본 글은 https://arxiv.org/abs/2107.07651 내용을 기반으로 합니다.
혹시 잘못된 부분이나 수정할 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
Abstract
대규모 비전과 언어 표현 학습은 다양한 vision-language task에서 유망한 개선을 보여주었다. 대부분의 기존 방법들은 시각적 토큰(영역 기반 이미지 특징)과 단어 토큰들을 같이 모델링하기 위해 transformer 기반의 multimodal 인코더를 사용한다. 시각적 토큰과 단어 토큰이 정렬되지 않기 때문에, multimodal 인코더가 image-text 상호작용을 학습하는 것은 도전적이다. 본 논문에서는 cross-modal attention을 통해 이미지와 텍스트 표현을 융합하기 전에 contrastive loss를 도입하여 정렬을 하는 ALBEF(ALign Before Fusing)을 제안한다. 이를 통해 더 근거 있는 비전과 언어 표현 학습을 가능하게 한다. 대부분의 기존 방법과 달리, 본 방법은 bounding box 주석이나 고해상도 이미지를 필요로 하지 않는다. 노이즈가 있는 웹 데이터로부터 학습을 개선하기 위해, 모멘텀 모델에 의해 생성된 가상 목표로부터 학습하는 자체 훈련 방법인 모멘텀 증류를 제안한다. ALBEF를 상호 정보 최대화 관점에서 이론적으로 분석하며 서로 다른 훈련 task가 이미지-텍스트 쌍에 대한 뷰를 생성하는 다양한 방법으로 해석될 수 있음을 보여준다. ALBEF는 여러 downstream vision-language task에서 SOTA 성능을 달성한다. 이미지-텍스트 검색에서 ALBEF가 훨씬 더 큰 데이터셋에서 사전 훈련된 방법을 능가한다. VQA와 NLVR2에서는 각각 2.37%와 3.84%의 절대적인 향상을 달성하며 더 빠른 추론 속도를 자랑한다.
1. Introduction
Vision-and-Language Pre-training (VLP)는 대규모 이미지-텍스트 쌍으로부터 multimodal 표현을 학습하여 Vision-and-Language (V+L) task를 개선하는 것을 목표로 한다. 대부분의 기존 VLP 방법(e.g., LXMERT, UNITER, OSCAR)들은 사전 학습된 object detector를 사용하여 영역 기반 이미지 특징을 추출하고 multimodal 인코더를 사용하여 이미지 특징과 단어 토큰을 융합한다. multimodal 인코더는 이미지와 텍스트를 공동 이해를 요구하는 task(예: masked language modeling (MLM)과 image-text matching (ITM))를 해결하도록 훈련된다.
이러한 VLP 프레임워크는 효과적이지만 몇 가지 주요 한계점이 있다.
(1) 이미지 특징과 단어 토큰 임베딩이 각각의 공간에 존재하여 multimodal 인코더가 상호작용을 모델링하기 어렵다.
(2) object detector는 주석과 계산 자원이 많이 소요되며, 사전 학습 과정에서 bounding box 주석이 필요하고 추론 중 고해상도 이미지(예: 600 x 1000)가 필요하다.
(3) 널리 사용되는 이미지-텍스트 데이터셋들은 웹에서 수집되며 본질적으로 노이즈가 많아 MLM과 같은 기존 사전학습 objective가 텍스트에 과적합하여 모델의 일반화 성능을 저하시킬 수 있다.
이러한 한계점을 해결하기 위해 새로운 VLP 프레임워크인 ALign BEfore Fuse (ALBEF)를 제안한다. 먼저, object detector가 없는 이미지 인코더와 텍스트 인코더를 사용하여 이미지와 텍스트를 독립적으로 인코딩한다. 그 후, multimodal 인코더를 사용하여 cross-modal attention을 통해 이미지 특징과 텍스트 특징을 융합한다. 단일모달 인코더의 표현에서 image-text contrastive (ITC) loss를 도입하여 세 가지 목적을 달성한다.
(1) 이미지 특징과 텍스트 특징을 정렬하여 multimodal 인코더가 cross-modal 학습을 수행하기 쉽게 한다.
(2) 단일모달 인코더가 이미지와 텍스트의 의미를 더 잘 이해하도록 개선한다.
(3) 이미지와 텍스트를 임베딩할 저차원 공간을 학습하여 contrastive hard negative mining을 통해 유용한 샘플을 찾을 수 있도록 한다.
노이즈가 있는 감독 하에서 학습을 개선하기 위해 Momentum Distillation (MoD)를 제안한다. 이 간단한 방법은 모델이 더 큰 비정제 웹 데이터셋을 활용할 수 있게 한다. 훈련 과정에서 모델의 파라미터 이동 평균을 취하여 모멘텀 버전을 유지하고, 추가 감독으로 가상 타겟을 생성하는 데 모멘텀 모델을 사용한다. MoD를 사용하면 웹 주석과 다른 다른 합리적인 출력들을 생성하는 것에 대해 모델이 벌을 받지 않는다. MoD는 사전 학습뿐만 아니라 깨끗한 주석이 있는 downstream task에서도 성능을 향상시킨다.
상호 정보 최대화 관점에서 ALBEF를 이론적으로 정당화한다. 구체적으로, ITC와 MLM이 이미지-텍스트 쌍의 서로 다른 뷰 간의 상호 정보에 대한 하한을 최대화한다는 것을 보여준다. 여기서 뷰는 각 쌍에서 부분 정보를 취하여 생성된다. 이러한 관점에서 모멘텀 증류는 의미론적으로 유사한 샘플로 새로운 뷰를 생성하는 것으로 해석될 수 있다. 따라서 ALBEF는 의미 보존 변환에 불변인 비전-언어 표현을 학습한다.
이미지-텍스트 검색, 시각적 질의 응답, 시각적 추론, visual entailment, weakly-supervised visual grounding을 포함한 다양한 downstream V+L task에서 ALBEF의 효과를 입증한다. ALBEF는 기존 SOTA 방법들에 비해 상당한 개선을 달성한다. 이미지-텍스트 검색에서 ALBEF는 훨씬 더 큰 데이터셋에서 사전 학습된 방법(CLIP과 ALIGN)을 능가한다. VQA와 NLVR2에서는 SOTA 방법인 VILLA에 비해 각각 2.37%와 3.84%의 절대적인 향상을 달성하며 더 빠른 추론 속도를 자랑한다. 또한, Grad-CAM을 사용한 정량적 및 정성적 분석을 통해 ALBEF의 객체, 속성 및 관계 그라운딩 능력을 명확히 드러낸다.
2. Related Work
2.1 Vision-Language Representation Learning
비전-언어 표현 학습에 관한 대부분의 기존 연구들은 두 가지 범주로 나뉜다. 첫 번째 범주는 transformer 기반 multimodal 인코더를 사용하여 이미지와 텍스트 특징 간의 상호작용을 모델링하는 데 중점을 둔다. 이 범주에 속하는 방법들은 이미지와 텍스트에 대한 복잡한 추론을 요구하는 downstream V+L task(NLVR2, VQA)에서 우수한 성능을 보이지만, 대부분 고해상도 input 이미지와 사전 학습된 object detector가 필요하다. 최근의 한 방법은 object detector를 제거하여 추론 속도를 개선했지만, 성능은 낮아졌다. 두 번째 범주는 이미지와 텍스트에 대해 별도의 단일모달 인코더를 학습하는 데 중점을 둔다. 최근의 CLIP과 ALIGN은 대규모 노이즈가 많은 웹 데이터에서 contrastive loss를 사용하여 사전 학습을 수행하였으며, 이는 표현 학습을 위한 가장 효과적인 loss 중 하나이다. 이들은 이미지-텍스트 검색 task에서 뛰어난 성능을 보이지만, 다른 V+L task에서 이미지와 텍스트 간의 더 복잡한 상호작용을 모델링하는 능력이 부족하다.
ALBEF는 두 가지 범주를 통합하여 검색 및 추론 task에서 뛰어난 성능을 보이는 강력한 단일모달 및 멀티모달 표현을 제공한다. 또한, ALBEF는 많은 기존 방법에서 주요 계산 병목 현상인 object detector를 필요로 하지 않는다.
2.2 Knowledge Distillation
지식 증류는 일반적으로 학생 모델의 예측을 교사 모델의 예측과 일치시킴으로써 학생 모델의 성능을 향상시키는 것을 목표로 한다. 대부분의 방법들은 사전 학습된 교사 모델로부터 지식을 증류하는 데 중점을 두지만, 온라인 증류는 여러 모델을 동시에 훈련하고 이들의 앙상블을 교사로 사용한다. 모멘텀 증류는 학생 모델의 시간적 앙상블 교사로 사용하는 온라인 자기 증류의 한 형태로 해석될 수 있다. 유사한 아이디어는 semi-supervised learning, label noise learning 그리고 최근의 contrastive learning에서 탐구되었다. 기존 연구와 달리, 모멘텀 증류가 많은 V+L task에서 모델의 성능을 향상시킬 수 있는 일반적인 학습 알고리즘임을 이론적으로 및 실험적으로 보여준다.
3. ALBEF Pre-training
이 섹션에서는 먼저 모델 아키텍처를 소개한다 (Section 3.1). 그런 다음 사전 학습 objective를 설명하고 (Section 3.2), 제안된 모멘텀 증류를 설명한다 (Section 3.3). 마지막으로 사전 학습 데이터셋 (Section 3.4)과 구현 세부 사항 (Section 3.5)을 설명한다.
3.1 Model Architecture
Figure 1에서 볼 수 있듯이, ALBEF는 이미지 인코더, 텍스트 인코더, 그리고 멀티모달 인코더로 구성된다. 이미지 인코더로 12개의 레이어를 가진 visual transformer ViT-B/16을 사용하며, ImageNet-1k에서 사전 학습된 가중치로 초기화한다. input 이미지 I는 {vcls, v1, ..., vN}의 임베딩 시퀀스로 인코딩되며, 여기서 vcls는 [CLS] 토큰 임베딩이다. 텍스트 인코더와 멀티모달 인코더에는 각각 6개의 레이어를 가진 transformer를 사용한다. 텍스트 인코더는 BERT base 모델의 첫 6개 레이어를 사용하여 초기화하고 멀티모달 인코더는 BERT base의 마지막 6개 레이어를 사용하여 초기화한다. 텍스트 인코더는 input 텍스트 T를 {wcls, w1, ..., wN}의 임베딩 시퀀스로 변환하며 이는 멀티모달 인코더에 입력된다. 이미지 특징은 멀티모달 인코더의 각 레이어에서 cross attention을 통해 텍스트 특징과 융합된다.

3.2 Pre-training Objectives
ALBEF를 세 가지 objective로 사전 학습한다. 세 가지 objective는 단일모달 인코더에서의 image-text contrastive learning (ITC), 멀티모달 인코더에서의 masked language modeling (MLM) 및 image-text matching (ITM)이다. 그리고 online contrastive hard negative mining으로 ITM을 개선한다.
Image-Text Contrastive Learning 은 융합 전 더 나은 단일모달 표현을 학습하는 것을 목표로 한다. 이는 유사도 함수 s를 학습하여 병렬 이미지-텍스트 쌍이 더 높은 유사도 점수를 갖도록 한다. gv와 gw는 [CLS] 임베딩을 정규화된 저차원(256차원) 표현으로 매핑하는 선형 변환이다. MoCo에서 영감을 받아, 모멘텀 단일모달 인코더에서 가장 최근의 M 이미지-텍스트 표현을 저장하기 위해 두 개의 큐를 유지한다. 모멘텀 인코더의 정규화된 특징은 g'v 및 g'w로 표시된다.
각 이미지와 텍스트에 대해 softmax 정규화된 이미지-텍스트 및 텍스트-이미지 유사도를 다음과 같이 계산한다.
yi2t(I)와 yt2i(T)는 negative 쌍이 0의 확률을 가지고 positive 쌍이 1의 확률을 가지는 ground-truth one-hot similarity를 나타낸다. 이미지-텍스트 contrastive loss는 p와 y 간의 cross-entropy H로 정의된다.
Masked Language Modeling 은 이미지를 사용하여 텍스트와 함께 마스킹된 단어를 예측한다. 입력 토큰의 15%를 무작위로 마스킹하고 special token [MASK]로 대체한다. T^는 마스킹된 텍스트를 나타내며 pmsk(I, T^)는 마스킹된 토큰에 대한 모델의 예측 확률을 나타낸다. MLM은 cross-entropy loss를 최소화한다.
여기서 ymsk는 정답 토큰이 1의 확률을 가지는 원-핫 어휘 분포이다.
Image-Text Matching 은 이미지와 텍스트 쌍이 positive(매칭되는지)인지 negative(매칭되지 않는지)인지 예측한다. 이미지-텍스트 쌍의 공동 표현으로 멀티모달 인코더의 [CLS] 토큰의 출력 임베딩을 사용하여 fully-connected (FC) layer와 softmax를 추가하여 두 가지 클래스 확률 pitm을 예측한다. ITM loss는 다음과 같다.
여기서 yitm은 정답 레이블을 나타내는 2차원 원-핫 벡터이다.
ITM task를 위해 hard negative 샘플링 전략을 제안한다. 이미지-텍스트 쌍은 유사한 의미를 공유하지만 세세한 세부 사항이 다른 경우 negative 이미지-텍스트 쌍은 어렵다. contrastive 유사성을 사용하여 배치 내 hard negative를 찾는다. 미니 배치의 각 이미지에 대해, 이미지와 더 유사한 텍스트가 샘플링될 확률이 높은 contrastive 유사도 분포에 따라 동일한 배치에서 하나의 negative 텍스트를 생플링한다. 마찬가지로, 각 텍스트에 대해 하나의 hard negative 이미지도 샘플링한다.
ALBEF의 full 사전 학습 objective는 다음과 같다.
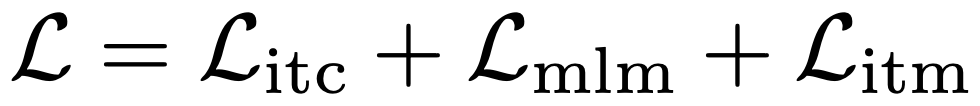
3.3 Momentum Distillation
사전 학습에 사용되는 이미지-텍스트 쌍은 대부분 웹에서 수집되며 이들은 노이즈가 많다. positive 쌍은 보통 약하게 연관되어 있으며 텍스트에는 이미지와 관련 없는 단어가 포함될 수 있고 이미지에는 텍스트에 설명되지 않은 개체가 포함될 수 있다. ITC 학습의 경우, 이미지에 대한 negative 텍스트도 이미지의 내용과 일치할 수 있다. MLM의 경우, 주석과 다른 단어가 이미지를 똑같이 잘 (또는 더 잘) 설명할 수 있다. 그러나 ITC와 MLM의 원-핫 레이블은 부정 예측의 정확성에 관계없이 모두 벌을 준다.
이를 해결하기 위해, 모멘텀 모델이 생성한 가상 목표로부터 학습할 것을 제안한다. 모멘텀 모델은 지수 이동 평균 버전의 단일모달 및 멀티모달 인코더로 구성된 지속적으로 진화하는 교사이다. 훈련 과정에서 기본 모델의 예측이 모멘텀 모델의 예측과 일치하도록 훈련한다. 구체적으로, ITC의 경우 모멘텀 단일모달 인코더의 특징을 사용하여 이미지-텍스트 유사도를 계산한다.
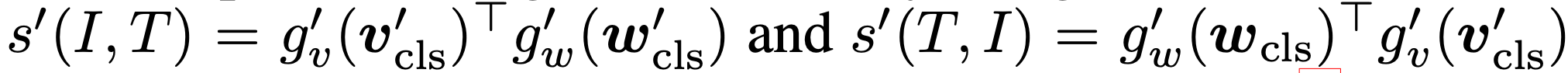
그런 다음, 식 1에서 s를 s'로 대체하여 soft 가상 목표 qi2t 및 qt2i를 계산한다. ITCMoD loss는 다음과 같이 정의된다.
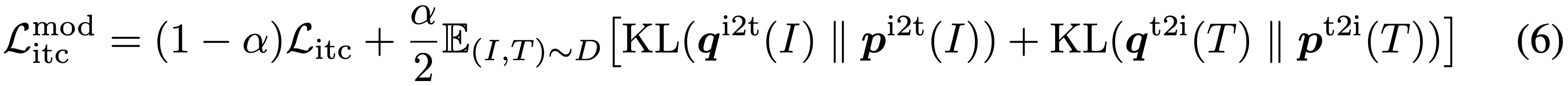
마찬가지로, MLM의 경우 qmsk(I, T^)를 모멘텀 모델의 마스킹된 토큰에 대한 예측 확률로 나타내면 MLMMoD loss는 다음과 같다.
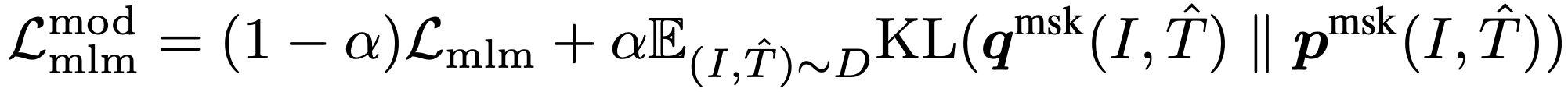
Figure 2에서 가상 목표에서 상위 5개의 후보 예제를 보여주며 이는 이미지에 대한 관련 단어/텍스트를 효과적으로 캡처한다. 더 많은 예제는 부록에서 볼 수 있다.

downstream task에도 MoD를 적용한 다. 각 task의 최종 loss는 원래 task의 loss와 모델의 예측과 가상 목표 간의 KL-divergence의 가중 조합이다. 간단히 하기 위해, 모든 사전 학습 및 downstream task에 대해 가중치 알파를 0.4로 설정한다.
3.4 Pre-training Datasets
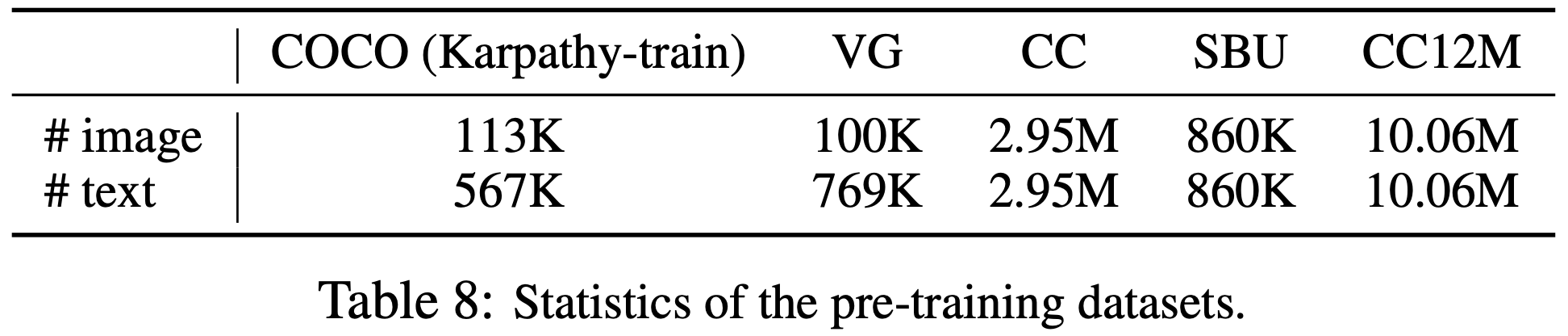
UNITER를 따르며, 두 개의 웹 데이터셋(Conceptual Captions, SBU Captions)과 두 개의 도메인 내 데이터셋(COCO 및 Visual Genome)을 사용하여 사전 학습 데이터를 구성한다. 고유 이미지의 총 수는 4.0M이며 이미지-텍스트 쌍의 수는 5.1M이다. 본 논문의 방법이 더 큰 규모의 웹 데이터로 확장 가능함을 보여주기 위해, 훨씬 더 많은 노이즈가 있는 Conceptual 12M 데이터셋도 포함하여 총 이미지 수를 14.1M로 늘린다. 자세한 내용은 부록에 있다.
3.5 Implementation Details
본 논문의 모델은 123.7M 개의 파라미터를 가진 BERT base와 85.8M 개의 파라미터를 가진 ViT-B/16으로 구성된다. 8개의 NVIDIA A100 GPU에서 배치 크기 512로 30 epoch동안 모델을 사전 학습한다. AdamW optimizer를 사용하며 가중치 감쇠는 0.02로 설정한다. 학습률은 처음 1000번 반복동안 1e-4까지 웜업되고 이후 코사인 스케줄을 따라 1e-5로 감소한다. 사전 학습 동안 해상도 256x256의 무작위 이미지 크롭을 입력으로 사용하고 RandAugment를 적용한다. finetuning 동안에는 이미지 해상도를 384x384로 증가시키고 이미지 패치의 positional encoding을 보간한다. 모멘텀 모델 업데이트를 위한 모멘텀 매개변수는 0.995로 설정하고 이미지-텍스트 contrastive learning을 위한 queue의 크기는 65,536으로 설정한다. 증류 가중치 알파는 1번째 epoch 내에서 0에서 0.4로 선형적으로 증가시킨다.
4. A Mutual Information Maximization Perspective
이 섹션에서는 ALBEF의 대안적 관점을 제공하고 이미지-텍스트 쌍의 다른 "뷰"간의 상호 정보 (MI)의 하한을 최대화함을 보여준다. ITC, MLM, 그리고 MoD는 뷰를 생성하는 서로 다른 방식으로 해석될 수 있다.
형식적으로, 두 랜덤 변수 a와 b를 데이터 포인트의 두 가지 다른 뷰로 정의한다. self-supervised learning에서는 a와 b는 동일한 이미지의 두 가지 증강이다. 비전-언어 표현 학습에서는 a와 b를 이미지-텍스트 쌍의 의미를 포착하는 다양한 변형으로 간주한다. 뷰의 변화에 불변인 표현을 학습하는 것을 목표로 한다. 이는 a와 b 간의 MI를 최대화함으로써 달성될 수 있다. 실제로 InfoNCE loss를 최소화하여 MI(a,b)의 하한을 최대화한다.
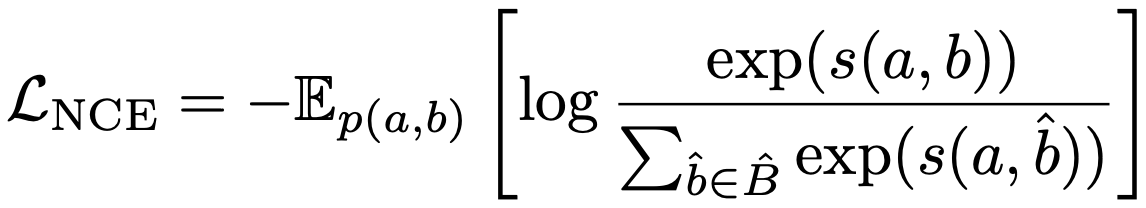
여기서 s(a,b)는 두 표현 간의 점수 함수(예: 두 표현 간의 내적)이며 B^은 positive 샘플 b와 제안 분포에서 추출된 |B^| - 1 개의 negative 샘플을 포함한다. 원-핫 레이블을 사용하는 ITC loss(식 2)를 다음과 같이 다시 쓸 수 있다.
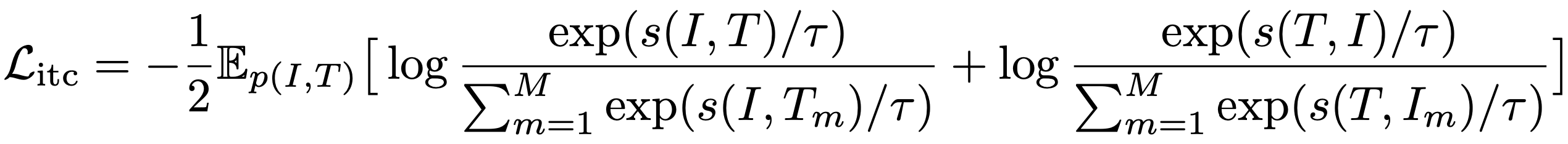
Litc를 최소화하는 것은 InfoNCE의 대칭 버전을 최대화하는 것으로 볼 수 있다. 따라서 ITC는 두 개의 개별 모달리티(즉, I와 T)를 이미지-텍스트 쌍의 두 가지 보기로 간주하고 positive 쌍의 이미지와 텍스트 뷰 간의 MI를 최대화하도록 단일모달 인코더를 훈련한다.
MLM도 마스킹된 단어 토큰과 그 마스킹된 컨텍스트(즉, 이미지와 마스킹된 텍스트) 간의 MI를 최대화하는 것으로 해석할 수 있다. 구체적으로, 원-핫 레이블을 사용하는 MLM loss (식 3)을 다음과 같이 다시 쓸 수 있다.
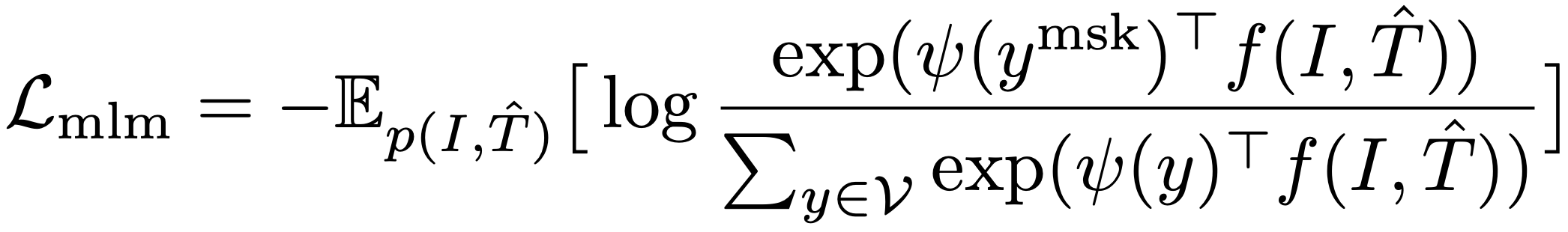
여기서 ψ(y)는 단어 토큰 y를 벡터로 매핑하는 멀티모달 인코더의 output 레이어의 lookup 함수이고 V는 전체 어휘 집합이다. f(I, T^)는 마스킹된 컨텍스트에 해당하는 멀티모달 인코더의 최종 hidden state를 반환하는 함수이다. 따라서 MLM은 이미지-텍스트 쌍의 두 뷰를 (1) 무작위로 선택된 단어 토큰과 (2) 이미지 + 해당 단어가 마스킹된 컨텍스트 텍스트로 간주한다.
ITC와 MLM은 모달리티 분리 또는 단어 마스킹을 통해 이미지-텍스트 쌍에서 부분 정보를 취하여 뷰를 생성한다. 모멘텀 증류는 전체 제안 분포에서 대안 뷰를 생성하는 것으로 간주될 수 있다. 예를 들어, 식 6의 ITCMoD의 경우, KL(pi2t(I), qi2t(I))를 최소화하는 것은 다음 목표를 최소화하는 것과 같다.
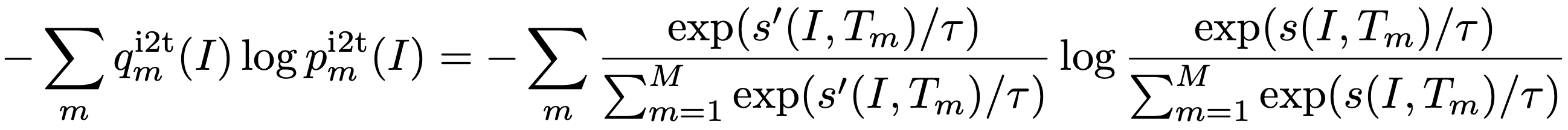
이것은 이미지 I와 유사한 의미를 공유하는 텍스트에 대해 MI(I, Tm)을 최대화한다. 마찬가지로, ITCMoD는 T와 유사한 이미지 MI(Im, T)를 최대화한다. 같은 방법으로 MLMMoD가 마스킹된 단어 ymsk에 대한 대안 뷰를 생성하고 y'와 (I, T^) 간의 MI를 최대화하는 것을 보여줄 수 있다. 따라서 우리의 모멘텀 증류는 원래 뷰에 대한 데이터 증강을 수행하는 것으로 간주될 수 있다. 모멘텀 모델은 원래 이미지-텍스트 쌍에 없는 다양한 뷰를 생성하며 기본 모델이 뷰 불변 의미 정보를 포착하는 표현을 학습하도록 권장한다.
5. Downstream V+L Tasks
사전 학습된 모델을 다섯 가지 downstream V+L task에 맞추어 조정한다. 각 task와 finetuning 전략을 아래에 소개한다. 데이터셋과 finetuning 하이퍼파라미터의 세부 사항은 부록에 있다.
Image-Text Retrieval 에는 image-to-text retrieval (TR)과 text-to-image retrieval (IR) 두 가지 subtask가 포함된다. Flickr30K와 COCO 벤치마크에서 ALBEF를 평가하고 각 데이터셋의 학습 샘플을 사용하여 사전 학습된 모델을 파인튜닝한다. Flickr30K에서 zero-shot 검색을 위해, COCO에서 파인튜닝된 모델로 평가한다. 파인튜닝 동안 ITC loss (식 2)와 ITM loss (식 4)를 공동으로 최적화한다. ITC는 단일모달 특징의 유사성에 기반한 이미지-텍스트 점수 함수를 학습하는 반면, ITM은 이미지와 텍스트 간의 세부적인 상호작용을 모델링하여 매칭 점수를 예측한다. downstream 데이터셋에는 각 이미지에 대해 여러 텍스트가 포함되어 있기 때문에, ITC의 정답 레이블을 queue 내에서 여러 positive들을 고려하도록 변경한다. 각 positive는 1/#positives의 정답 확률을 가진다. 추론 중에는 모든 이미지-텍스트 쌍에 대해 특징 유사도 점수 sitc를 먼저 계산한다. 그런 다음 상위 k개의 후보를 선택하고 이들의 ITM 점수 sitm을 계산하여 순위를 매긴다. k를 매우 작게 설정할 수 있기 때문에, 추론 속도는 모든 이미지-텍스트 쌍에 대해 ITM 점수를 계산해야 하는 방법들보다 훨씬 빠르다.
Visual Entailment (SNLI-VE)는 이미지와 텍스트 간의 관계가 포함, 중립 또는 모순인지 예측하는 세부적인 시각적 추론 task이다. UNITER를 따라 VE를 세 가지 분류 문제로 간주하고 멀티모달 인코더의 [CLS] 토큰 표현에 multi-layer perceptron (MLP)을 사용하여 클래스 확률을 예측한다.
Visual Question Answering (VQA)는 이미지와 질문이 주어졌을 때 정답을 예측하는 task이다. 기존 방법과 달리 VQA를 다중 정답 분류 문제로 공식화하는 대신, 본 논문은 VQA를 정답 생성 문제로 간주한다. 구체적으로 6-layer transformer 디코더를 사용하여 정답을 생성한다. Figure 3a에 나타난 바와 같이, auto-regressive 정답 디코더는 cross attention을 통해 multimodal 임베딩을 받고 start-of-sequence 토큰([CLS])을 디코더의 초기 input 토큰으로 사용한다. 마찬가지로, end-of-sequence 토큰([SEP])이 디코더 출력의 끝에 추가되어 생성 완료를 나타낸다. 정답 디코더는 multimodal 인코더에서 사전 학습된 가중치를 사용하여 초기화되며, 조건부 language-modeling loss로 파인튜닝된다. 기존 방법과의 공정한 비교를 위해, 추론 중에 디코더가 3,192개의 후보 정답만 생성하도록 제한한다.
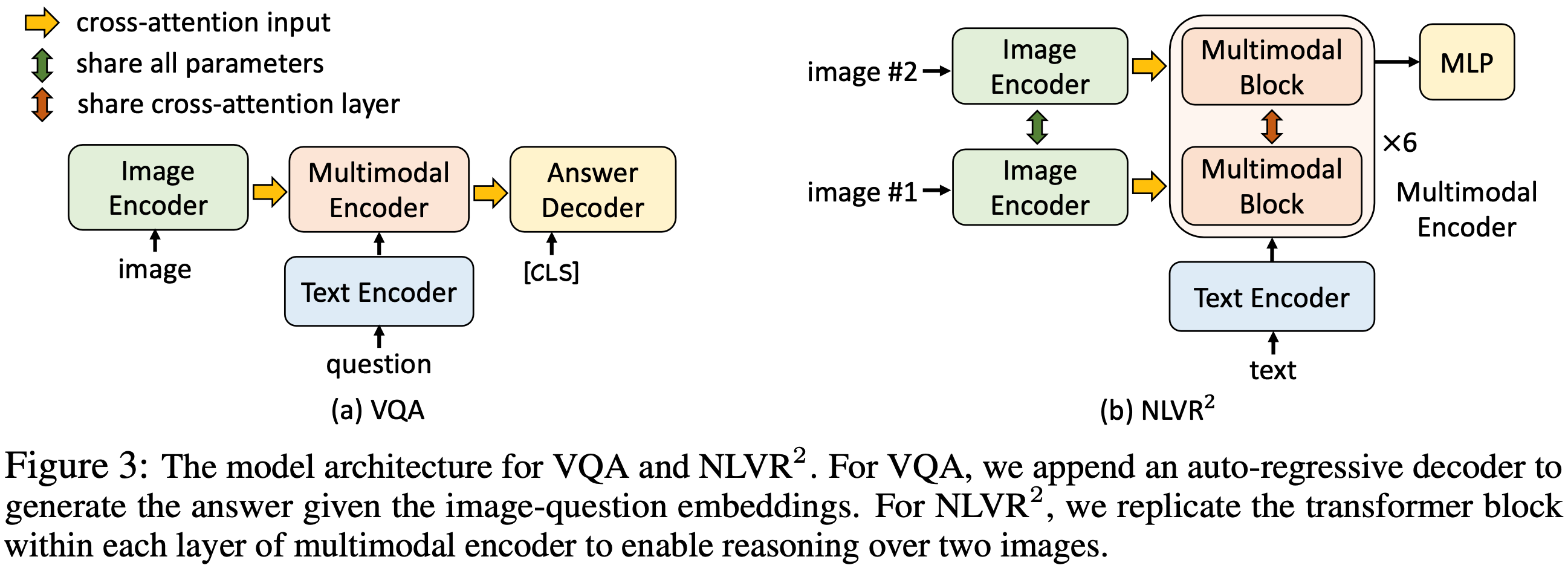
Natural Language for Visual Reasoning (NLVR2)는 텍스트가 이미지 쌍을 설명하는지 예측하는 task이다. multimodal 인코더를 확장하여 두 이미지에 대해 추론할 수 있도록 한다. Figure 3b에 나타난 바와 같이, multimodal 인코더의 각 레이어는 두 개의 연속적인 transformer 블록을 갖도록 복제되며, 각 블록은 self-attention layer, cross-attention layer, feed-forward layer를 포함한다 (Figure 1). 각 레이어 내의 두 블록은 동일한 사전 학습 가중치로 초기화되며, 두 cross-attention layer는 key와 value에 대해 동일한 linear projection 가중치를 공유한다. 훈련 중에는 두 블록이 이미지 쌍에 대한 두 세트의 이미지 임베딩을 수신한다. 예측을 위해 multimodal 인코더의 [CLS] 표현에 MLP 분류기를 추가한다.
NLVR2의 경우, 이미지 쌍을 인코딩하기 위한 새로운 multimodal 인코더를 준비하기 위해 추가적인 사전 학습 단계를 수행한다. text-assignment (TA) task는 다음과 같이 설계한다. 이미지 쌍과 텍스트가 주어졌을 때, 모델이 텍스트를 첫 번째 이미지, 두 번째 이미지 또는 둘 중 어느 것도 아닌 것으로 할당해야 한다. 이를 세 가지 분류 문제로 간주하고 [CLS] 표현에 FC 레이어를 사용하여 할당을 예측한다. TA를 4M 이미지 (section 3.4)를 사용하여 단 1 epoch 동안 사전 학습한다.
Visual Grounding 은 특정 텍스트 설명에 해당하는 이미지 내의 영역을 찾는 것을 목표로 한다. bounding box 주석이 없는 weakly-supervised 설정을 연구한다. RefCOCO+ 데이터셋에서 실험을 수행하고 이미지-텍스트 검색과 동일한 전략을 따라 이미지-텍스트 감독만을 사용하여 모델을 파인튜닝한다. 추론 중에는 Grad-CAM을 확장하여 히트맵을 획득하고 이를 사용하여 탐지된 제안의 순위를 매긴다.
6. Experiments
6.1 Evaluation on the Proposed Methods
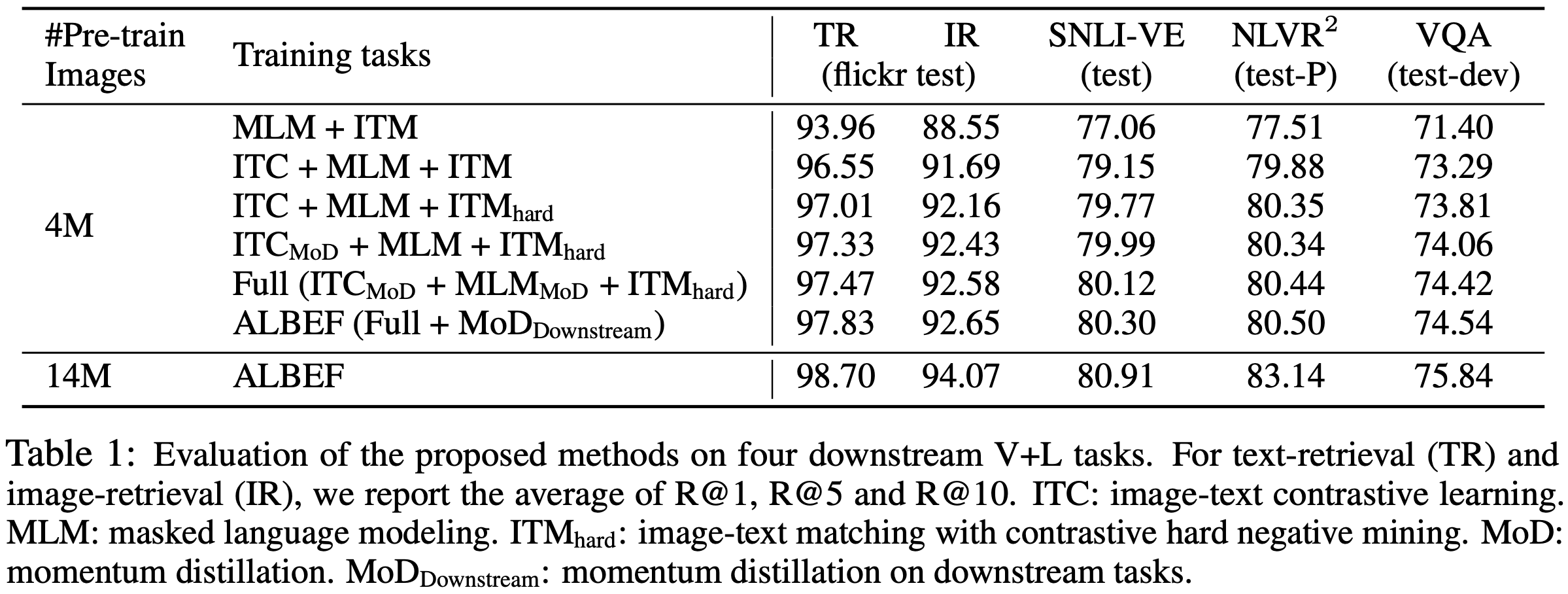
먼저, 제안된 방법들 (i.e., image-text contrastive learning, contrastive hard negative mining, momentum distillation)의 효과를 평가한다. Table 1은 본 논문 방법의 다양한 변형에 따른 downstream task의 성능을 보여준다. 기본 사전 학습 task (MLM+ITM)와 비교하여 ITC를 추가하면 모든 task에서 사전 학습된 모델의 성능이 크게 향상된다. 제안된 hard negative mining은 더 유용한 학습 샘플을 찾아 ITM을 개선한다. 또한, 모멘텀 증류를 추가하면 ITC(4행), MLM(5행) 및 모든 downstream task(6행)의 학습이 개선된다. 마지막 행에서는 ALBEF가 더 많은 노이즈가 있는 웹 데이터를 효과적으로 활용하여 사전 학습 성능을 향상시킬 수 있음을 보여준다.
6.2 Evaluation on Image-Text Retrieval
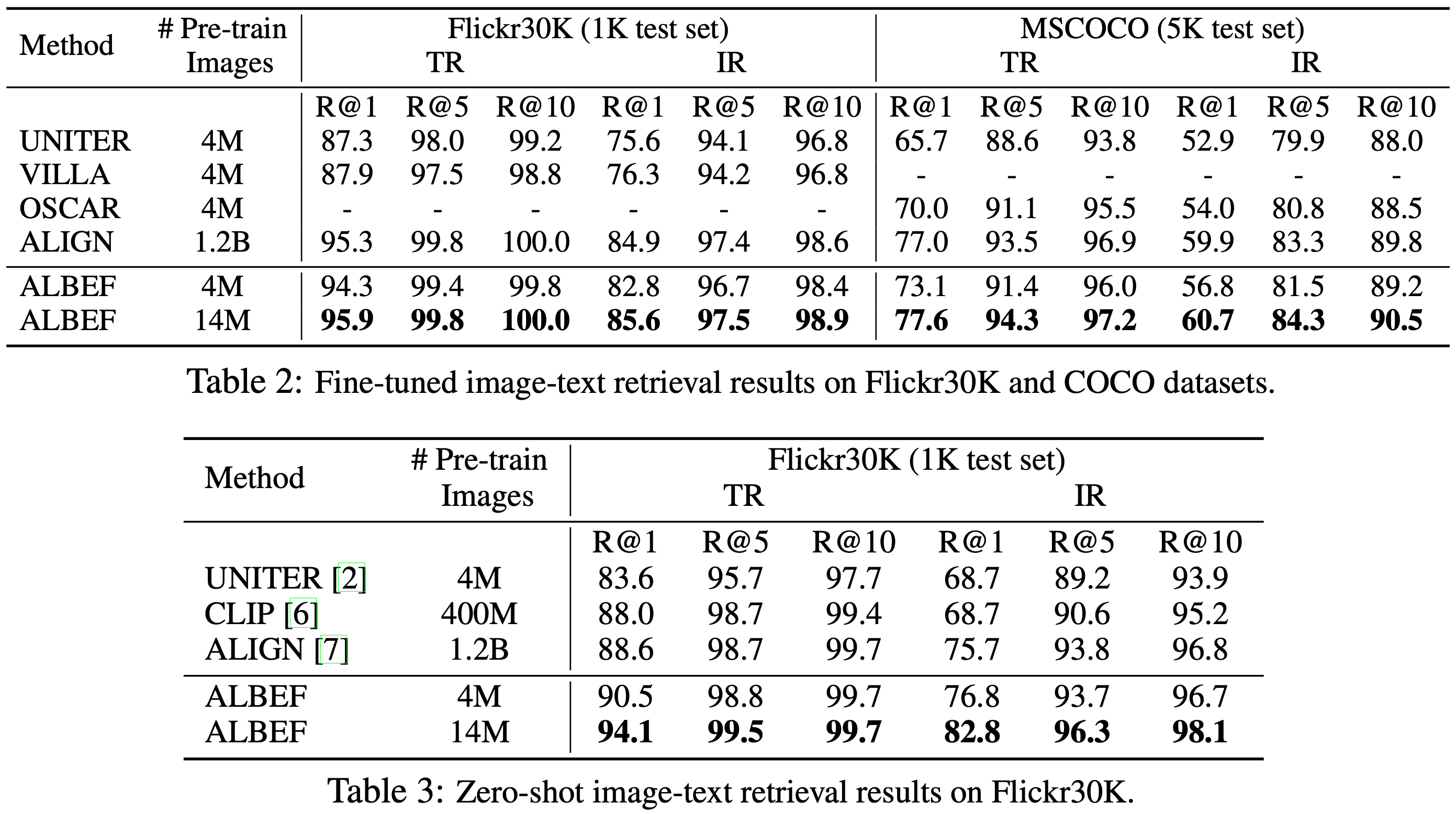
Table 2와 Table 3은 각각 파인튜닝된 이미지-텍스트 검색과 zero-shot 이미지-텍스트 검색 결과를 보고한다. ALBEF는 CLIP과 ALIGN을 능가하며 SOTA 성능을 달성한다. ALBEF가 훈련 이미지 수가 4M에서 14M로 증가할 때 상당한 성능 향상을 보이는 것을 감안할 때, 더 큰 규모의 웹 이미지-텍스트 쌍을 사용하여 훈련하면 더욱 성장할 가능성이 있다고 가정한다.
6.3 Evaluation on VQA, NLVR, and VE
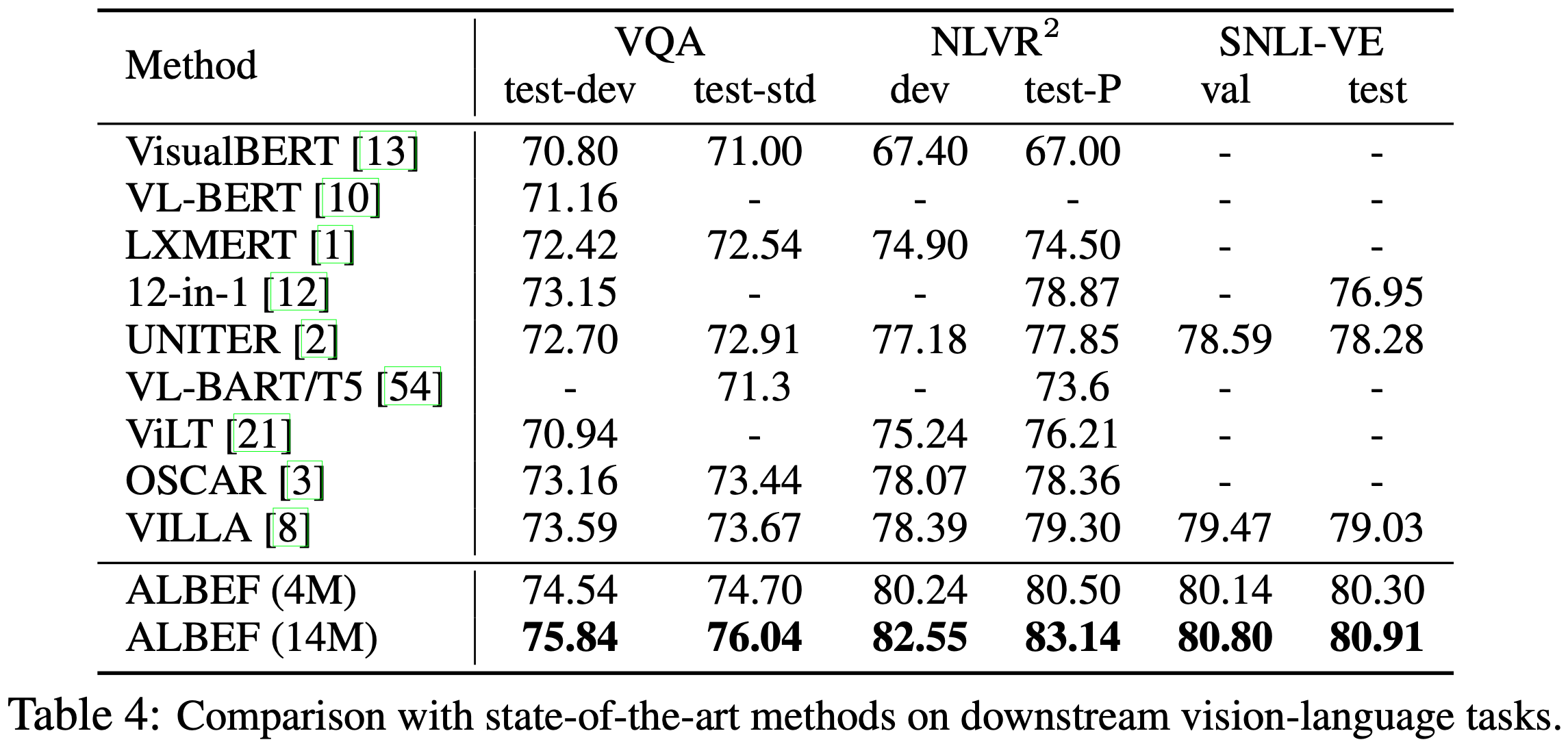
Table 4는 다른 V+L 이해 task에 대한 기존 방법들과의 비교를 보고한다. 4M의 사전 학습 이미지를 사용하여도 ALBEF는 이미 SOTA 성능을 달성한다. 14M의 사전 학습 이미지를 사용하면 ALBEF는 객체 태그 또는 적대적 데이터 증강을 추가로 사용하는 방법들을 포함하여 기존 방법들을 크게 능가한다. VILLA와 비교할 때, ALBEF는 VQA 테스트 표준에서 2.37%, NLVR2 테스트-P에서 3.84%, SNLI-VE 테스트에서 1.88%의 절대적인 향상을 달성한다. ALBEF는 object detector를 사용하지 않으며 더 낮은 해상도의 이미지를 필요로 하기 때문에, 대부분의 기존 방법들에 비해 훨씬 빠른 추론 속도를 자랑한다(NLVR2에서 VILLA보다 10배 이상 빠름).
6.4 Weakly-supervised Visual Grounding
Table 5는 RefCOCO+에 대한 결과를 보여주며 ALBEF는 기존 방법들(더 약한 텍스트 임베딩을 사용하는)보다 상당히 뛰어난 성능을 보인다. ALBEF itc 변형은 이미지 인코더의 마지막 레이어에서 self-attention 맵에 대해 Grad-CAM 시각화를 계산하며, 이때 기울기는 이미지-텍스트 유사도 s itc를 최대화함으로써 얻어진다. ALBEF itm 변형은 멀티모달 인코더의 3번째 레이어(그라운딩에 특화된 레이어)에서 cross-attention 맵에 대해 Grad-CAM을 계산하며, 이때 기울기는 이미지-텍스트 매칭 점수 s itm을 최대화함으로써 얻어진다. Figure 4는 몇 가지 시각화를 제공한다. 더 많은 분석은 부록에 있다.

VQA에 대한 Grad-CAM 시각화를 Figure 5에서 제공한다. 부록에서 볼 수 있듯이, ALBEF의 Grad-CAM 시각화는 사람들이 결정을 내릴 때 보는 곳과 매우 밀접하게 관련되어 있다. Figure 6에서는 COCO에 대한 단어별 시각화를 보여준다. ALBEF가 객체뿐만 아니라 그들의 속성과 관계도 그라운딩하는 방법에 주목해라.

6.5 Ablation Study
Table 6은 이미지-텍스트 검색에서 다양한 설계에 대한 효과를 연구한다. 추론 중 상위 k개의 후보를 필터링하기 위해 s itc를 사용하므로, k를 변화시키고 그 영향을 보고한다. 일반적으로 s itm에 의해 획득된 순위 결과는 k의 변화에 민감하지 않다. 마지막 열에서는 hard negative mining의 효과를 검증한다.
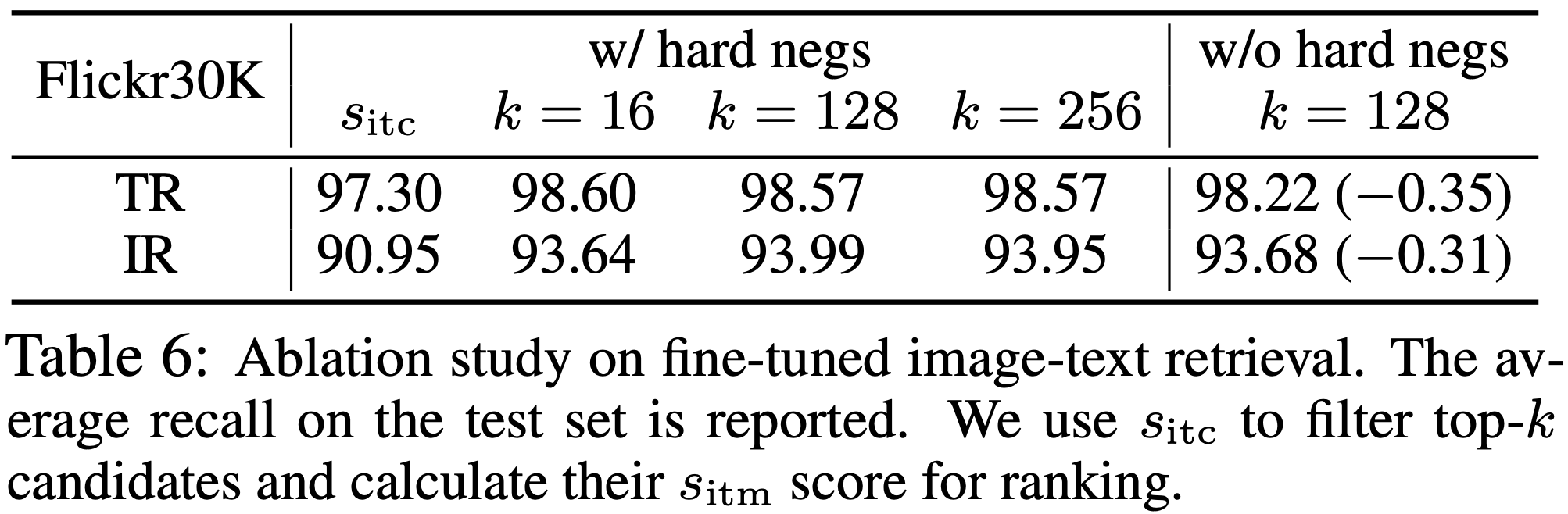
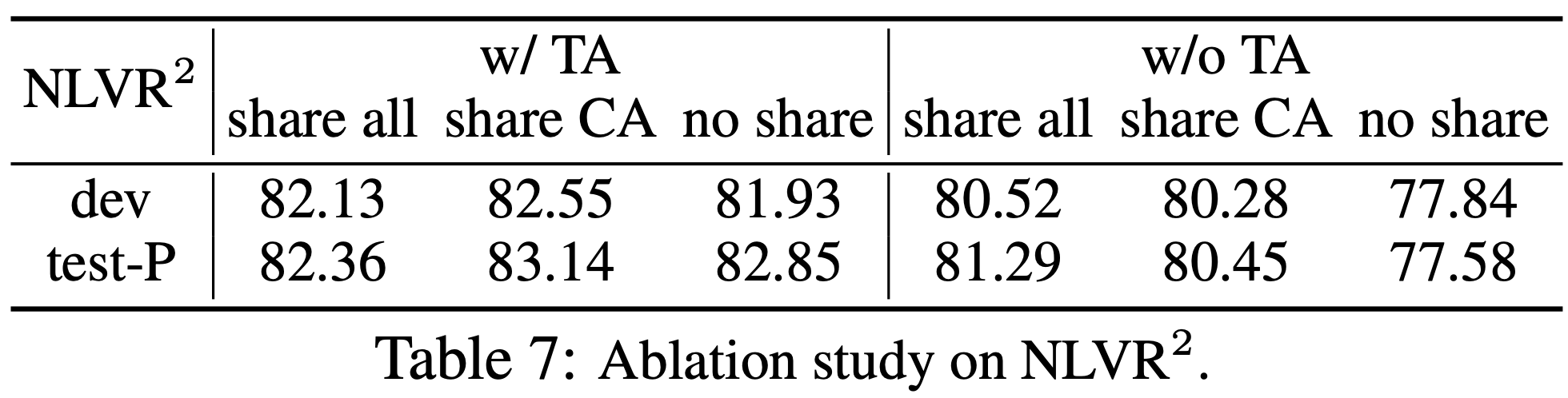
Table 7은 NLVR2에서 text-assignment (TA) 사전 학습과 파라미터 공유의 효과를 연구한다. 세 가지 전략을 조사한다.
(1) 두 멀티모달 블록이 모든 파라미터를 공유
(2) cross-attention (CA) layer만 공유
(3) 공유 없음
TA 없이, 전체 블록을 공유하는 것이 더 나은 성능을 보인다. 이미지 쌍에 대해 모델을 사전 학습하기 위해 TA를 사용할 때, CA를 공유하는 것이 최고의 성능을 발휘한다.
7. Conclusion and Social Impacts
본 논문에서는 비전-언어 표현 학습을 위한 새로운 프레임워크인 ALBEF를 제안한다. ALBEF는 멀티모달 인코더와 융합하기 전에 단일모달 이미지 표현과 텍스트 표현을 먼저 정렬한다. 제안된 이미지-텍스트 contrastive learning과 모멘텀 증류의 효과를 이론적 및 실험적으로 검증했다. 기존 방법과 비교할 때, ALBEF는 여러 downstream V+L task에서 더 나은 성능과 더 빠른 추론 속도를 제공한다.
비전-언어 표현 학습에서 유망한 결과를 보였지만, 실제로 배포하기 전에 데이터와 모델에 대한 추가 분석이 필요하다. 웹 데이터는 의도치 않은 개인 정보, 부적절한 이미지, 또는 유해한 텍스트를 포함할 수 있으며, 정확도만을 최적화하는 것은 원치 않은 사회적 영향을 초래할 수 있다.
Appendix
A. Downstream Task Details
여기에서는 사전 학습된 모델을 파인튜닝하기 위한 구현 세부 사항을 설명한다. 모든 downstream task에서 사전 학습 동안과 동일한 RandAugment, AdamW optimizer, cosine learning rate decay, 가중치 감쇠 및 증류 가중치를 사용한다. 모든 downstream task에는 해상도 384 x 384의 input 이미지가 제공된다. 추론 중에는 이미지를 자르지 않고 크기만 조정한다.
Image-Text Retrieval.
이 task에는 두 가지 데이터셋(COCO와 Flickr30K)을 고려한다. 두 데이터셋 모두에 대해 널리 사용되는 Karpathy 분할을 채택한다. COCO는 train/validation/test에 대해 각각 113k/5k/5k 이미지를 포함한다. Flickr30K는 train/validation/test에 대해 각각 29k/1k/1k 이미지를 포함한다. 10 epoch 동안 파인튜닝하고 batch size는 256이고 초기 학습률은 1e-5이다.
Visual Entailment.
SNLI-VE 데이터셋에서 평가한다. 이 데이터셋은 Stanford Natural Language Inference (SNLI)와 Flickr30K 데이터셋을 사용하여 구성되었다. 원래 데이터셋 분할을 따르며 학습용으로 29.8k 이미지, 평가용으로 1k 이미지, 테스트용으로 1k 이미지를 사용한다. 5 epoch 동안 사전 학습된 모델을 파인튜닝하며 batch size는 256이고 초기 학습률은 2e-5이다.
VQA.
VQA2.0 데이터셋에서 실험을 수행한다. 이 데이터셋은 COCO의 이미지를 사용하여 구성되었으며 학습용으로 83k 이미지, 검증용으로 41k 이미지, 테스트용으로 81k 이미지를 포함한다. test-dev와 test-std 분할에서 성능을 보고한다. 대부분의 기존 연구에 따라 학습과 검증 세트를 모두 사용하여 훈련하고 Visual Genome의 추가적인 질문-응답 쌍을 포함한다. VQA 데이터셋의 많은 질문이 여러 정답을 포함하기 때문에, 모든 정답 중 발생 비율에 따라 각 정답의 loss에 가중치를 부여한다. 모델은 8 epoch 동안 파인튜닝하며 batch size는 256이고 초기 학습률은 2e-5이다.
NLVR2.
기존 train/val/test 분할을 따른다. 모델을 10 epoch 동안 파인튜닝하며 batch size는 128이고 초기 학습률은 2e-5이다. NLVR은 두 개의 input 이미지를 받기 때문에, 텍스트 할당 (TA) 사전 학습 단계를 추가로 수행하여 두 이미지를 통해 추론할 수 있도록 모델을 준비한다. TA 사전 학습은 해상도 256 x 256의 이미지를 사용하며 4M 데이터셋에서 1 epoch 동안 batch size 256 및 학습률 2e-5로 사전 학습한다.
Visual Grounding.
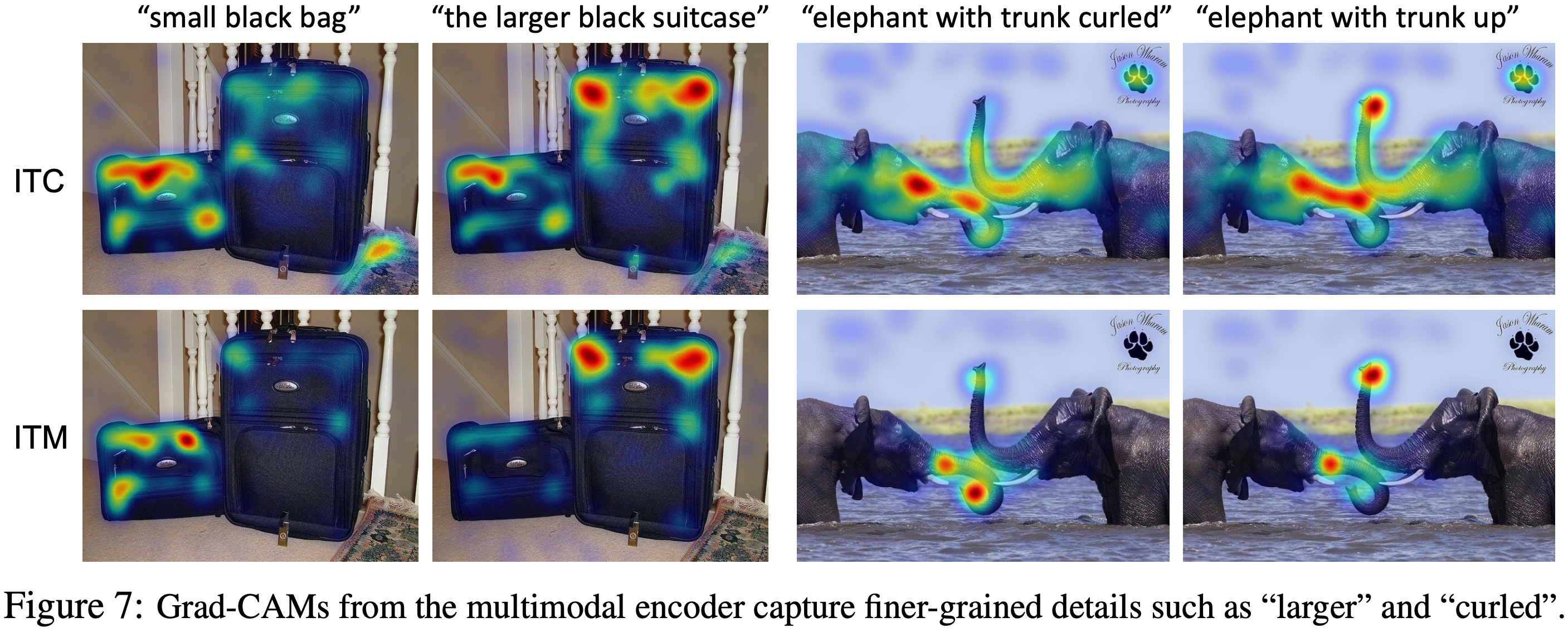
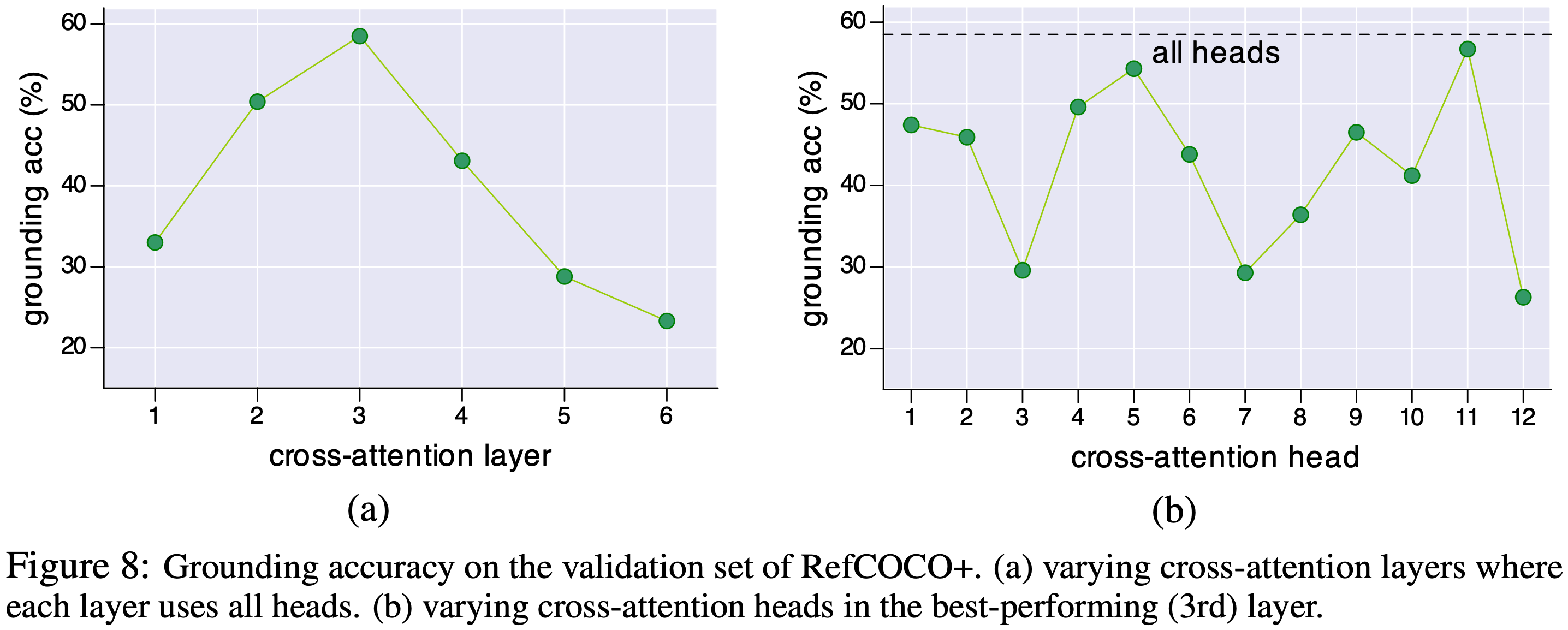
두 명의 플레이어가 참여하는 ReferitGame을 사용하여 수집된 RefCOCO+ 데이터셋에서 실험을 수행한다. 이 데이터셋은 COCO 학습 세트에서 19,992개의 이미지에 대해 141,564개의 표현을 포함한다. 엄밀히 말하면, 모델은 RefCOCO+의 검증/테스트 이미지를 보지 않아야 하지만, 사전 학습 동안 이러한 이미지에 노출되었다. 이러한 이미지가 전체 14M 사전 학습 이미지 중 매우 작은 부분만 차지하기 때문에 이 영향이 적을 것이라고 가정하며 데이터를 정화하는 작업은 향후 과제로 남겨둔다. weakly-supervised 파인튜닝 과정에서 이미지-텍스트 검색과 동일한 전략을 따르지만, 랜덤 크롭을 수행하지 않고 모델을 5 epoch 동안 훈련한다. 추론 중에는 각 16 x 16 이미지 패치에 대한 중요도 점수를 계산하기 위해 s itc 또는 s itm을 사용한다. ITC의 경우, 시각적 인코더의 마지막 레이어에서 [CLS] 토큰에 대한 self-attention 맵에 대해 Grad-CAM 시각화를 계산하고 모든 attention head에서 heatmap을 평균화한다. ITM의 경우, 멀티모달 인코더의 3번째 레이어에서 cross-attention 맵에 대해 Grad-CAM을 계산하고 모든 attention head와 모든 input 텍스트 토큰에서 점수를 평균화한다. ITC와 ITM의 정량적 비교는 Table 5에 나와 있다. Figure 7은 정성적 비교를 보여준다. 멀티모달 인코더는 이미지-텍스트 상호작용을 더 잘 모델링할 수 있기 때문에, 더 세밀한 세부 사항을 캡처하는 더 나은 heatmap을 생성한다. Figure 8에서는 최고 성능을 내는 레이어 내의 각 개별 attention head와 각 cross-attention 레이어에 대한 그라운딩 정확도를 보고한다.
B. Additional Per-word Visualizations
Figure 9에서는 객체, 행동, 속성 및 관계의 시각적 그라운딩을 수행하는 모델의 능력을 보여주기 위해 단어별 Grad-CAM의 추가 시각화를 제공한다.

C. Comparison with Human Attention
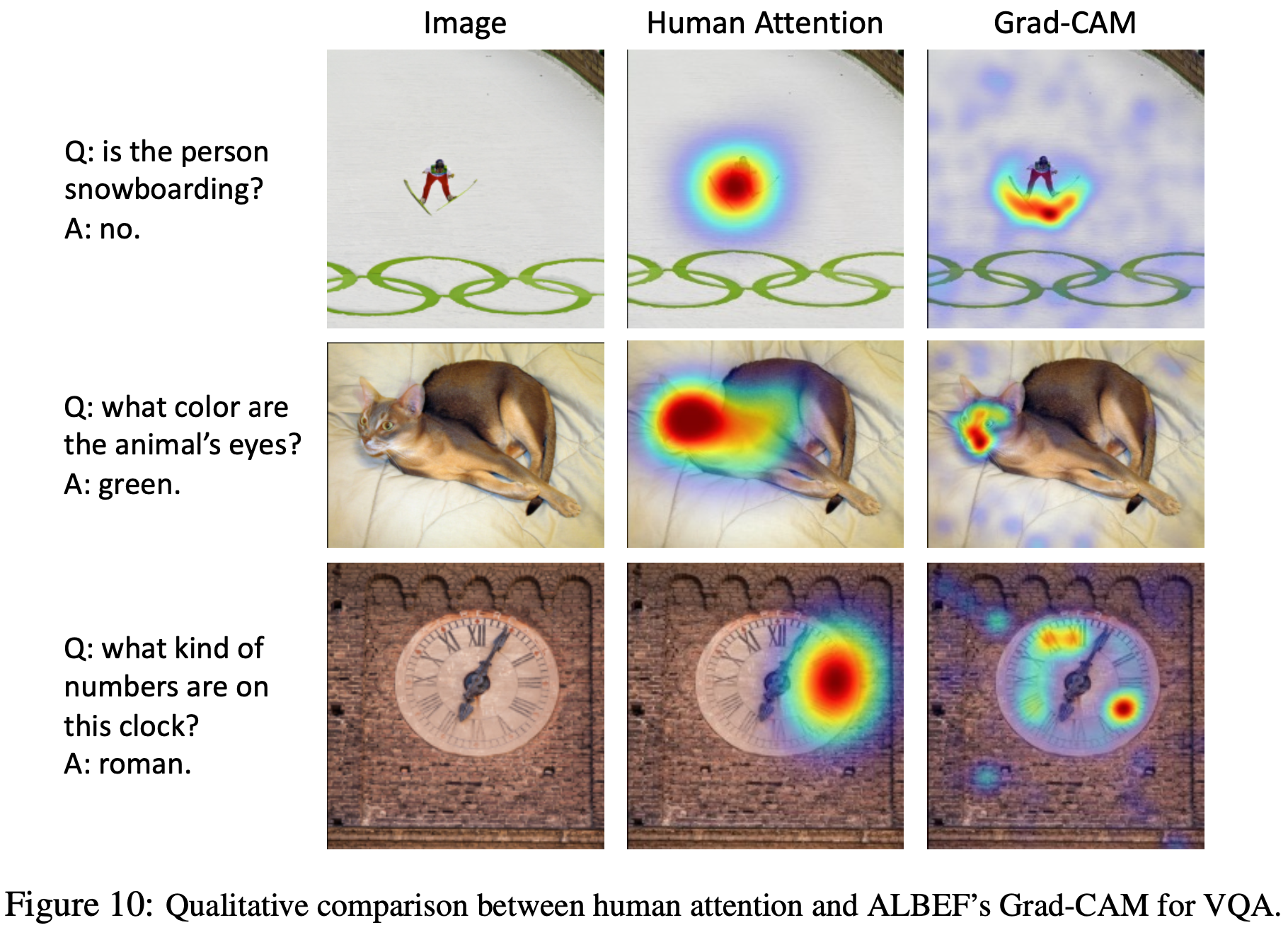
한 연구는 VQA 데이터셋의 하위 집합에 대한 인간 attention map을 수집했다. 질문과 흐릿하게 처리된 이미지 버전이 주어졌을 때, Amazon Mechanical Turk의 사람들은 자신 있게 질문에 답할 수 있을 때까지 이미지 영역의 흐릿함을 인터랙티브하게 제거하도록 요청받았다. 이 작업에서는 이와 같이 순위 상관 평가 프로토콜을 사용하여 1374개의 검증 질문-이미지 쌍에 대해 3번째 멀티모달 cross-attention 레이어에서 계산된 ALBEF VQA 모델의 Grad-CAM 시각화를 인간 attention map과 비교한다. 정답에 대해 계산된 Grad-CAM과 인간 attention map이 0.205의 높은 상관관계를 가짐을 발견했다. 이는 그라운드된 이미지-텍스트 쌍에 대해 훈련되지 않았음에도 불구하고, ALBEF가 결정을 내릴 때 적절한 영역을 본다는 것을 보여준다. 인간 attention map과의 비교를 보여주는 정성적 예는 Figure 10에서 볼 수 있다.
D. Additional Examples of Pseudo-targets


E. Pre-training Dataset Details
Table 8은 사전 학습 데이터셋의 이미지와 텍스트 통계를 보여준다.