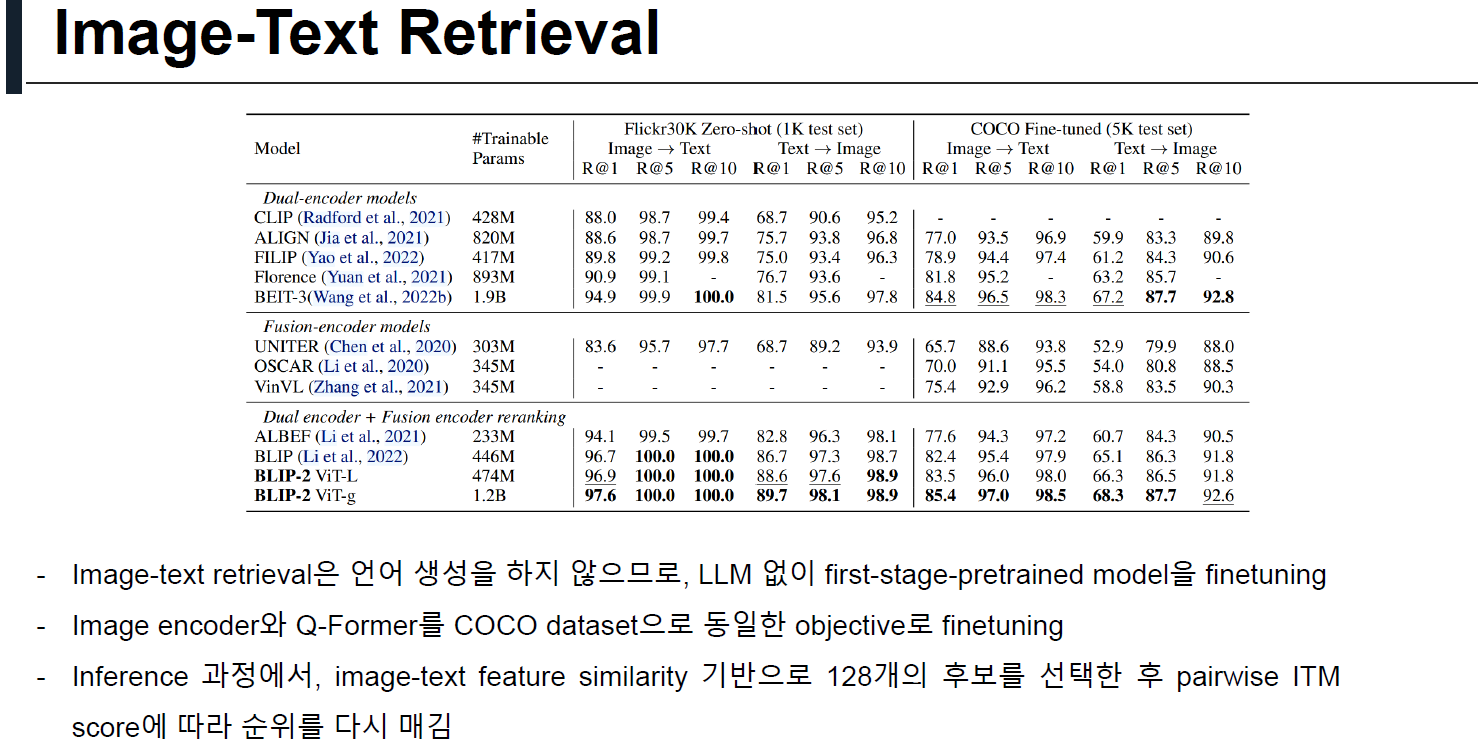
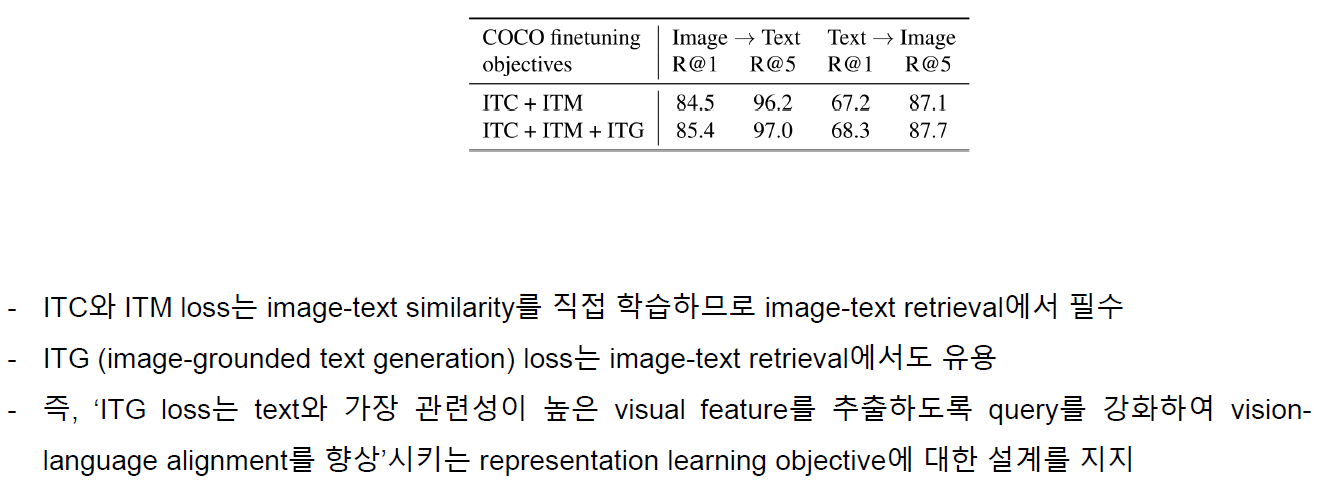
5. Limitation

6. Conclusion
- Vision-language pre-training을 위한 범용적이고 계산 효율적인 방법인 BLIP-2를 제안
- BLIP-2는 작은 양의 학습가능한 파라미터로 다양한 vision-language task에서 SOTA 성능 달성
- Zero-shot instructed image-to-text generation 능력을 보여줌
'Paper Review > Multi-modal' 카테고리의 다른 글
| [Paper Review] Improved Baselines with Visual Instruction Tuning (2) | 2024.11.21 |
|---|---|
| [Paper Review] Visual Instruction Tuning (4) | 2024.11.08 |
| [Paper Review] Flamingo: a Visual Language Model for Few-Shot Learning (3) | 2024.08.30 |
| [Paper Review] SimVLM: Simple Visual Language Model Pretraining with Weak Supervision (0) | 2024.08.02 |
| [Paper Review] Zero-Shot Text-to-Image Generation (0) | 2024.07.28 |



