본 글은 https://arxiv.org/abs/2103.00020 내용을 기반으로 합니다.
혹시 잘못된 부분이나 수정할 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
Abstract
이미지에 대한 원시 텍스트로부터 직접 학습하는 것은 더 광범위한 supervision을 활용하는 유망한 방법이다. 본 논문은 인터넷에서 수집한 4억 개의(이미지, 텍스트) 쌍 데이터셋을 사용하여 처음부터 최첨단 이미지 표현을 학습하는 효율적이고 확장 가능한 방법으로 어떤 캡션이 어떤 이미지와 일치하는지 예측하는 간단한 pre-training task를 보여준다. pre-training 후, 자연어를 사용하여 학습된 시각적 개념을 참조하거나 새로운 개념을 설명할 수 있으며 이를 통해 모델을 downstream task에 zero-shot으로 전이할 수 있다. 본 논문은 OCR, 비디오 속 액션 인식, 지리적 위치 확인, 다양한 세부 객체 분류와 같은 30개 이상의 기존 컴퓨터 비전 데이터셋을 벤치마킹하여 이 접근 방식의 성능을 연구한다. 모델은 대부분의 task에 non-trivially하게 전이되며 종종 특정 데이터셋 훈련이 필요 없는 fully supervised baseline과 경쟁할 수 있다. 예를 들어, 1.28백만 개의 training example를 사용하지 않고도 ImageNet에서 기존 ResNet-50의 정확도를 zero-shot으로 맞출 수 있다.
1. Introduction and Motivating Work
원시 텍스트에서 직접 학습시키는 pre-training 방법은 지난 몇 년 동안 NLP 분야에 혁명을 일으켰다. autoregressive와 masked language modeling과 같은 task-agnostic objective는 계산량, 모델 용량 및 데이터 규모에서 여러 차례를 걸쳐 확장되어 성능을 꾸준히 향상시켜 왔다. "text-to-text"를 표준화된 input-output interface로 개발하는 것은 task-agnostic 아키텍처가 특수한 output head나 데이터셋 특정 customization 없이 downstream 데이터셋으로 zero-shot transfer를 가능하게 했다. GPT-3와 같은 대표적인 시스템은 거의 또는 전혀 데이터셋 특정 학습 데이터가 필요하지 않으면서 많은 task에 맞춤형 모델과 경쟁할 수 있다.
1999년에는 이미지와 함께 제공된 텍스트 문서에서 명사와 형용사를 예측하는 모델을 훈련시켜 콘텐츠 기반 이미지 검색을 개선하려고 시도했다. 2007년에는 이미지와 관련된 캡션의 단어를 예측하도록 훈련된 분류기의 가중치 공간에서 manifold 학습을 통해 효율적인 이미지 표현을 학습할 수 있음을 입증했다. 2012년에는 저수준 이미지와 텍스트 태그 특징 위에 multimodal Deep Boltzmann Machine을 훈련시켜 심층 표현 학습을 탐구했다. 2016년에는 이 작업을 현대화하여 이미지 캡션의 단어를 예측하도록 훈련된 CNN이 유용한 이미지 표현을 학습할 수 있음을 입증했다. 그들은 YFCC100M 데이터셋의 이미지 제목, 설명, 해시태그 메타데이터를 단어 집합 다중 라벨 분류 작업으로 변환하고 AlexNet을 pre-training하여 이러한 라벨을 예측하도록 함으로써 전이 task에서 ImageNet 기반 pre-training과 유사한 성능으로 학습했다. 2017년에는 이러한 접근 방식을 확장하여 개별 단어 외에도 n-그램을 예측하도록 하고 학습된 시각적 n-그램 사전을 기반으로 대상 클래스를 점수화하고 가장 높은 점수를 예측하여 다른 이미지 분류 데이터셋으로 zero-shot 전이를 수행할 수 있음을 입증했다. 더 최근의 아키텍처와 pre-training 접근 방식을 채택한 VirTex, ICMLM, ConVIRT는 최근 트랜스포머 기반 language modeling, masked language modeling, contrastive objective가 텍스트로부터 이미지 표현을 학습하는 가능성을 입증했다. 하지만, 자연어 supervision을 사용한 이미지 표현 학습은 여전히 드물다. 이는 일반적인 벤치마크에서 입증된 성능이 대안 접근 방식보다 훨씬 낮기 때문일 가능성이 크다. 자연어는 더 넓은 범위의 시각적 개념을 표현하며 감독할 수 있다.
2. Approach
2.1 Natural Language Supervision
본 연구의 핵심은 자연어에 포함된 supervision으로부터 인식을 학습하는 아이디어이다. 여러 연구에서 텍스트와 이미지가 짝지어진 데이터를 통해 시각적 표현을 학습하는 방법을 소개했지만 각각의 접근 방식을 unsupervised, self-supervised, weakly supervised 및 supervised로 설명했다.
자연어로부터 학습하는 것은 다른 훈련 방법에 비해 몇 가지 잠재적인 강점을 가지고 있다. 별도로 레이블을 붙이는 이미지 분류에 비해 자연어 감독을 확장하는 것은 훨씬 쉽다. 이는 이미지와 함께 제공되는 설명이나 캡션과 같은 자연어를 사용하면 되므로 사람이 직접 라벨을 붙이지 않아 주석이 필요하지 않기 때문이다. 대신 자연어를 사용하는 방법은 인터넷에 존재하는 방대한 양의 텍스트에 포함된 감독으로부터 수동적으로 학습할 수 있다. 자연어로부터 학습하는 것은 대부분의 비지도 또는 자기 지도 학습 접근 방식에 비해 중요한 이점을 가지고 있다. 이는 단순히 표현을 학습하는 것뿐만 아니라, 그 표현을 언어와 연결하여 유연한 zero-shot 전이를 가능하게 한다. 다음 하위 섹션에서는 본 연구에서 선택한 구체적인 접근 방식을 자세히 설명한다.
2.2 Creating a Sufficiently Large Dataset
기존의 연구는 주로 세 가지 데이터셋 MS-COCO, Visual Genome, YFCC100M을 사용했다. MS-COCO와 Visual Genome은 고품질의 crowd-labeled 데이터셋이지만 각각 약 10만 개의 훈련 사진을 포함하고 있어 현재 기준으로는 작다. 이에 비해, 다른 컴퓨터 비전 시스템은 최대 35억 개의 인스타그램 사진으로 훈련된다. YFCC100M은 1억 개의 사진으로 가능성이 있지만, 각 이미지의 메타데이터는 희소하고 품질이 다양하다. 많은 이미지가 자동 생성된 파일 이름(예: 20160716_113957.JPG)을 제목으로 사용하거나 카메라 노출 설정에 대한 설명을 포함한다. 자연어 제목 및 설명이 있는 이미지만 유지하도록 필터링한 결과, 데이터셋은 6분의 1로 축소되어 1500만 개의 사진만 남았다. 이는 ImageNet과 비슷한 크기이다.
자연어 감독의 주요 동기는 인터넷에서 공개적으로 이용 가능한 대량의 데이터를 사용하는 것이다. 기존 데이터셋만을 고려한 결과는 이 연구 분야의 잠재력을 과소평가하게 할 수 있다. 이를 해결하기 위해, 인터넷에서 다양한 공개 소스를 통해 수집한 4억 개의 (이미지, 텍스트) 쌍으로 구성된 새로운 데이터셋을 구축했다. 가능한 넓은 범위의 시각적 개념을 포괄하기 위해, 50만 개의 쿼리 중 하나를 포함하는 (이미지, 텍스트) 쌍을 검색했다. 각 쿼리 당 최대 2만 개의 (이미지, 텍스트) 쌍을 포함하여 결과를 대략적으로 클래스 균형을 맞췄다. 결과 데이터셋은 GPT-2를 훈련하는 데 사용된 WebText 데이터셋과 유사한 총 단어 수를 가지고 있다. 이러한 데이터셋을 WIT(WebImageText)라고 부른다.
2.3 Selecting an Efficient Pre-Training Method
SOTA 컴퓨터 비전 시스템들은 매우 많은 연산량을 사용한다. ResNetXt101-32x48d를 훈련하는 데 19 GPU 연도를 필요로 했고 Noisy Student EfficientNet-L2를 훈련하는 데 33 TPUv3 코어 연도를 필요로 했다. 이 시스템들이 ImageNet 클래스 1000개만 예측하도록 훈련되었다는 점을 고려하면 자연어로부터 열린 집합의 시각적 개념을 학습하는 작업은 매우 벅찬 일처럼 보인다. 본 연구는 훈련 효율성이 자연어 감독을 성공적으로 확장하는 데 중요한 요소임을 발견했고 이 측정 기준에 따라 최종 사전 훈련 방법을 선택했다.
VirTex와 유사하게, 본 연구의 초기 접근 방식은 이미지 CNN과 텍스트 transformer를 처음부터 공동으로 훈련하여 이미지의 캡션을 예측하는 것이었다. 그러나 이 방법을 효율적으로 확장하는 데 어려움을 겪었다. Figure 2에서 6300만 개의 파라미터를 가진 transformer 언어 모델이 이미지를 인코딩하는 ResNet-50보다 두 배의 연산량을 사용하면서도 ImageNet 클래스를 인식하는 데 세 배 더 느리게 학습하는 것을 보여준다.

이 두 접근 방식은 중요한 유사성을 공유한다. 이미지와 함께 제공되는 텍스트의 정확한 단어를 예측하려고 한다. 이는 이미지와 함께 발생하는 다양한 설명, 댓글, 관련 텍스트로 인해 어려운 task이다. 최근 이미지의 contrastive representation learning 연구는 대조적 목표가 동등한 예측 목표보다 더 나은 표현을 학습할 수 있음을 발견했다. 다른 연구에서는 생성 모델이 고품질 이미지 표현을 학습할 수 있지만 같은 성능의 대조 모델보다 연산량이 10배 이상 더 필요하다고 밝혔다. 이러한 발견을 바탕으로, 텍스트의 정확한 단어가 아닌 텍스트 전체가 어떤 이미지와 짝지어졌는지를 예측하는 더 쉬운 task를 해결하기 위해 시스템을 훈련하는 방법을 탐구했다. 같은 단어 인코딩 기준으로 시작하여 Figure 2에서 예측 목표를 대조 목표로 교체하고 ImageNet으로의 zero-shot 전이 속도에서 4배의 효율성 향상을 관찰했다.
N개의 (이미지, 텍스트) 쌍의 배치를 고려할 때, CLIP은 배치 내에서 실제 발생한 N x N 가능한 (이미지, 텍스트) 쌍을 예측한다. 이를 위해, CLIP은 이미지 인코더와 텍스트 인코더를 공동으로 훈련하여 배치의 N개의 실제 쌍의 이미지 및 텍스트 임베딩의 코사인 유사성을 극대화하고 N^2 - N 개의 잘못된 쌍의 임베딩의 코사인 유사성을 최소화한다. 이 유사성 점수에 대해 대칭적인 cross-entropy loss를 최적화한다. Figure 3에는 CLIP 구현의 핵심을 보여주는 의사 코드를 포함했다. 이 배치 구성 기술과 목표는 deep metric 학습 영역에서 처음 소개되었으며, 대조적 표현 학습을 위해 InfoNCE loss가 대중화되었고 최근에는 대조적 (텍스트, 이미지) 표현 학습을 위해 의료 영상 분야에 적응되었다.
본 연구에서 사용하는 사전 훈련 데이터셋의 큰 크기 때문에 과적합은 주요 문제가 아니며 CLIP의 훈련 세부 사항은 다른 연구에 비해 단순화되었다. ImageNet 가중치로 이미지 인코더를 초기화하거나 사전 훈련된 가중치로 텍스트 인코더를 초기화하지 않고 CLIP을 처음부터 훈련한다. 본 연구는 표현과 대조적 임베딩 공간 사이의 non-linear projection을 사용하지 않으며, 대신 각 인코더의 표현에서 multi-modal 임베딩 공간으로 매핑하기 위해 linear projection만을 사용한다. 본 연구는 두 버전 간의 훈련 효율성에서 차이를 발견하지 못했으며 non-linear projection이 현재의 이미지 자체의 자기 지도 표현 학습 방법의 세부 사항과 함께 적응된 것일 수 있다고 추측한다. CLIP의 사전 훈련 데이터셋의 많은 (이미지, 텍스트) 쌍이 단일 문장만 포함하기 때문에 텍스트에서 단일 문장을 균일하게 샘플링한다. 또한 이미지 변환 함수 tv를 단순화했다. 훈련 중 사용되는 유일한 데이터 증강은 resize된 이미지에서 임의의 정사각형 crop이다. 마지막으로, softmax에서 로짓의 범위를 제어하는 온도 매개변수는 로그 매개변수화된 곱셈 스칼라로 훈련 중에 직접 최적화되어 하이퍼파라미터 조정을 피한다.
2.4 Choosing and Scaling a Model
이미지 인코더를 위해 두 가지 다른 아키텍처를 고려했다. 첫 번째로, 이미지 인코더의 기본 아키텍처로 널리 채택되고 검증된 성능을 가진 ResNet-50을 사용했다. ResNet-D 개선 사항과 rect-2 blur pooling을 사용하여 원래 버전에 몇 가지 수정을 가했다. 또한, global average pooling layer를 attention pooling 메커니즘으로 교체했다. attention pooling은 이미지의 global average pooling 표현에 조건화된 "transformer-style" multi-head QKV attention의 단일 layer로 구현된다. 두 번째 아키텍처로는 최근에 소개된 Vision Transformer (ViT)를 실험했다. ViT 구현을 거의 따르며 패치 및 position 임베딩을 트랜스포머에 추가하기 전에 추가적인 layer normalization을 추가하는 작은 수정만 적용하고 약간 다른 초기화 방식을 사용했다.
텍스트 인코더는 GPT-2에서 설명된 아키텍처 수정 사항이 적용된 Transformer이다. 기본 크기로는 8개의 attention head를 가진 63M-parameter 12-layer 512-wide 모델을 사용했다. Transformer는 49,152개의 어휘 크기를 가진 소문자화된 BPE 표현을 사용하여 작동한다. 계산 효율성을 위해 최대 시퀀스 길이는 76으로 제한되었다. 텍스트 시퀀스는 [SOS]와 [EOS] 토큰으로 묶이며 Transformer의 가장 높은 layer에서 [EOS] 토큰의 활성화는 텍스트의 특징 표현으로 처리되어 layer nomalization된 후 mult-modal 임베딩 공간으로 선형 project된다. 텍스트 인코더에는 masked self-attention이 사용되어 사전 훈련된 언어 모델로 초기화하거나 언어 모델링을 보조 목적함수로 추가할 수 있는 능력을 유지했다. 이 부분은 향후 연구로 남겨둔다.
이전의 컴퓨터 비전 연구는 주로 너비 또는 깊이만 증가시켜 모델을 확장했지만 최근 연구의 접근 방식을 채택하여 너비, 깊이, 해상도 전체에 추가 연산을 배분하는 것이 모델의 한 차원에만 배분하는 것보다 우수하다는 것을 발견했다. EfficientNet 아키텍처에 대해 각 차원에 할당된 연산 비율을 조정한 반면, 본 연구는 모델의 너비, 깊이, 해상도를 증가시키는 데 추가 연산을 동등하게 배분하는 간단한 기준선을 사용했다. 텍스트 인코더의 경우, ResNet의 너비 증가에 비례하여 모델의 너비만 확장하고 깊이는 전혀 확장하지 않았다. 이는 CLIP의 성능이 텍스트 인코더의 용량에 덜 민감하다는 것을 발견했기 때문이다.
2.5 Training
본 연구는 5개의 ResNet과 3개의 ViT를 학습시켰다. ResNet의 경우 ResNet-50, ResNet-101을 학습시켰고, EfficientNet 스타일의 모델 확장을 따라 ResNet-50의 약 4배, 16배, 64배의 연산을 사용하는 3개의 추가 모델을 학습시켰다. 이 모델들은 각각 RN50x4, RN50x16, RN50x64로 명명되었다. ViT의 경우 ViT-B/16, ViT-L/14를 학습시켰다. 모든 모델은 32 epoch 동안 학습되었다. Adam optimizer와 decoupled weight decay regularization을 사용하였으며 이는 gain이나 bias가 아닌 모든 가중치에 적용되었다. 학습률은 cosine schedule을 사용하여 감소시켰다. 초기 하이퍼파라미터는 ResNet-50 모델을 1 epoch 동안 학습시킬 때 grid searches, random search 및 manual tuning을 조합하여 설정하였다. 그 후, 하이퍼파라미터는 계산 제약으로 인해 더 큰 모델에 대해 경험적으로 조정되었다. 학습 가능한 온도 파라미터는 0.07에 해당하는 값으로 초기화되었고 logit을 100 이상으로 스케일링하지 않도록 clipping되어 학습 불안정을 방지했다. 또한, 매우 큰 미니배치 크기인 32,768을 사용하였다. 혼합 정밀도를 사용하여 학습 속도를 높이고 메모리를 절약했다. 추가 메모리를 절약하기 위해, gradient checkpointing, half-precision Adam statistics와 half-precision stochastically rounded text encoder weight를 사용하였다. 임베딩 유사도의 계산도를 공유하여 개별 GPU가 로컬 배치의 임베딩에 필요한 쌍별 유사도의 하위 집합만 계산하도록 했다. 가장 큰 ResNet 모델인 RN50x64는 592개의 V100 GPU에서 학습하는 데 18일 걸렸으며 가장 큰 ViT는 256개의 V100 GPU에서 12일이 걸렸다. ViT-L/14의 경우 성능을 향상시키기 위해 FixRes와 유사하게 더 높은 336 픽셀 해상도에서 추가로 1 epoch 동안 사전 학습했다. 이 모델을 ViT-L/14@336px로 명명한다. 별도로 명시되지 않는 한, 본 논문에서 "CLIP"으로 보고된 모든 결과는 최상의 성능을 보인 이 모델을 사용한 것이다.
3. Experiments
3.1 Zero-Shot Transfer
3.1.1 Motivation
컴퓨터 비전에서 zero-shot 학습은 일반적으로 이미지 분류에서 보지 못한 객체 범주로의 일반화를 연구하는 것을 의미한다. 본 연구는 이 용어를 더 넓은 의미로 사용하여 보지 못한 데이터셋으로의 일반화를 연구한다. 비지도 학습 분야의 많은 연구가 머신러닝 시스템의 표현 학습 능력에 맞추는 반면, 본 연구는 zero-shot 전이를 머신러닝 시스템의 작업 학습 능력을 측정하는 방법으로 연구할 동기를 부여한다. 이 관점에서 데이터셋은 특정 분포에서 task 성능을 평가한다. 그러나 많은 인기 있는 컴퓨터 비전 데이터셋은 특정 task의 성능을 측정하기보다는 일반적인 이미지 분류 방법의 개발을 안내하기 위해 주로 연구 커뮤니티에 의해 생성되었다. 예를 들어, SVHN 데이터셋은 Google Street View 사진의 분포에서 거리 숫자 전사 task를 측정한다고 할 수 있지만, CIFAR-10 데이터셋이 측정하는 "real" task가 무엇인지는 불명확하다. 이러한 종류의 데이터셋에서는 zero-shot 전이가 task 일반화보다는 분포 이동 및 도메인 일반화에 대한 CLIP 강인성을 평가하는 것이다. 이에 대한 분석은 section 3.3을 참조바란다.
task learning에 대한 집중은 NLP 분야에서 task learning을 보여주는 작업에서 영감을 받았다. GPT-1은 감독된 미세 조정을 개선하기 위한 전이 학습 방법으로 사전 학습에 초점을 맞추었지만, 네 가지 휴리스틱 zero-shot 전이 방법의 성능이 사전 학습 과정에서 점진적으로 향상되었음을 보여주는 ablation study도 포함했다. 이 분석은 GPT-2의 기초가 되었으며 이는 zero-shot 전이를 통해 언어 모델의 task learning을 연구하는 데 전적으로 초점을 맞추었다.
3.1.2 Using CLIP for Zero-Shot Transfer
CLIP은 이미지와 텍스트가 데이터셋에서 함께 짝지어져 있는지 예측하도록 사전 학습되었다. zero-shot 분류를 수행하기 위해, 본 연구는 이 기능을 재사용한다. 각 데이터셋에 대해 데이터셋의 모든 클래스 이름을 잠재적 텍스트 쌍의 집합으로 사용하고 CLIP에 따라 가장 가능성 있는 (이미지, 텍스트) 쌍을 예측한다. 좀 더 자세히 설명하면, 먼저 이미지의 특징 임베딩과 가능한 텍스트 집합의 특징 임베딩을 각각의 인코더로 계산한다. 그런 다음 이러한 임베딩의 코사인 유사성을 계산하고 온도 매개변수로 스케일링한 후 softmax를 통해 확률 분포로 정규화한다. 이 예측 레이어는 L2-normalized weight와 바이어스가 없는 다항 로지스틱 회귀 분류기이며 온도 스케일링이 적용된 것과 같다. 이렇게 해석하면, 이미지 인코더는 이미지에 대한 특징 표현을 계산하는 컴퓨터 비전 백본이고 텍스트 인코더는 클래스가 나타내는 시각적 개념을 명시하는 텍스트를 기반으로 선형 분류기의 가중치를 생성하는 하이퍼네트워크이다. CLIP 사전 학습의 모든 단계는 자연어 설명을 통해 정의된 32,768개의 총 클래스를 가진 컴퓨터 비전 데이터셋에 대한 무작위로 생성된 프록시의 성능을 최적화하는 것으로 볼 수 있다. zero-shot 평가를 위해 텍스트 인코더에 의해 계산된 zero-shot 분류기를 캐시하고 이후 모든 예측에 대해 재사용한다. 이를 통해 생성 비용을 데이터셋의 모든 예측에 걸쳐 분산할 수 있다.
3.1.3 Initial Comparison To Visual N-grams
Table 1에서 Visual N-Grams와 CLIP을 비교한다. 최고의 CLIP 모델은 ImageNet에서 정확도를 개념 증명 수준의 11.5%에서 76.2%로 향상시키고 이 데이터셋에 사용 가능한 128만 개의 군중 레이블 학습 예제를 전혀 사용하지 않고도 원래 ResNet-50의 성능과 일치한다. 추가적으로, CLIP 모델의 상위 5개 정확도는 상위 1개 정확도보다 눈에 띄게 높으며 이 모델은 95%의 상위 5개 정확도로 Inception-V4와 일치한다. 강력한 완전 지도학습된 기준의 성능을 zero-shot 설정에서 일치시키는 능력은 CLIP이 유연하고 실용적인 zero-shot 컴퓨터 비전 분류기로 나아가는 중요한 단계임을 시사한다. 위에서 언급한 바와 같이, Visual N-Grams와의 비교는 CLIP의 성능을 맥락화하기 위한 것이며 CLIP과 Visual N-Grams 간의 직접적인 방법 비교로 해석해서는 안된다. 두 시스템 간의 성능 관련 많은 차이점이 통제되지 않았기 때문이다. 예를 들어, CLIP은 10배 더 큰 데이터셋에서 학습하고 예측당 거의 100배 더 많은 계산을 필요로 하는 비전 모델을 사용하며 그들의 학습 계산의 1000배 이상을 사용했으며 Visual N-Grams가 발표될 때 존재하지 않았던 transformer 기반 모델을 사용했다. 더 가까운 비교를 위해, Visual N-Grams가 학습된 것과 동일한 YFCC100M 데이터셋에서 CLIP ResNet-50을 학습시켰고 V100 GPU 하루 내에 보고된 ImageNet 성능을 일치시켰다. 이 기준선은 Visual N-Grams에서처럼 사전 학습된 ImageNet 가중치에서 초기화되지 않고 처음부터 학습되었다.
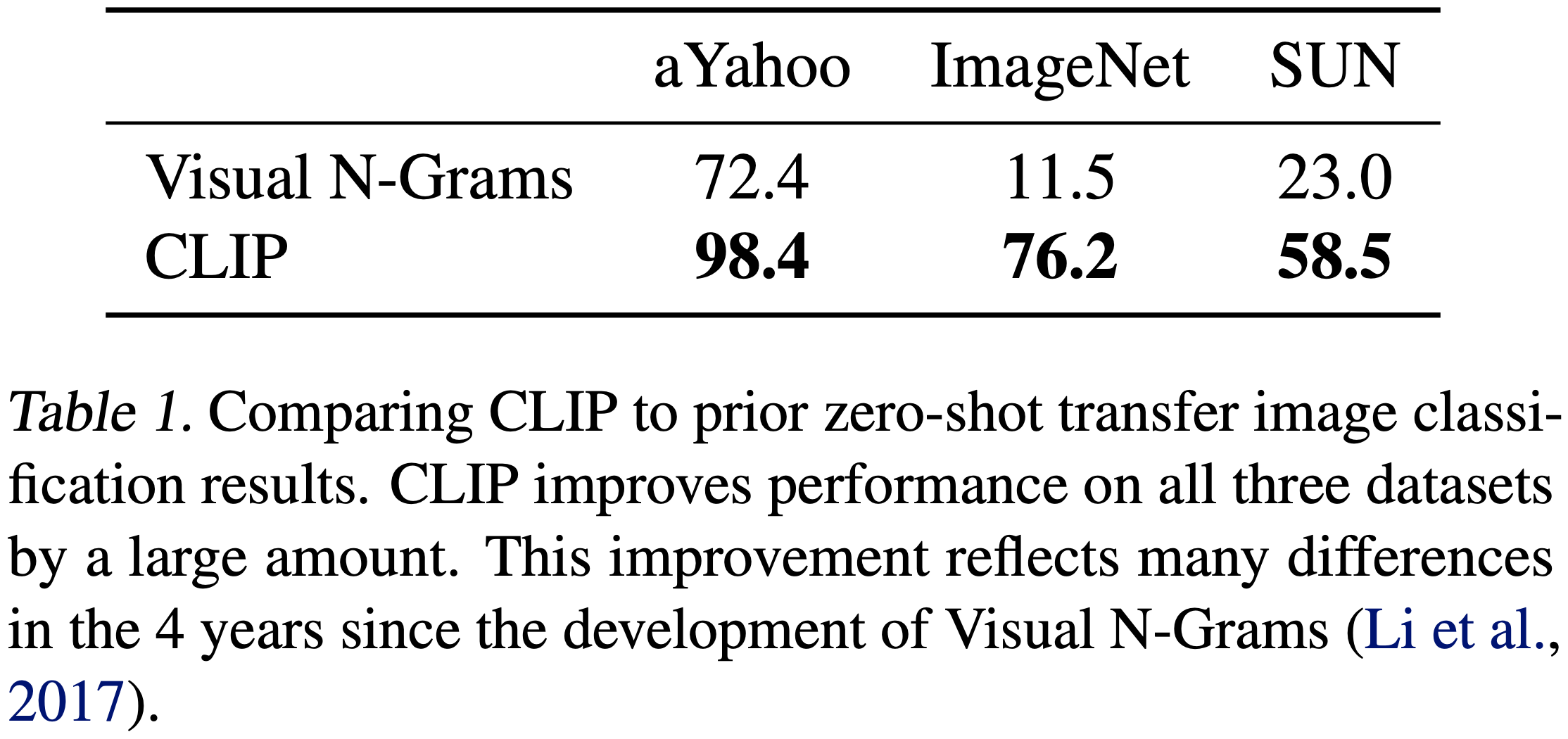
CLIP은 또한 다른 2개의 보고된 데이터셋에서 Visual N-Grams를 능가한다. aYahoo에서 CLIP은 오류 수를 95%를 줄였으며, SUN에서는 Visual N-Grams의 정확도를 두 배 이상 높였다. 더 포괄적인 분석과 스트레스 테스트를 수행하기 위해, 부록 A에 자세히 설명된 훨씬 큰 평가를 구현했다. 총 3개의 데이터셋에서 Visual N-Grams가 보고한 것에서 30개 이상의 데이터셋을 포함하도록 확장하고 결과를 맥락화하기 위해 50개 이상의 기존 컴퓨터 비전 시스템과 비교한다.
3.1.4 Prompt Engineering and Ensembling
대부분의 표준 이미지 분류 데이터셋은 자연어 기반 zero-shot 전이를 가능하게 하는 클래스의 이름이나 설명 정보를 나중에 생각하는 후순위로 취급한다. 대부분의 데이터셋은 레이블의 숫자 ID만으로 이미지를 주석 처리하고 이러한 ID를 영어 이름으로 다시 매핑하는 파일을 포함하고 있다. Flowers102와 GTSRB와 같은 일부 데이터셋은 이러한 매핑을 전혀 포함하지 않아서 zero-shot 전이를 완전히 방지한다. 많은 데이터셋에서 이러한 레이블이 다소 무작위로 선택된 것으로 보이며 성공적인 전이를 위해 task description에 의존하는 zero-shot 전이와 관련된 문제를 예측하지 않는다.
공통적인 문제는 다의성이다. 클래스의 이름만 CLIP의 텍스트 인코더에 제공될 때, 문맥의 부족으로 인해 어떤 단어 의미가 의도된 것인지 구별할 수 없다. 일부 경우에는 동일한 단어의 여러 의미가 동일한 데이터셋의 다른 클래스로 포함될 수도 있다. 이는 건설 크레인과 날아다니는 새 크레인 모두를 포함하는 ImageNet에서 발생한다. 또 다른 예로는 Oxford-IIIT Pet 데이터셋의 클래스에서 'boxer'라는 단어가 문맥상 개 품종을 나타내지만, 문맥이 부족한 텍스트 인코더에는 운동선수의 한 유형을 나타낼 수도 있다.
또 다른 문제는 이미지와 짝지어진 텍스트가 단일 단어인 경우가 사전 학습 데이터셋에서 상대적으로 드물다는 점이다. 일반적으로 텍스트는 이미지를 어떤 식으로든 설명하는 전체 문장이다. 이 분포 차이를 줄이기 위해, "A photo of a {label}."이라는 프롬프트 템플릿을 사용하는 것이 텍스트가 이미지의 내용을 설명하는 것임을 명확히 하는 데 도움이 된다는 것을 발견했다. 이것은 단순히 레이블 텍스트를 사용하는 것보다 성능을 자주 향상시킨다. 예를 들어, 이 프롬프트를 사용하는 것만으로도 ImageNet에서 정확도가 1.3% 향상된다.
GPT-3와 관련된 "prompt engineering" 논의와 유사하게, zero-shot 성능이 각 task에 맞게 프롬프트 텍스트를 사용자 지정함으로써 상당히 향상될 수 있음을 관찰했다. 몇 가지 비포괄적인 예가 뒤따른다. 여러 세밀한 이미지 분류 데이터셋에서 카테고리를 지정하는 것이 도움이 된다는 것을 발견했다. 예를 들어 Oxford-IIIT Pets에서는 "A photo of a {label}, a type of pet."이라는 프롬프트를 사용하여 문맥을 제공하는 것이 효과적이었다. 마찬가지로 Food101에서는 음식 유형을 지정하고 FGVC Aircraft에서는 항공기 유형을 지정하는 것이 도움이 되었다. OCR 데이터셋에서는 인식할 텍스트나 숫자에 따옴표를 넣는 것이 성능을 향상시켰다. 마지막으로, 위성 이미지 분류 데이터셋에서는 이미지가 이러한 형태라는 것을 지정하는 것이 도움이 되었으며 "a satellite photo of a {label}."와 같은 변형을 사용했다.
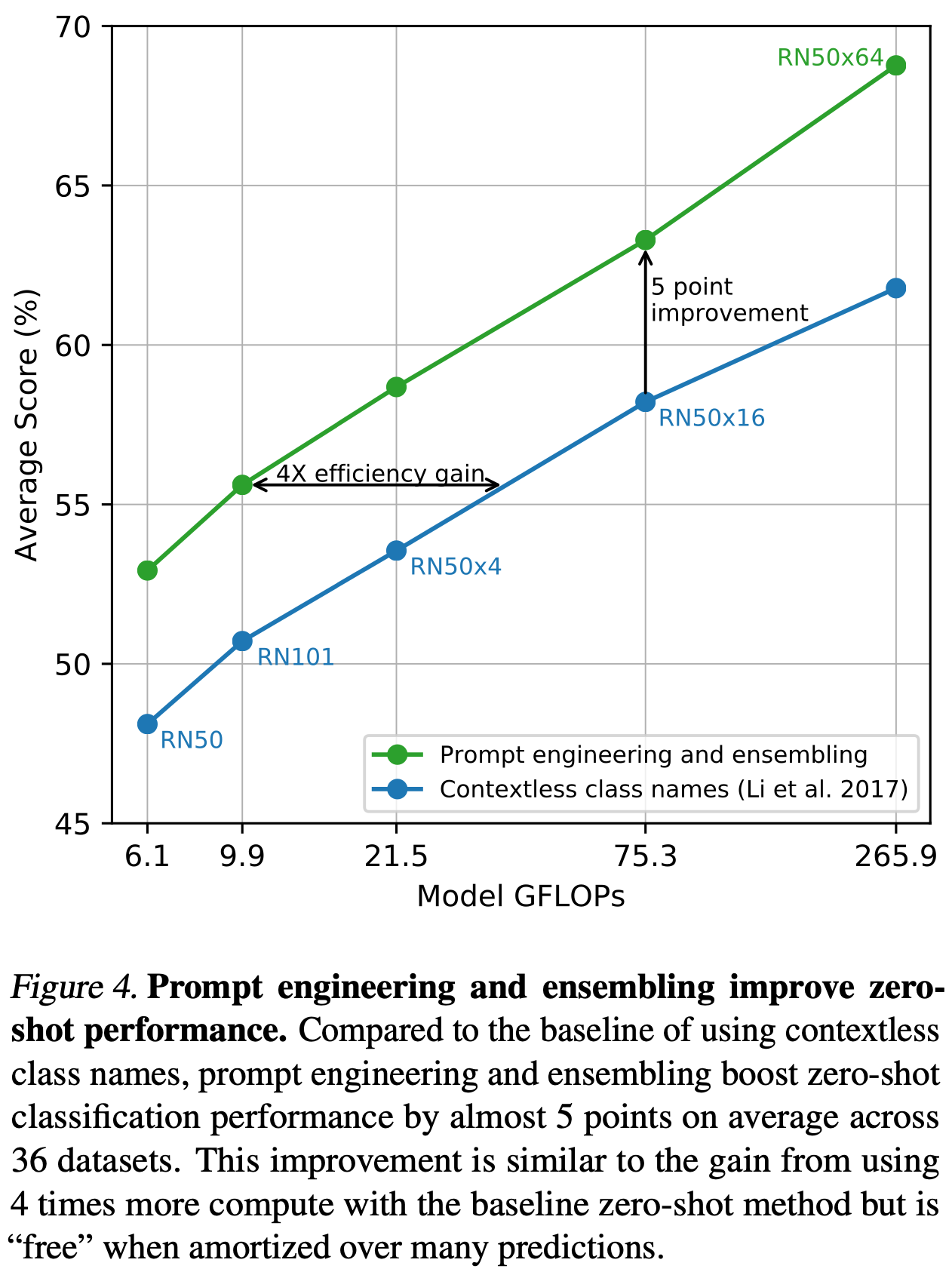
또한 성능을 향상시키는 또 다른 방법으로 여러 zero-shot 분류기를 앙상블하는 실험도 했다. 이러한 분류기는 "A photo of a big {label}" 및 "A photo of a small {label}"와 같은 다양한 문맥 프롬프트를 사용하여 계산된다. 확률 공간 대신 임베딩 공간에서 앙상블을 구성한다. 이를 통해 단일 프롬프트를 사용하는 경우와 마찬가지로 단일 세트의 평균 텍스트 임베딩을 캐시하여 앙상블의 계산 비용을 예측 전체에 걸쳐 분산할 수 있다. 여러 생성된 zero-shot 분류기를 앙상블하여 성능이 안정적으로 향상되는 것을 관찰했으며 이를 대부분의 데이터셋에 사용한다. ImageNet에서는 80개의 다른 문맥 프롬프트를 앙상블하여 앞서 논의한 단일 기본 프롬프트보다 성능이 추가로 3.5% 향상되었다. 프롬프트 엔지니어링과 앙상블링을 함께 고려할 때, ImageNet의 정확도는 거의 5% 향상된다. Figure 4에서 클래스 이름을 직접 임베딩하는 문맥 없는 기본 접근 방식과 비교하여 프롬프트 엔지니어링과 앙상블이 CLIP 모델 성능에 어떻게 변화를 주는지 시각화했다.
3.1.5 Analysis of Zero-Shot CLIP Performance
컴퓨터 비전에서 task-agnostic zero-shot 분류기는 충분히 연구되지 않았기 때문에, CLIP은 이러한 유형의 모델에 대한 더 나은 이해를 얻을 수 있는 유망한 기회를 제공한다. 이 섹션에서는 CLIP의 zero-shot 분류기의 다양한 속성에 대한 연구를 수행한다. 첫 번째 질문으로, zero-shot 분류기가 얼마나 잘 수행하는지 단순히 살펴본다. 이를 맥락화하기 위해, 정규화된 로지스틱 회귀 분류기를 표준 ResNet-50의 특징에 맞춘 간단한 베이스라인과 비교한다. Figure 5에서 27개의 데이터셋에 걸친 이 비교를 보여준다. 데이터셋 및 설정에 대한 자세한 내용은 부록 A를 참조하면 된다.
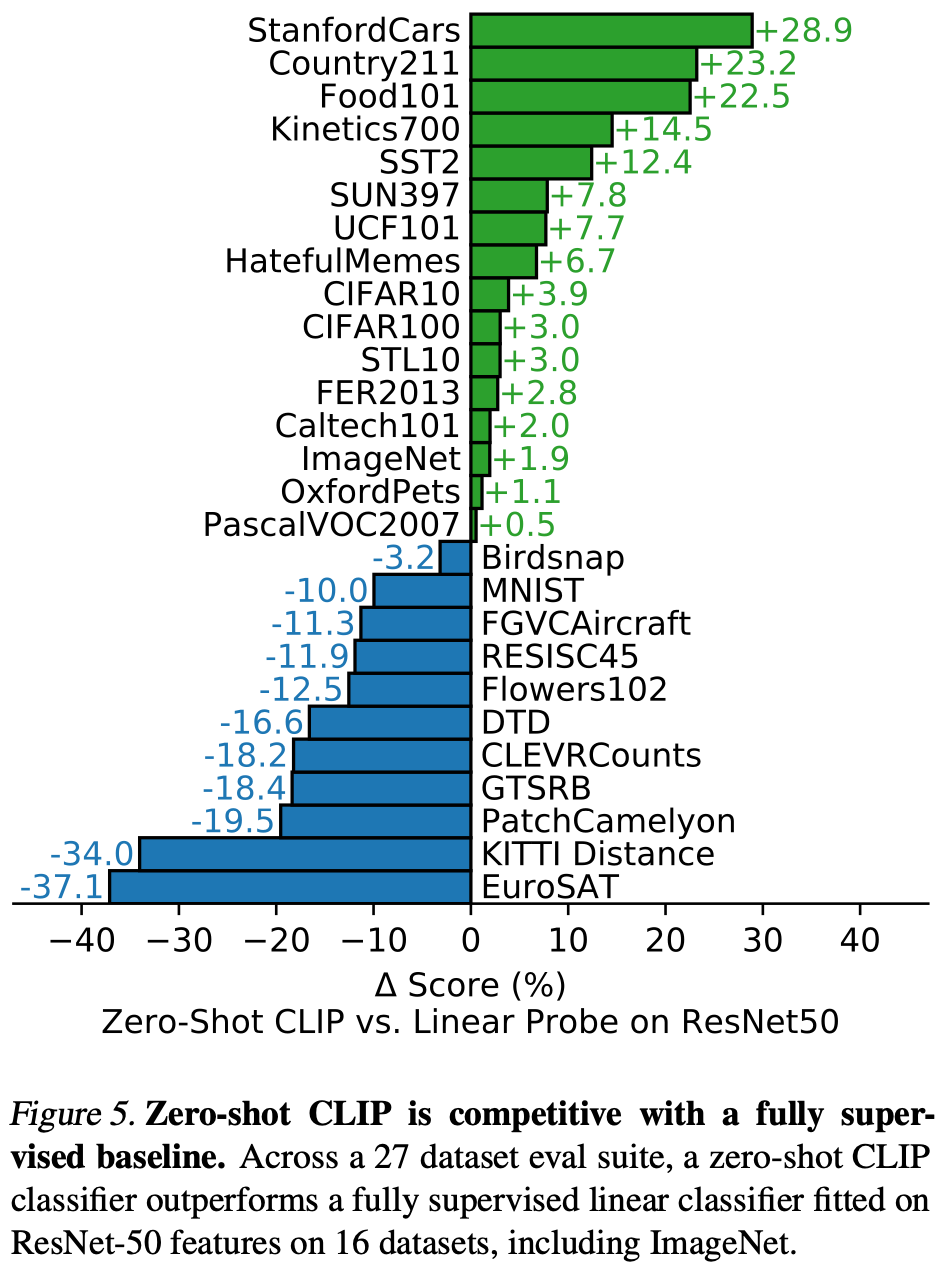
zero-shot CLIP은 27개의 데이터셋 중 16개에서 베이스라인을 약간 더 자주 능가한다. 개별 데이터셋을 살펴보면 흥미로운 것을 관찰할 수 있다. 세밀한 분류 task에서는 성능에 넓은 차이가 있음을 관찰한다. 두 개의 데이터셋, Stanford Carsdhk Food101에서 zero-shot CLIP은 ResNet-50 특징의 로지스틱 회귀를 20% 이상 능가하지만, Flowers102와 FGVCAircraft에서는 10% 이상 미달한다. OxfordPets와 Birdsnap에서는 성능이 매우 비슷하다. 이러한 차이는 주로 WIT와 ImageNet 간의 task별 감독 양의 차이 때문이라고 의심된다. ImageNet, CIFAR10/100, STL10, PascalVOC2007과 같은 "general" 객체 분류 데이터셋에서는 성능이 상대적으로 비슷하며 모든 경우에서 약간의 이점이 있다. STL10에서는 CLIP이 99.3%의 정확도를 달성하여 학습 예제를 전혀 사용하지 않음에도 불구하고 SOTA 성능을 달성한다. zero-shot CLIP은 비디오에서 행동 인식을 측정하는 두 개의 데이터셋에서도 ResNet-50을 크게 능가한다. Kinetics700에서 CLIP은 ResNet-50보다 14.5% 더 뛰어나다. UCF101에서는 zero-shot CLIP이 ResNet-50의 특징보다 7.7% 더 뛰어나다. 이는 자연어가 동사와 관련된 시각적 개념에 대해 더 넓은 감독을 제공하기 때문일 가능성이 높다. 반면에 ImageNet은 명사 중심의 객체 감독을 제공한다.
zeor-shot CLIP이 눈에 띄게 성능이 떨어지는 곳을 살펴보면, zero-shot CLIP은 위성 이미지 분류 (EuroSAT와 RESISC45), 림프절 종양 감지 (PatchCamelyon), 합성 장면에서 객체 수 세기 (CLEVRCounts), 독일 교통 표지 인식 (GTSRB), 가장 가까운 자동차까지의 거리 인식 (KITTI Distance)과 같은 몇 가지 전문화된 복잡한 또는 추상적인 task에서 상당히 약하다는 것을 알 수 있다. 이러한 결과는 zero-shot CLIP의 복잡한 task에 대한 능력이 부족하다는 것을 강조한다. 대조적으로, 위성 이미지 분류, 교통 표지 인식과 같은 여러 task를 견고하게 수행할 수 있으므로 상당한 개선의 여지가 있음을 시사한다. 그러나 거의 모든 인간 (그리고 아마도 CLIP)에게 림프절 종양 분류와 같은 어려운 task에 대해 zero-shot 전이를 측정하는 것이 의미 있는 평가인지 여부는 불분명하므로 주의가 필요하다.
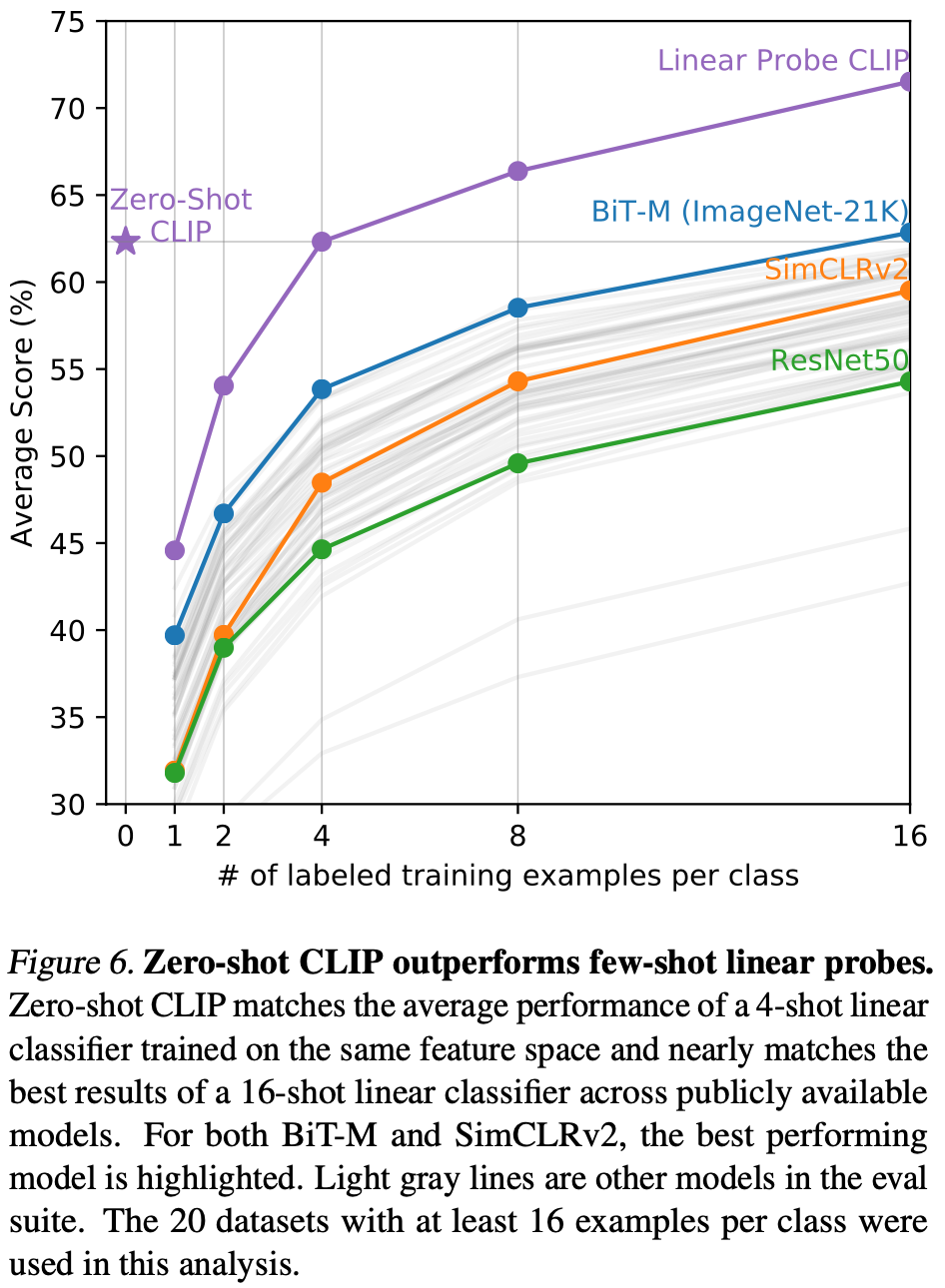
zero-shot 성능을 완전 감독된 모델과 비교하는 것은 CLIP의 작업 학습 능력을 맥락화하는 것이지만, zero-shot이 그 한계인 만큼 few-shot 방법과 비교하는 것이 더 직접적인 비교이다. Figure 6에서 zero-shot CLIP이 여러 이미지 모델의 특징 공간에서 few-shot 로지스틱 회귀와 어떻게 비교되는지 시각화한다. zero-shot이 one-shot보다 성능이 떨어질 것이라고 예상하는 것이 직관적이지만 zero-shot CLIP은 동일한 특징 공간에서 4-shot 로지스틱 회귀의 성능과 일치한다는 것을 발견했다. 이는 zero-shot 접근 방식과 few-shot 접근 방식 사이의 중요한 차이점 때문일 가능성이 크다. 첫째, CLIP의 zero-shot 분류기는 자연어를 통해 생성되므로 시각적 개념을 직접 지정할 수 있다. 반면에 "normal" 감독 학습은 학습 예제에서 간접적으로 개념을 추론해야 한다. 문맥 없는 예제 기반 학습은 특히 one-shot 경우에 데이터와 일치하는 많은 다른 가설이 있을 수 있다는 단점이 있다. 단일 이미지에는 종종 많은 다른 시각적 개념이 포함되어 있다. 유능한 학습자는 시각적 단서와 휴리스틱을 활용할 수 있지만, 예를 들어 이미지의 주요 객체가 시연되는 개념이라고 가정하는 등의 보장은 없다.
zero-shot과 few-shot 성능 간의 이러한 불일치를 해결하는 잠재적인 방법은 CLIP의 zero-shot 분류기를 few-shot 분류기의 가중치에 대한 사전으로 사용하는 것이다. 생성된 가중치에 대한 L2 패널티를 추가하는 것은 이 아이디어의 간단한 구현이지만, 하이퍼파라미터 최적화는 종종 이 정규화 값을 선택하여 결과적인 few-shot 분류기가 단지 zero-shot 분류기였음을 발견했다. zero-shot 전이의 강점과 few-shot 학습의 유연성을 결합하는 더 나은 방법에 대한 연구는 미래의 유망한 방향이다.
zero-shot CLIP을 다른 모델의 few-shot 로지스틱 회귀와 비교할 때, zero-shot CLIP은 평가 모음에서 ImageNet-21K에서 훈련된 BiT-M ResNet-152x2의 특징을 사용하는 최고 성능의 16-shot 분류기와 대략 일치한다. JFT-300M에서 훈련된 BiT-L 모델이 훨씬 더 나은 성능을 발휘할 것이라는 것은 확실하지만, 이러한 모델은 공개적으로 출시되지 않았다. BiT-M ResNet-152x2가 16-shot 설정에서 가장 뛰어난 성능을 발휘한다는 것은 다소 놀랍다. 이는 섹션 3.2에서 분석한 바와 같이, 완전 감독된 설정에서 Noisy Student EfficientNet-L2가 27개의 데이터셋에서 평균적으로 거의 5% 더 나은 성능을 발휘한다는 것과 대조된다.
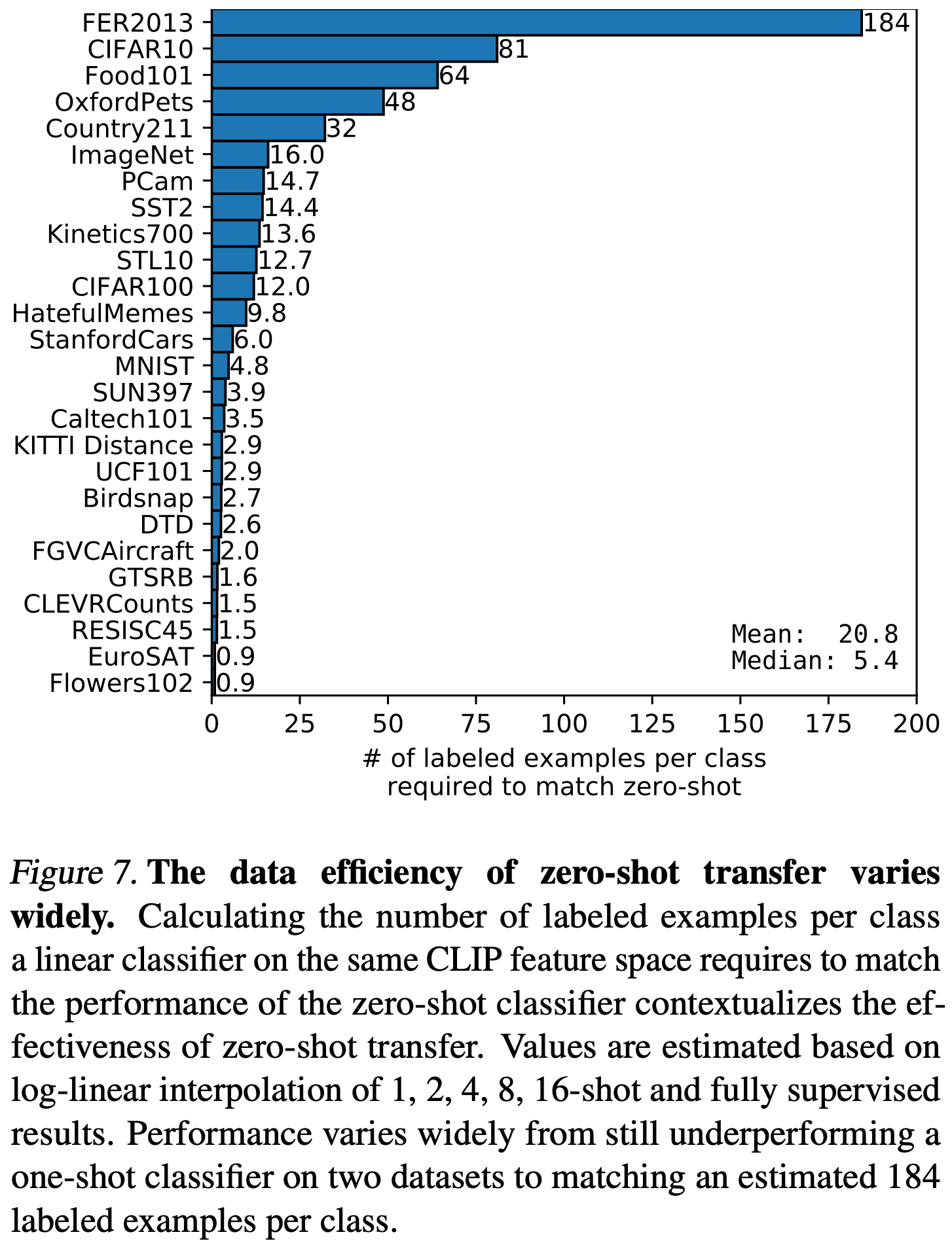
zero-shot CLIP과 few-shot 로지스틱 회귀의 평균 성능을 연구하는 것 이외에도 개별 데이터셋에서의 성능도 분석했다. Figure 7에서는 동일한 특징 공간에서 zero-shot CLIP의 성능을 맞추기 위해 로지스틱 회귀 분류기가 필요로 하는 클래스별 라벨 예제 수를 보여준다. zero-shot CLIP도 선형 분류기이므로 이는 이 설정에서 zero-shot 전이의 효과적인 데이터 효율성을 추정한다. 수천 개의 선형 분류기를 훈련하는 것을 피하기 위해, 각 데이터셋에서 1, 2, 4, 8, 16-shot 및 완전히 감독된 선형 분류기의 성능을 기반으로 한 로그-선형 보간법을 사용하여 효과적인 데이터 효율성을 추정한다. zero-shot 전이는 데이터셋마다 효율성이 크게 달라질 수 있음을 발견했다. 클래스 당 라벨 예제가 1개 미만에서 184개까지 다양하다. 두 개의 데이터셋 Flowers102와 EuroSAT는 one-shot 모델보다 성능이 떨어진다. 데이터셋의 절반은 클래스당 5개 미만의 예제를 필요로 하며 중간값은 5.4이다. 그러나 평균 추정 데이터 효율성은 클래스 당 20.8 예제이다. 이는 성능을 맞추기 위해 많은 클래스별 라벨 예제를 필요로 하는 데이터셋의 20% 때문이다. ImageNet에서는 zero-shot CLIP이 동일한 특징 공간에서 훈련된 16-shot 선형 분류기의 성능을 맞춘다.
평가 데이터셋이 선형 분류기 훈련에 충분히 크다고 가정하면, CLIP의 zero-shot 분류기도 선형 분류기이기 때문에 완전히 감독된 분류기의 성능이 zero-shot 전이가 달성할 수 있는 상한선을 대략 설정한다. Figure 8에서는 데이터셋 간에 CLIP의 zero-shot 성능과 완전히 감독된 선형 분류기의 성능을 비교한다. 점선, y=x 라인은 완전히 감독된 등가의 성능을 맞추는 최적의 zero-shot 분류기를 나타낸다. 대부분의 데이터셋에서 zero-shot 분류기의 성능은 여전히 완전히 감독된 분류기보다 10%에서 25%정도 낮아, CLIP의 task 학습 및 zero-shot 전이 능력을 개선할 여지가 많음을 시사한다.
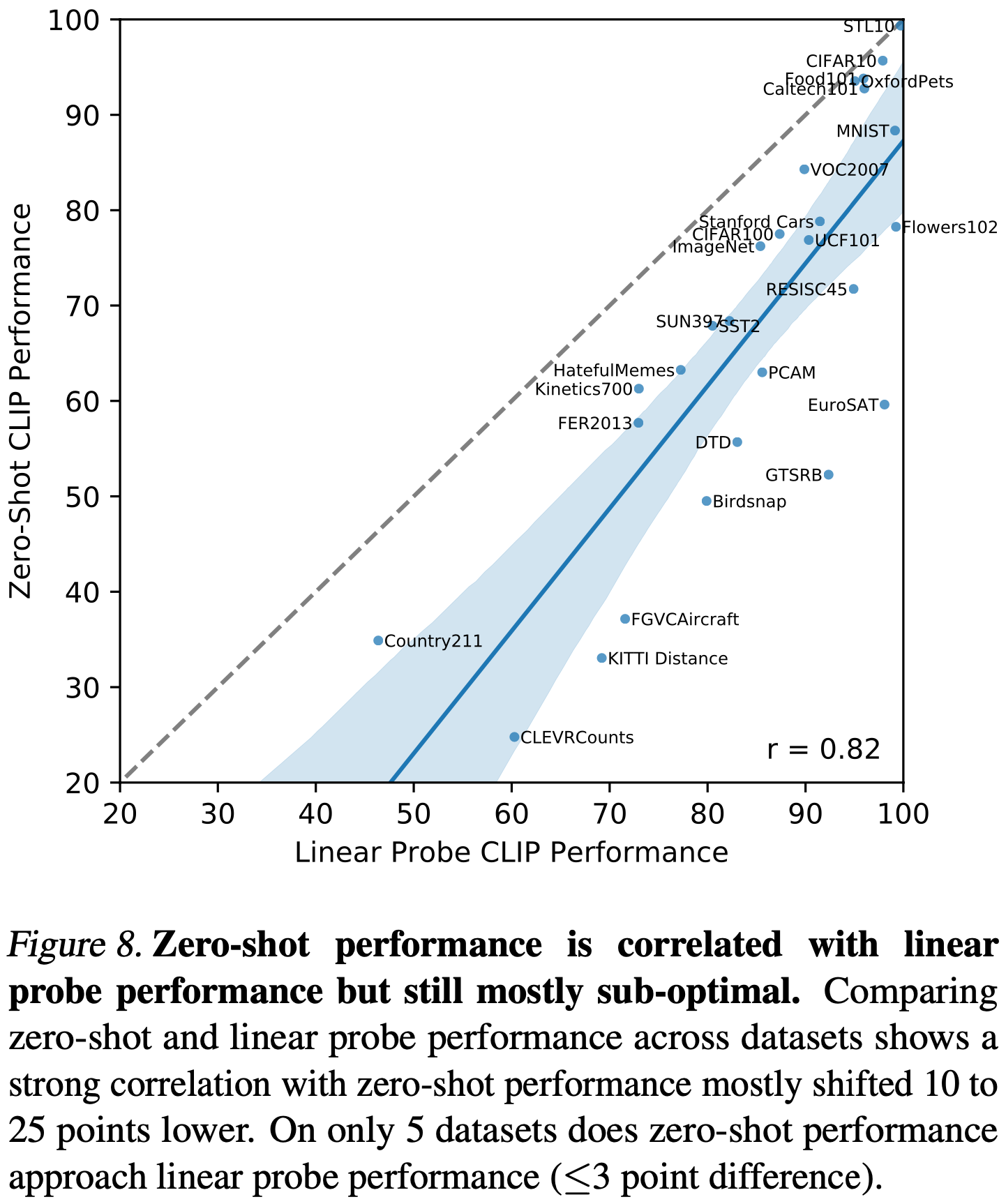
zero-shot 성능과 완전히 감독된 성능 사이에는 0.82의 양의 상관관계가 있으며 (p-value < 10^-6), 이는 CLIP이 기본 표현과 task 학습을 zero-shot 전이로 연결하는 데 비교적 일관성이 있음을 시사한다. 그러나 zero-shot CLIP은 5개의 데이터셋 STL10, CIFAR10, Food101, OxfordPets, Caltech101에서만 완전히 감독된 성능에 접근한다. 이 5개의 데이터셋에서는 zero-shot 정확도와 완전히 감독된 정확도가 모두 90% 이상이다. 이는 CLIP이 기본 표현이 높은 품질인 작업에서 zero-shot 전이에 더 효과적일 수 있음을 시사한다. 완전히 감독된 성능의 함수로서 zero-shot 성능을 예측하는 선형 회귀 모델의 기울기는 완전히 감독된 성능이 1% 향상될 때마다 zero-shot 성능이 1.28% 향상된다는 것을 추정한다. 그러나 95번째 백분위수 신뢰 구간은 여전히 1 미만의 값을 포함한다.
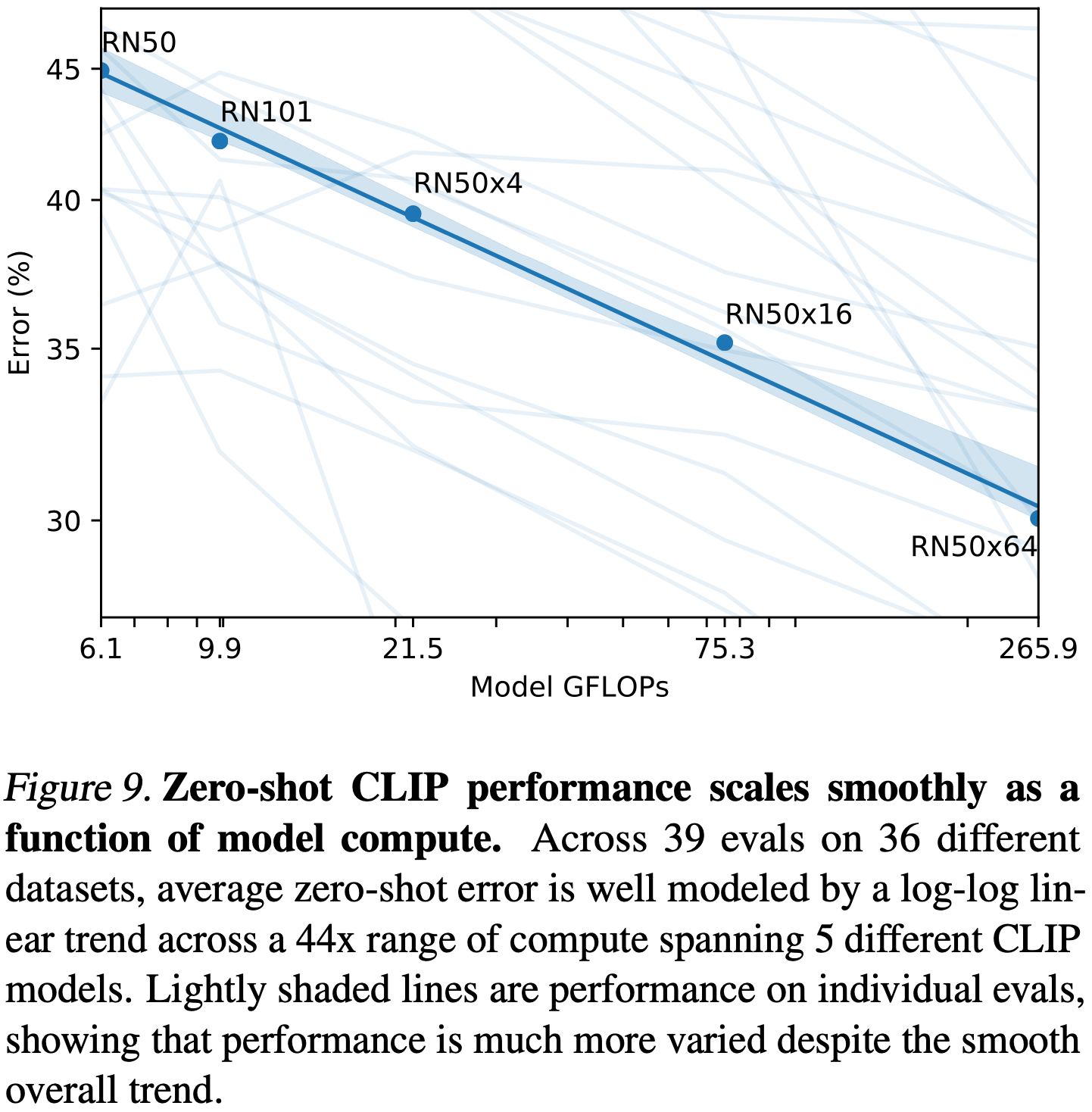
지난 몇 년간, 딥러닝 시스템의 경험적 연구는 훈련 계산 및 데이터셋 크기와 같은 중요한 양의 함수로서 성능이 예측 가능함을 문서화했다. GPT 모델 계열은 지금까지 훈련 계산의 1000배 증가에 걸쳐 zero-shot 성능의 일관된 개선을 보여주었다. Figure 9에서 CLIP의 zero-shot 성능이 유사한 스케일링 패턴을 따르는지 확인한다. 36개의 다른 데이터셋에 대한 39번의 평가에서 5개의 ResNet CLIP 모델의 평균 오류율을 플로팅하고 모델 계산이 44배 증가하는 동안 CLIP의 유사한 log-log 선형 스케일링 추세를 발견했다. 전체 추세는 원활하지만, 개별 평가의 성능은 훨씬 더 변동이 심할 수 있다. 이는 sub task에서 개별 훈련 실행 간의 높은 분산이 꾸준히 개선되는 추세를 가리는 것인지 또는 일부 task에서 성능이 실제로 계산의 함수로 비단조적인 것인지 확실하지 않는다.
3.2 Representation Learning
이전 섹션에서 zero-shot 전이를 통해 CLIP의 task 학습 능력을 광범위하게 분석했지만 모델의 표현 학습 능력을 연구하는 것이 더 일반적이다. 표현의 품질을 평가하는 여러 방법이 있으며 이상적인 표현이 가져야 할 속성에 대한 의견 차이가 존재한다. 모델에서 추출한 표현에 선형 분류기를 맞추고 다양한 데이터셋에서 그 성능을 측정하는 것이 일반적인 접근 방식이다. 대안으로는 모델의 end-to-end fine-tuning 성능을 측정하는 것이다. 이는 유연성을 높이며 이전 연구에서는 대부분의 이미지 분류 데이터셋에서 fine-tuning이 선형 분류보다 뛰어나다는 것을 확실하게 보여주었다. fine-tuning의 높은 성능은 실용적인 이유로 연구를 동기부여하지만 여러 이유로 선형 분류 기반 평가를 선택한다. 본 연구는 고성능의 task 및 데이터셋 무관 사전 학습 접근 방식을 개발하는 데 중점을 두고 있다. fine-tuning은 fine-tuning 단계 동안 각 데이터셋에 표현을 적응시킴으로써 사전 학습 단계 동안 일반적이고 견고한 표현을 학습하는 데 실패할 가능성을 보완하고 잠재적으로 숨길 수 있다. 선형 분류기는 제한된 유연성 때문에 이러한 실패를 강조하고 개발 과정에서 명확한 피드백을 제공한다. CLIP의 경우, 감독된 선형 분류기를 훈련하는 것은 zero-shot 분류기에서 사용된 접근 방식과 매우 유사하여 섹션 3.1에서 광범위한 비교와 분석을 가능하게 한다. 마지막으로, 여러 task에 걸쳐 기존 모델의 종합적인 집합과 CLIP을 비교하려 한다. 27개의 다른 데이터셋에서 66개의 다른 모델을 연구하는 것은 1782개의 다른 평가를 조정해야한다. fine-tuning은 더 큰 디자인과 하이퍼파라미터 공간을 열어주며 이는 공정하게 평가하기 어렵고 다양한 기술을 비교하는 데 비용이 많이 든다. 이에 비해, 선형 분류기는 최소한의 하이퍼파라미터 조정이 필요하며 표준화된 구현 및 평가 절차를 가지고 있다. 평가에 대한 자세한 내용은 부록 A를 참고하면 된다.
Figure 10은 본 연구에서의 발견을 요약한 것이다. reporting 편향 또는 보고 편향에 대한 우려를 최소화하기 위해 12개 데이터셋 평가 suite에서 성능을 먼저 연구한다. ResNet-50 및 ResNet-101과 같은 작은 CLIP 모델은 ImageNet-1K에서 훈련된 다른 ResNet (BiT-S 및 원본)보다 우수하지만, ImageNet-21K에서 훈련된 ResNet (BiT-M)보다는 성능이 낮다. 이러한 작은 CLIP 모델은 유사한 계산 요구사항을 가진 EfficientNet 계열의 모델보다 성능이 떨어진다. 그러나 CLIP으로 훈련된 모델은 매우 잘 확장되며, 훈련한 가장 큰 모델 (ResNet-50x64)은 전체 점수와 계산 효율성에서 기존의 최고 성능 모델 (Noisy Student EfficientNet-L2)보다 약간 우수하다. 이는 CLIP이 계산 예산 내에서 더 높은 전체 성능을 달성할 수 있게 한다. CLIP은 336 픽셀의 더 높은 해상도에서 1 추가 epoch동안 데이터셋에서 fine-tuning된 ViT-L/14이다. 이 모델은 이 평가 suite에서 기존의 최고 성능 모델을 평균 2.6% 초과한다.
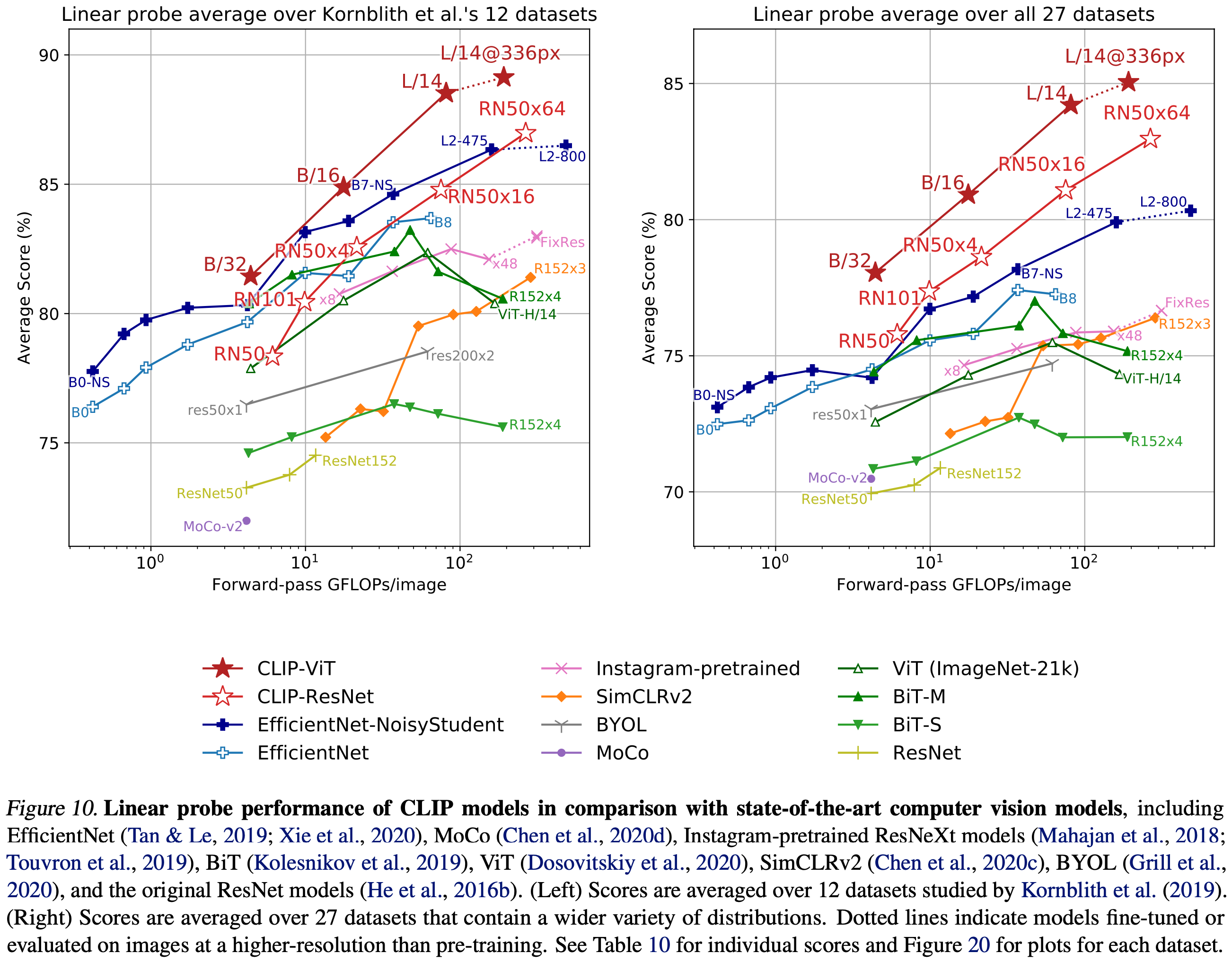
Figure 21에서 질적으로 보여주듯이, CLIP 모델은 이전에 무작위 초기화에서 끝까지 훈련된 단일 컴퓨터 비전 모델에서 입증된 것보다 더 넓은 task를 학습한다. 이러한 task에는 지리적 위치 확인, 광학 문자 인식, 얼굴 감정 인식 및 동작 인식이 포함된다. 이러한 task 중 어느 것도 위에서 수행한 평가 suite에서는 측정되지 않았다. 이를 해결하기 위해 더 광범위한 27개 데이터셋 평가 suite에서도 성능을 측정한다. 부록 A에 자세히 설명된 이 평가 suite에는 앞서 언급한 task, 독일 교통 표지 인식 벤치마크 및 VTAB에서 적응된 여러 다른 데이터셋이 포함된다.

더 넓은 평가 suite에서 CLIP의 장점이 더 명확해진다. 모든 CLIP 모델은 규모에 관계없이 계산 효율성 면에서 평가된 모든 시스템을 능가한다. 최고 모델이 이전 시스템보다 평균 점수가 2.6%에서 5%로 증가한다. 또한, 자가 지도 학습 시스템이 더 넓은 평가 suite에서 눈에 띄게 더 나은 성능을 보이는 것을 발견했다. 예를 들어, SimCLRv2는 12개 데이터셋에서는 여전히 BiT-M보다 평균적으로 성능이 낮지만, CLIP의 27개 데이터셋 평가 suite에서는 BiT-M을 능가한다. 이러한 발견은 시스템의 일반적인 성능을 더 잘 이해하기 위해 task 다양성과 범위를 계속 확장해야 한다는 것을 시사한다. VTAB과 같은 추가 평가 노력이 가치 있을 것으로 예상한다.
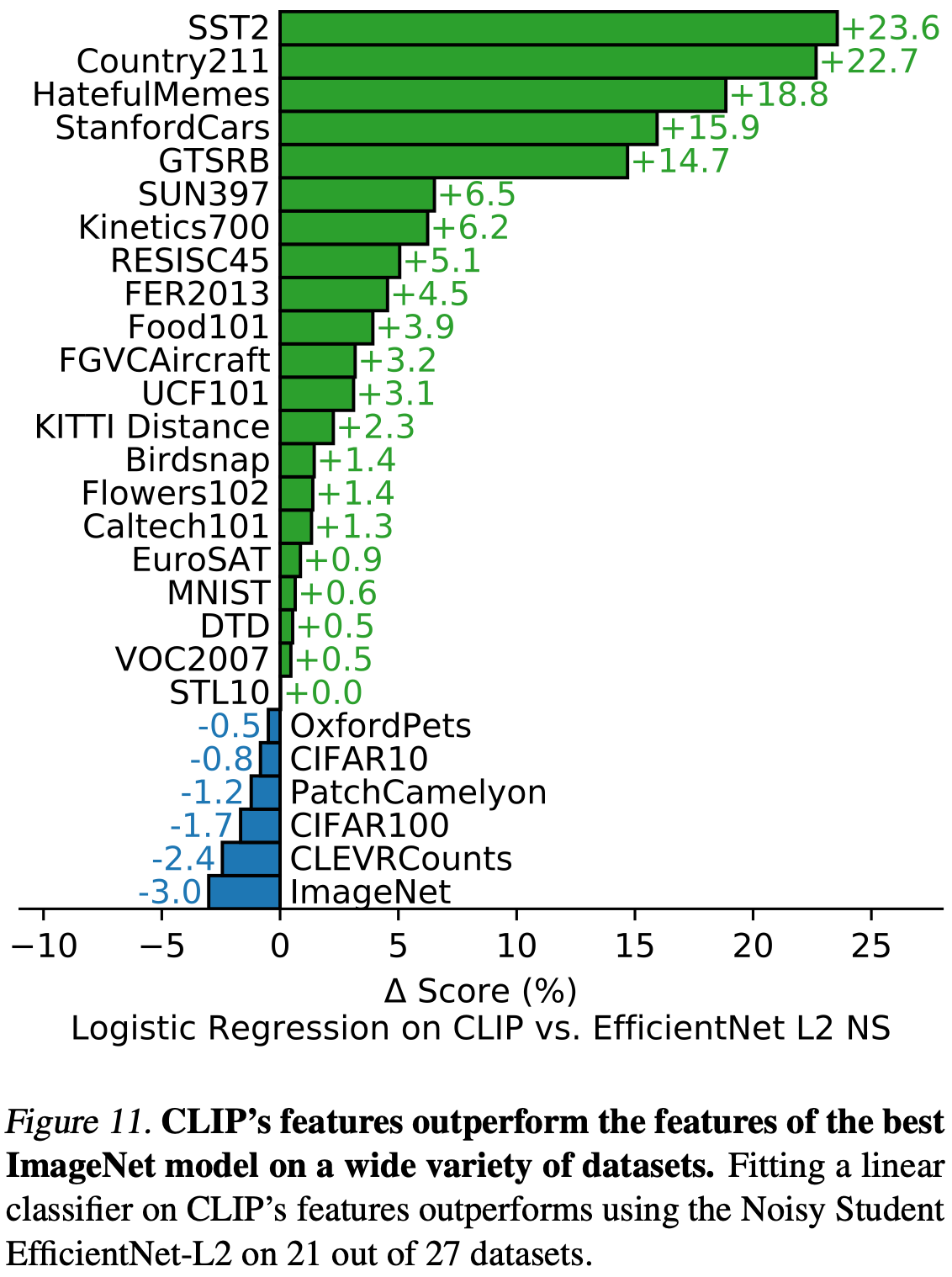
위의 종합 분석에 더하여 Figure 11에서는 모든 27개 데이터셋에서 최고의 CLIP 모델과 평가 suite의 최고 모델 간의 데이터셋별 성능 차이를 시각화한다. CLIP은 27개 데이터셋 중 21개에서 Noisy Student EfficientNet-L2를 능가한다. CLIP은 OCR이 필요한 task (SST2 및 HatefulMemes), 지리적 위치 파악 및 장면 인식 (Country211, SUN397), 비디오에서의 활동 인식 (Kinetics700 및 UCF101)에서 가장 큰 개선을 보인다. 또한, CLIP은 정밀한 자동차 및 교통 표지 인식 (Stanford Cars 및 GTSRB)에서도 훨씬 더 나은 성능을 보인다. 이는 ImageNet의 지나치게 좁은 감독 문제를 반영할 수 있다. GTSRB에서 14.7% 개선과 같은 결과는 모든 교통 및 도로 표지에 대해 단일 레이블만 있는 ImageNet-1K의 문제를 나타낼 수 있다. 이는 감독된 표현이 클래스 내 세부 사항을 축소하고 정밀한 후속 작업에서 정확성을 저하시킬 수 있다. 언급한 바와 같이, CLIP은 여전히 여러 데이터셋에서 EfficientNet보다 성능이 떨어진다. EfficientNet은 또한 CIFAR10 및 CIFAR100과 같은 저해상도 데이터셋에서도 CLIP보다 약간 더 나은 성능을 보인다. 이는 부분적으로 CLIP에 스케일 기반 데이터 증강이 부족하기 때문일 수 있다. EfficientNet은 또한 PatchCamelyon 및 CLEVRCounts와 같은 데이터셋에서도 약간 더 나은 성능을 보이는데 이들 데이터셋에서는 양쪽 접근법의 전체 성능이 여전히 낮다.
3.3 Robustness to Natural Distribution Shift
2015년, 딥러닝 모델이 ImageNet 테스트 세트에서 인간의 성능을 초과했다고 발표했다. 그러나 그 후 몇 년간의 연구는 이러한 모델들이 여전히 많은 단순한 실수를 저지르고 있다는 것을 반복적으로 발견했다. 또한, 이러한 시스템을 테스트하는 새로운 벤치마크들은 이들의 성능이 ImageNet 정확도와 인간의 정확도보다 훨씬 낮다는 것을 자주 발견했다. 이 차이를 설명하는 다양한 아이디어들이 제안되고 연구되었다. 제안된 설명의 공통 주제는 딥러닝 모델이 훈련 데이터셋에서 유지되는 상관관계와 패턴을 찾는 데 매우 능숙하다는 것이다. 그러나 이러한 상관관계와 패턴 중 많은 부분이 실제로는 일시적이며 다른 분포에서는 유지되지 않아 다른 데이터셋에서 성능이 크게 떨어지는 결과를 낳는다.
현재까지 대부분의 이러한 연구는 ImageNet에서 훈련된 모델로 평가를 제한하고 있다. 논의 주제로 돌아가서 이러한 초기 결과에서 너무 일반화하는 것은 실수일 수 있다. 이러한 실패가 딥러닝, ImageNet 또는 이 두 가지의 조합 중 어느 것에 기인하는지 어느 정도까지 알 수 있을까? 매우 큰 데이터셋에서 자연 언어 감독을 통해 훈련되고 높은 zero-shot 성능을 가진 CLIP 모델은 이 질문을 다른 각도에서 조사할 수 있는 기회를 제공한다.
ImageNet 모델의 이러한 행동을 정량화하고 이해하는 방향으로 나아가는 최근의 연구가 있다. 이는 ImageNet 모델의 성능이 자연 분포 변화에서 평가될 때 어떻게 변하는지 연구한다. 이들은 7개의 분포 변화 세트 ImageNetV2, ImageNet Sketch, Youtube-BB, ImageNet-Vid, ObjectNet, ImageNet Adversarial, ImageNet Rendition에서 성능을 측정한다. 이들은 다양한 출처에서 수집된 새로운 이미지로 구성된 이 데이터셋들을 기존 이미지를 다양한 방식으로 교란하여 만든 ImageNet-C, Stylized ImageNet 또는 적대적 공격과 같은 합성 분포 변화와 구별한다. 이들은 몇몇 기술이 합성 분포 변화에서 성능을 개선하는 것으로 입증되었지만 자연 분포에서는 일관된 개선을 가져오지 못하는 경우가 많기 때문에 이 구별을 제안한다.
이 수집된 데이터셋 전반에 걸쳐, ImageNet 모델의 정확도는 ImageNet 검증 세트에서 설정된 기대치보다 훨씬 떨어진다. 다음 요약 논의를 위해 모든 7개의 자연 분포 변화 데이터셋에 대한 평균 정확도와 ImageNet의 해당 클래스 하위 세트에 대한 평균 정확도를 보고한다. 추가적으로, 두 가지 다른 평가 설정을 가진 Youtube-BB와 ImageNet-Vid의 경우 pm-0과 pm-10 정확도의 평균을 사용한다.
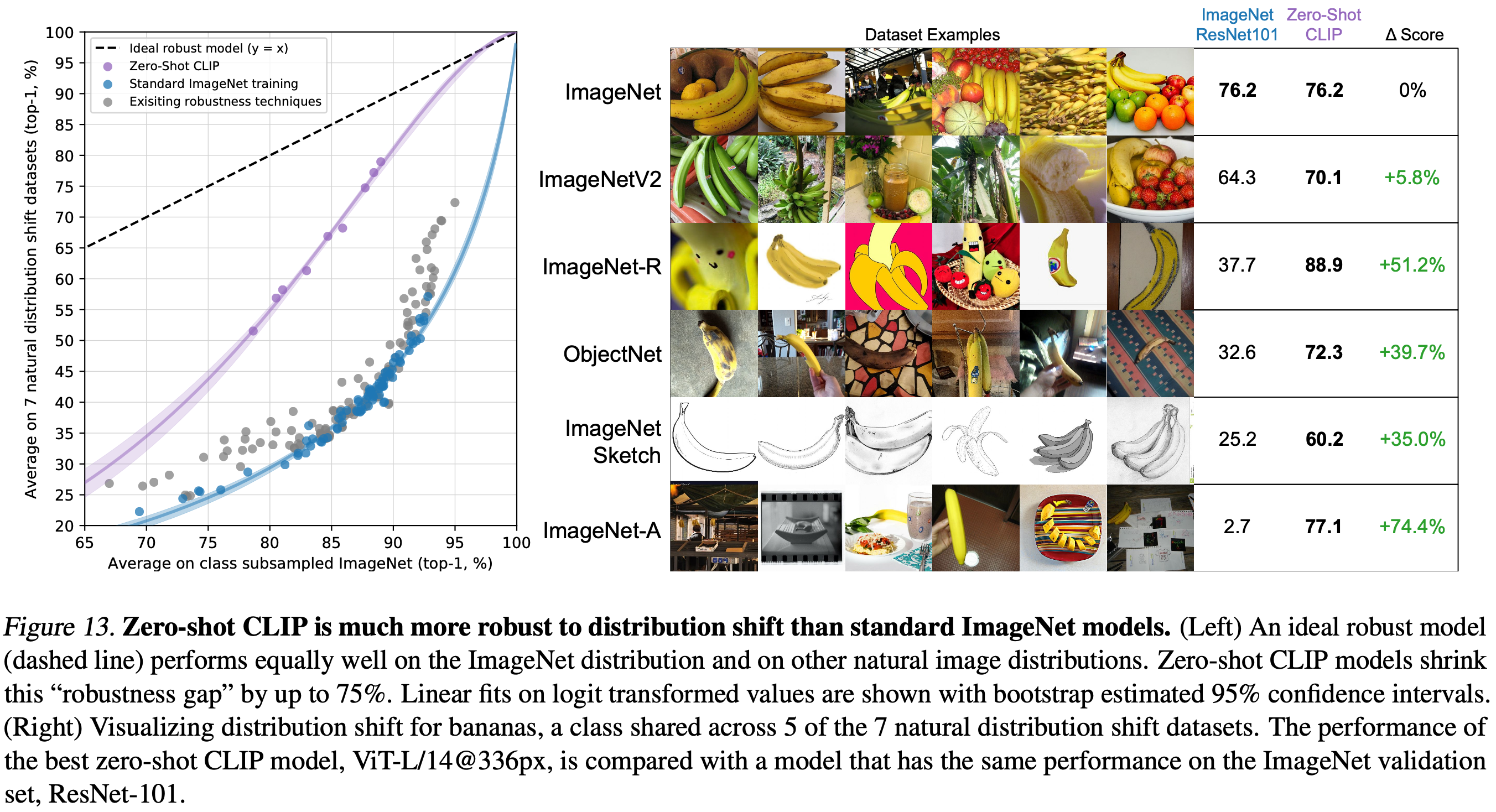
ResNet-101은 ImageNet 검증 세트와 비교할 때 이러한 자연 분포 변화에서 5배 더 많은 실수를 한다. 그러나 한 연구에서 분포 변화에서의 정확도가 ImageNet 정확도와 함께 예측 가능하게 증가하고 로그 변환된 정확도의 선형 함수로 잘 모델링된다는 것을 발견했다. 이 연구에서 연구도니 거의 모든 모델은 ImageNet 데이터셋에서 훈련되거나 미세 조정되었다. 이 섹션의 서론에서 논의된 바와 같이 ImageNet 데이터셋 분포에 대한 훈련 또는 적응이 관찰된 강건성 격차의 원인일까? 직관적으로, zero-shot 모델은 특정 분포에서만 유지되는 일시적인 상관관계나 패턴을 악용할 수 없을 것이다. 왜냐하면 그 분포에서 훈련되지 않았기 때문이다. 따라서 zero-shot 모델은 훨씬 더 높은 효과적인 강건성을 가질 것으로 기대된다. Figure 13에서는 zero-shot CLIP과 기존 ImageNet 모델의 자연 분포 변화에서의 성능을 비교한다. 모든 zero-shot CLIP 모델은 효과적인 강건성을 크게 개선하고 ImageNet 정확도와 분포 변화의 정확도 사이의 격차를 최대 75%까지 줄인다.
이러한 결과는 zero-shot 모델이 훨씬 더 강력할 수 있음을 보여주지만 이것이 반드시 ImageNet에서의 감독 학습이 강건성 격차를 초래한다는 것을 의미하지는 않는다. CLIP의 다른 세부 사항들, 예를 들어 크고 다양한 사전 훈련 데이터셋이나 자연어 감독의 사용은 그것이 zero-shot이든 fine-tuning이든 간에 훨씬 더 강력한 모델을 초래할 수 있다. 이 문제를 잠재적으로 좁히기 위한 초기 실험으로 CLIP 모델이 ImageNet 훈련 세트에서 CLIP 특징에 맞춘 L2 정규화 로지스틱 회귀 분류기를 통해 ImageNet 분포에 적응한 후 성능이 어떻게 변하는지 측정한다. Figure 14에서는 zero-shot 분류기에서 성능이 어떻게 변화하는지 시각화한다. CLIP을 ImageNet 분포에 적응시키면 IMageNet 정확도가 9.2% 증가하여 전체적으로 85.4%가 된다.
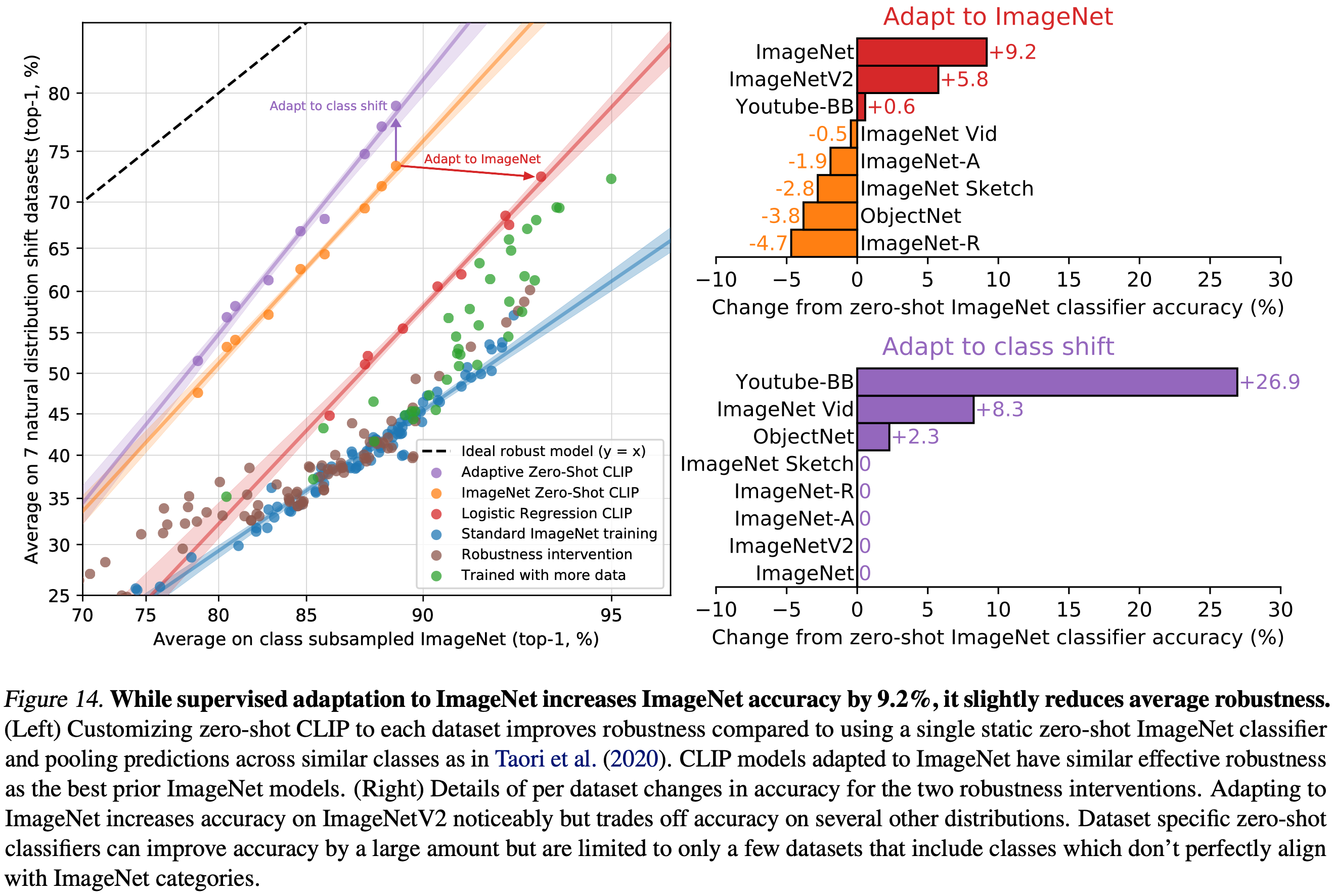
ImageNet 데이터셋에서 정확도가 9.2% 향상되었음에도 불구하고 이러한 향상이 분포 변화에서 평균 성능 향상으로 전환되지 않은 것은 놀라운 일이다. 또한, Figure 14에서 zero-shot 정확도와 선형 분류기 정확도 간의 차이를 데이터셋별로 나누어 분석하였고 ImageNetV2 데이터셋에서만 성능이 크게 향상되었다. ImageNetV2는 원래 ImageNet 데이터셋의 생성 과정을 긴밀하게 따랐기 때문에, 지도 학습 적응에서 얻은 정확도 향상이 ImageNet 분포에 밀접하게 집중되어 있음을 시사한다. 성능은 ImageNet-R에서 4.7%, ObjectNet에서 3.8%, ImageNet Sketch에서 2.8%, ImageNet-A에서 1.9% 감소했다. Youtube-BB와 ImageNet Vid 두 데이터셋에서의 정확도 변화는 미미하다.
ImageNet 데이터셋에서 정확도를 9.2% 향상시킬 수 있었음에도 불구하고 분포 변화에서 정확도가 거의 향상되지 않은 이유는 무엇일까? 이러한 이득이 주로 일시적 상관관계를 이용하는 것에서 비롯된 것일까? 이러한 행동은 CLIP, ImageNet 데이터셋, 연구된 분포 변화의 조합에만 특유한 것일까 아니면 더 일반적인 현상일까? 이는 선형 분류기뿐만 아니라 end-to-end finetuning에도 적용될까? 현재로서는 이러한 질문에 확신을 가진 답변을 가지고 있지 않다. 이전 연구에서도 ImageNet 이외의 분포에서 사전 훈련된 모델들이 있었지만, 일반적으로 이러한 모델들은 ImageNet에 finetuning된 후에 연구되고 공개된다. 사전 훈련된 zero-shot 모델이 finetuning된 모델보다 일관되게 더 높은 효과적 강건성을 가지고 있는지 이해하기 위한 단계로 이러한 질문에 대해 각 연구들의 모델에서 연구해 볼 것을 권장한다.
또한, 유연한 zero-shot 자연어 기반 이미지 분류기에 의해 가능해진 또 다른 강건성 개입을 조사한다. 7개 전달 데이터셋에 걸친 대상 클래스는 항상 ImageNet의 클래스와 완벽하게 일치하지 않는다. Youtube-BB와 ImageNet-Vid 두 데이터셋은 ImageNet의 상위 클래스로 구성되어 있다. 이는 ImageNet 모델의 고정된 1000-방향 분류기를 사용하여 예측을 시도할 때 문제가 발생한다. 한 연구는 ImageNet 클래스 계층에 따라 모든 하위 클래스에 대한 예측을 최대 풀링하여 이 문제를 처리한다. 때때로 이러한 매핑은 완벽하지 않는다. 예를 들어, Youtube-BB에서 '사람' 클래스의 예측은 베이스볼 플레이어, 신랑, 스쿠버 다이버와 같은 ImageNet 클래스를 통합하여 이루어진다. CLIP을 사용하면 각 데이터셋의 클래스 이름을 기반으로 맞춤형 zero-shot 분류기를 직접 생성할 수 있다. Figure 14에서 볼 수 있듯이, 이는 평균 효과적 강건성을 5% 향상시키지만 몇몇 데이터셋에서만 큰 개선이 집중되어 있다. 흥미롭게도, ObjectNet의 정확도도 2.3% 증가한다. 이 데이터셋은 ImageNet 클래스와 밀접하게 겹치도록 설계되었지만, ObjectNet의 창시자들이 제공한 각 클래스의 이름을 사용하는 것이 필요할 때 ImageNet 클래스 이름을 사용하고 예측을 풀링하는 것보다 여전히 약간 도움이 된다.
zero-shot CLIP은 효과적 강건성을 향상시키지만, Figure 14에서 보듯이 이점은 완전히 감독된 설정에서 거의 완전히 사라진다. 이 차이를 더 잘 이해하기 위해, zero-shot에서 완전 감독에 이르기까지 효과적 강건성이 어떻게 변하는지 조사한다. Figure 15에서는 최고의 CLIP 모델의 특징에 대한 0-shot, 1-shot, 2-shot, 4-shot, ..., 128-shot 및 완전 감독된 로지스틱 회귀 분류기의 성능을 시각화한다. few-shot 모델들도 기존 모델보다 더 높은 효과적 강건성을 보이지만, 이 이점은 훈련 데이터가 늘어나면서 내부 분포 성능이 증가함에 따라 점차 사라지며 완전 감독된 모델에서는 대부분 비록 전부는 아니지만 사라진다. 또한, zero-shot CLIP은 동등한 ImageNet 성능을 가진 few-shot 모델보다 눈에 띄게 더 강건하다.
실험을 통해, 모델이 접근할 수 있는 분포 특정 훈련 데이터의 양을 최소화함으로써 높은 효과적 강건성이 나타나는 것으로 보이지만, 이는 데이터셋 특정 성능을 감소시키는 비용을 수반한다.
이러한 결과를 종합하면, 대규모 작업 및 데이터셋 무관 사전 훈련으로의 최근 전환과 넓은 평가 suite에서의 zero-shot 및 few-shot 벤치마킹으로의 재지향은 더 강건한 시스템의 개발을 촉진하고 성능 평가를 더 정확하게 제공한다. GPT 계열과 같은 NLP 분야의 zero-shot 모델에서 동일한 결과가 유지되는지 궁금하다.
4. Comparison to Human Performance
CLIP은 인간의 성능과 학습을 어떻게 비교할까? CLIP과 유사한 평가 환경에서 인간이 얼마나 잘 수행하는지 더 잘 이해하기 위해, 한 가지 task에서 인간을 평가했다. 이러한 task에서 인간의 zero-shot 성능이 얼마나 강력한지 그리고 한 두 개의 이미지 샘플을 보여주었을 때 인간의 성능이 얼마나 향상되는지 알고 싶었다. 이는 인간과 CLIP에 대한 task 난이도를 비교하고 둘 사이의 상관관계와 차이점을 파악하는 데 도움이 될 수 있다.
Oxford IIT Pets 데이터셋의 테스트 분할에 있는 3,669개의 이미지 각각을 다섯 명의 다른 사람들이 보고 37개의 고양이 또는 개 품종 중 이미지와 가장 잘 일치하는 품종을 선택하도록 했다(완전히 확실하지 않은 경우 '모르겠다' 선택). zero-shot 경우에는 사람들에게 품종의 예시를 보여주지 않고 최선을 다해 표시하도록 요청했다. one-shot 실험에서는 사람들에게 각 품종의 샘플 이미지를 하나씩 제공했고, two-shot 실험에서는 두 개의 샘플 이미지를 제공했다.
인간 작업자들이 zero-shot task에서 충분히 동기 부여되지 않았다는 것이우려되었다. STL-10 데이터셋에서 94%의 높은 인간 정확도와 주의력 검사 이미지의 하위 집합에서 97-100%의 정확도는 인간 작업자에 대한 신뢰를 높였다.
흥미롭게도, 인간은 클래스당 하나의 훈련 예제로 평균 성능이 54%에서 76%로 향상되었고 추가 훈련 예제에서의 변동 이득은 미미했다. zero-shot에서 one-shot으로 가면서 정확도 향상은 거의 완전히 인간이 확신하지 못하는 이미지에서 발생했다. 이는 인간이 자신이 모르는 것을 알고 있다는 것을 시사하며 단일 예제를 기반으로 가장 불확실한 이미지에 대한 사전 판단을 업데이트할 수 있음을 보여준다. 이를 감안할 때, CLIP이 zero-shot 성능(Figure 5)에서 유망한 훈련 전략이며 자연 분포 변화 테스트(Figure 13)에서도 잘 수행하고 있음에도 불구하고 인간이 몇 가지 예제로부터 학습하는 방식과 이 논문의 few-shot 방법 사이에는 큰 차이가 있음을 알 수 있다.
이는 기계와 인간의 샘플 효율성 사이의 격차를 줄이기 위한 알고리즘 개선이 여전히 기다리고 있음을 시사한다. CLIP의 few-shot 평가가 사전 지식을 효과적으로 활용하지 못하고 인간은 그렇게 하기 때문에, few-shot 학습에 사전 지식을 적절히 통합하는 방법을 찾는 것이 CLIP에 대한 알고리즘 개선에서 중요한 단계라고 추측한다. 한 연구에 따르면 고품질 사전 훈련 모델의 특징 위에 선형 분류기를 사용하는 것이 few-shot 학습에서 거의 최고 수준에 근접한다. 이는 최고의 few-shot 머신러닝 방법과 인간읜 few-shot 학습 사이에 격차가 있음을 시사한다.
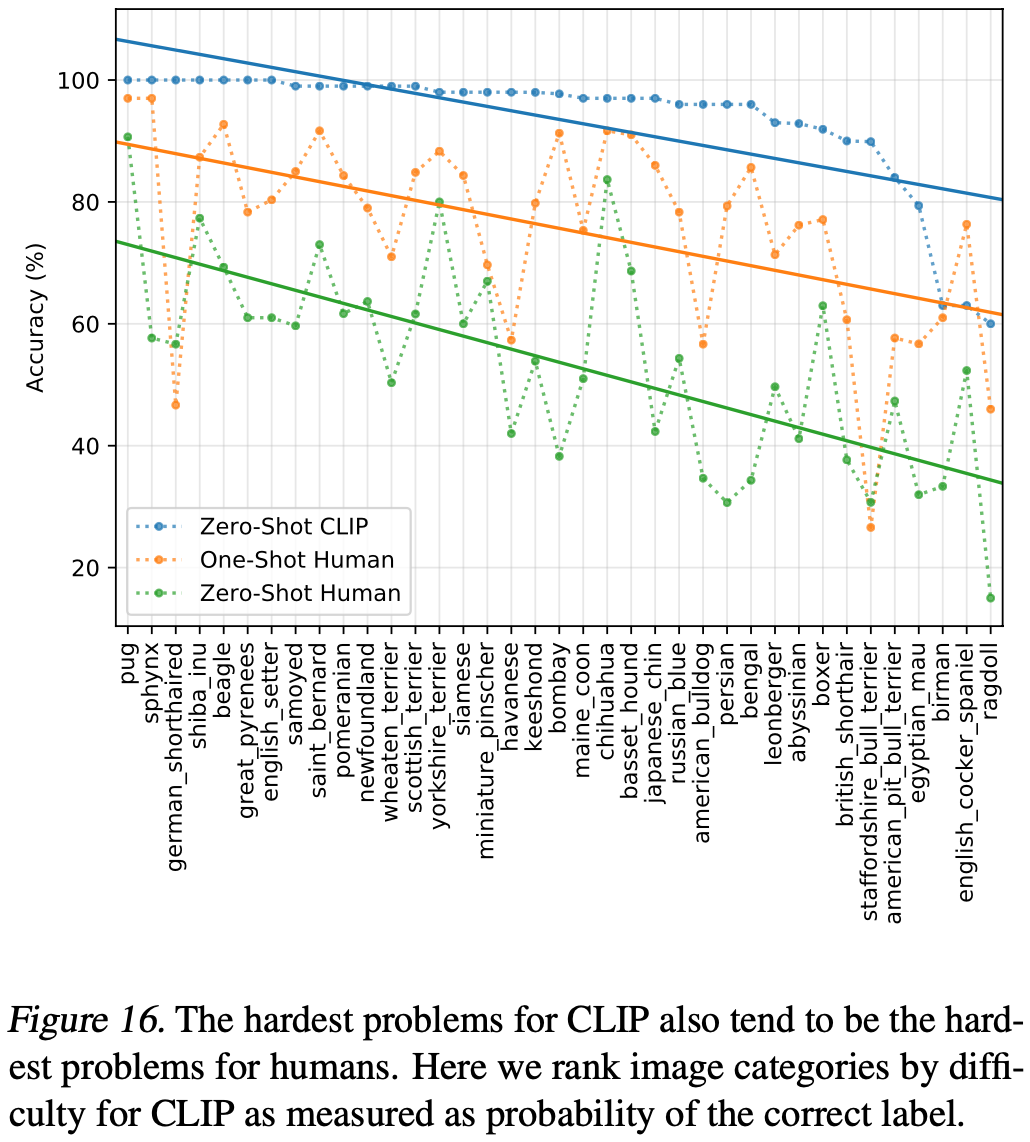
인간 정확도 대비 CLIP의 zero-shot 정확도를 나타내면(Figure 16), CLIP에게 가장 어려운 문제가 인간에게도 어렵다는 것을 알 수 있다. 오류가 일관되는 한도 내에서, 이는 데이터셋의 노이즈(잘못된 레이블 포함)와 분포 밖 이미지가 인간과 모델 모두에게 어렵기 때문일 수 있다는 가설이다.
5. Data Overlap Analysis
매우 큰 인터넷 데이터셋에서 사전 훈련을 할 때의 문제 중 하나는 의도치 않은 중복이 downstream 평가에 영향을 줄 수 있다는 것이다. 최악의 경우, 평가 데이터셋의 완전한 복사본이 사전 훈련 데이터셋에 유입되어 평가가 일반화 테스트로서의 의미를 잃을 수 있기 때문에 이를 조사하는 것이 중요하다. 이를 방지하는 한 가지 방법은 훈련 전에 모든 중복을 식별하고 제거하는 것이다. 이는 참된 보류 성능을 보장하지만, 모델이 평가될 수 있는 모든 데이터를 사전에 알아야 한다는 단점이 있다. 이는 벤치마킹과 분석의 범위를 제한할 수 있다. 새로운 평가를 추가하려면 비싼 재훈련을 요구하거나 중복으로 인한 정량화되지 않은 이점을 보고할 위험이 있다.
대신, 얼마나 많은 중복이 발생하고 이러한 중복이 성능에 어떤 영향을 미치는지를 문서화한다. 이를 위해 다음과 같은 절차를 사용했다.
1. 각 평가 데이터셋에 대해 중복 감지기를 실행하고(부록 C 참조), 발견된 가장 가까운 이웃을 수동으로 검사하여 데이터셋별로 정밀도를 유지하면서 재현율을 최대화하는 임계값을 설정한다. 이 임계값을 사용하여 중복을 포함하는 모든 예제가 포함된 Overlap 하위 집합과 이 임계값 아래에 있는 모든 예제를 포함하는 clean 하위 집합을 생성한다. 참조를 위해 변경되지 않은 전체 데이터셋을 All로 표시한다. 이로부터 데이터 오염의 정보를 Overlap의 예제 수와 All의 크기 비율로 기록한다.
2. 그런 다음 CLIP RN50x64의 세 분할에서 zero-shot 정확도를 계산하고 All - Clean을 주요 지표로 보고한다. 이는 오염으로 인한 정확도 차이이다. 양수일 경우 전체 보고된 데이터셋의 정확도가 중복 데이터에 과적합되어 부풀려졌다는 추정이다.
3. 중복의 양은 종종 작으므로 Clean의 정확도를 귀무 가설로 사용하고 Overlap 하위 집합에 대한 단측(큰 쪽) p-값을 계산하는 이항 유의성 검정도를 실행한다. 또한 Dirty에 대한 99.5% Clopper-Pearson 신뢰 구간도를 계산하여 추가 확인을 한다.
이 분석의 요약은 Figure 17에 제시되어 있다. 연구된 35개 데이터셋 중 9개는 전혀 중복이 감지되지 않았다. 이러한 데이터셋은 대부분 합성되었거나 특수한 용도로 사용되어 인터넷에 일반 이미지로 게시될 가능성이 낮다(예: MNIST, CLEVR, GTSRB). 또는 데이터셋이 생성된 날짜 이후의 새로운 데이터를 포함하고 있어 중복이 없을 것이 보장된다(ObjectNet 및 Hateful Memes). 이는 우리의 감지기가 낮은 위양성률을 가지고 있음을 보여준다. 중복의 중앙값은 2.2%이고 평균 중복은 3.2%이다. 이러한 작은 중복량 때문에 전체 정확도는 거의 0.1% 이상 변하지 않으며, 이 임계값 이상인 데이터셋은 7개 뿐이다. 이 중 통계적으로 유의미한 것은 보정 후 2개 뿐이다. 감지된 최대 개선은 Birdsnap에서 0.6%로, 두 번째로 큰 중복인 12.1%를 가진다. 가장 큰 중복은 Country211에서 21.5%로, 사전 훈련 데이터셋이 필터링된 YFCC100M의 부분을 포함하고 있기 때문이다. 그럼에도 불구하고 이러한 큰 중복에도 Country211에서의 정확도 증가는 0.2%에 불과하다. 이는 훈련 텍스트가 하류 평가가 측정하는 구체적인 task와 관련이 없는 경우가 많기 때문일 수 있다. Country211은 지리적 위치 파악 능력을 측정하지만, 이 중복된 학습 텍스트를 조사해 보면 종종 이미지의 위치를 언급하지 않는 것을 볼 수 있다.
6. Limitations
CLIP에는 아직 많은 한계가 있다. 이러한 여러 가지는 다양한 섹션에서 분석의 일부로 논의되었지만, 여기에서 요약하고 수집한다.
훈련 분할이 있는 데이터셋에서 zero-shot CLIP의 성능은 평균적으로 ResNet-50 특징 위에 선형 분류기를 사용하는 간단한 감독 기준과 경쟁력이 있다. 이러한 데이터셋 대부분에서 이 기준의 성능은 현재 최고 수준보다 훨씬 낮다. CLIP의 task 학습 및 전이 능력을 향상시키기 위해서는 여전히 상당한 작업이 필요하다. 지금까지 성능을 꾸준히 향상시켜 왔던 확장은 지속적인 개선을 위한 방향을 제시하지만, zero-shot CLIP이 전체적인 최고 수준의 성능에 도달하기 위해서는 약 1000배의 계산 증가가 필요하다고 추정한다. 이는 현재 하드웨어로는 실행 불가능하다. CLIP의 계산 및 데이터 효율성을 향상시키기 위한 추가 연구가 필요하다.
섹션 3.1에서 수행된 분석은 CLIP의 zero-shot 성능이 여러 종류의 task에서 여전히 상당히 약하다는 것을 발견했다. task별 모델과 비교했을 때, CLIP의 성능은 자동차 모델, 꽃 종류, 항공기 변형 등과 같은 세밀한 분류에서 떨어진다. 또한, 이미지에서 객체 수를 세는 것과 같은 더 추상적이고 체계적인 작업에서도 어려움을 겪는다. 사진 속 가장 가까운 차와의 거리를 분류하는 것과 같이 CLIP의 사전 훈련 데이터셋에 포함될 가능성이 낮은 새로운 task의 경우, CLIP의 성능은 거의 무작위 수준일 수 있다. 아직 많은 task에서 CLIP의 zero-shot 성능이 우연에 가까운 수준이라고 확신한다.
zero-shot CLIP은 섹션 3.3에서 조사된 바와 같이 많은 자연 이미지 분포에 잘 일반화되지만, 정말로 분포 밖의 데이터에 대해서는 여전히 일반화가 잘 되지 않는다. 예를 들어, 부록 E에서 보고된 OCR task에서 문제가 발생한다. CLIP은 디지털로 렌더링된 텍스트에서 잘 수행되는 고품질의 의미적 OCR 표현을 학습한다. 그러나 CLIP은 MNIST의 수기 숫자에서 88%의 정확도만 달성한다. 픽셀에 대한 로지스틱 회귀의 단순한 기준은 zero-shot CLIP보다 성능이 뛰어나다. 의미적 및 거의 주옥된 가장 가까운 이웃 검색은 사전 훈련 데이터셋에 MNIST 숫자와 유사한 이미지가 거의 없음을 확인시켜준다. 이는 CLIP이 딥러닝 모델의 취약한 일반화 문제를 해결하는 데 거의 도움이 되지 않음을 시사한다. 대신 CLIP은 매우 크고 다양한 데이터셋에서 훈련함으로써 모든 데이터가 효과적으로 분포 내에 있기를 바라며 문제를 우회하려고 한다. 이는 MNIST가 보여주듯이 쉽게 위반될 수 있는 순진한 가정이다.
CLIP은 다양한 task와 데이터셋에 대한 zero-shot 분류기를 유연하게 생성할 수 있지만, 주어진 zero-shot 분류기에서 선택할 수 있는 개념에만 한정된다. 이미지 캡셔닝과 같이 새로운 출력을 생성할 수 있는 진정으로 유연한 접근법에 비해 상당한 제한이 있다. 불행히도, 2.3절에서 설명한 바와 같이, 본 연구에서 시도한 이미지 캡션 기준의 계산 효율성은 CLIP보다 훨씬 낮다. 시도해 볼 가지착 있는 간단한 아이디어는 대조적 및 생성적 목표를 함께 훈련하여 CLIP의 효율성과 캡션 모델의 유연성을 결합하는 것이다. 또 다른 대안으로, 주어진 이미지에 대한 많은 자연어 설명을 추론 시간에 검색하는 것과 유사한 접근법을 시행할 수 있다.
CLIP은 딥 러닝의 낮은 데이터 효율성 문제를 해결하지 않는다. 대신, CLIP은 수백만 개의 훈련 예제로 확장 가능한 감독 소스를 사용하여 이를 보완한다. CLIP 모델 훈련 중에 각 이미지를 초당 하나씩 제시한다면, 32개 훈련 epoch 동안 본 128억 개의 이미지를 반복하는 데 405년이 걸릴 것이다. 자기 감독 및 자기 훈련 방법과 CLIP을 결합하는 것은 표준 감독 학습보다 데이터 효율성을 향상시킬 수 있는 입증된 능력을 감안할 때 유망한 방향이다.
본 연구의 방법론은 여러 중대한 한계를 가지고 있다. zero-shot 전이에 중점을 두고 있음에도 불구하고 CLIP의 개발을 안내하기 위해 전체 검증 세트의 성능을 반복적으로 쿼리했다. 이러한 검증 세트는 종종 수천 개의 예제를 포함하고 있으며 이는 진정한 zero-shot 시나리오에는 비현실적이다. 이와 유사한 우려가 준지도 학습 분야에서도 제기되었다. 또 다른 잠재적 문제는 평가 데이터셋 선택이다. 본 연구는 Kornblith 연구의 12개 데이터셋 평가 suite의 결과를 표준화된 컬렉션으로 보고했지만, 주요 결과는 CLIP의 개발 및 능력과 명백하게 공진화도니 27개 데이터셋 컬렉션을 다소 무계획적으로 조합하여 사용했다. 넓은 zero-shot 전이 능력을 명시적으로 평가하도록 설계된 새로운 벤치마크 task를 만드는 것이 이러한 문제를 해결하는 데 도움이 될 것이다.
CLIP은 인터넷에서 이미지와 텍스트가 짝을 이룬 상태로 훈련된다. 이러한 이미지-텍스트 쌍은 필터링되지 않고 큐레이션되지 않아 CLIP 모델이 많은 사회적 편견을 학습하게 한다. 이는 이전 연구에서의 이미지 캡션 모델에서 입증되었다. 이러한 행동에 대한 자세한 분석과 정량화 및 잠재적 완화 전략 논의는 섹션 7에서 참조하면 된다.
이 연구에 전반에 걸쳐 강조했듯이, 자연어를 통해 이미지 분류기를 지정하는 것은 유연하고 일반적인 인터페이스이지만 그 자체의 한계가 있다. 많은 복잡한 task와 시각적 개념은 텍스트만으로 명시하기 어려울 수 있다. 실제 훈련 예제는 분명히 유용하지만 CLIP은 직접적으로 few-shot 성능을 최적화하지 않는다. 본 연구에서는 CLIP의 특징 위에 선형 분류기를 적합시키는 방식으로 회귀한다. 이로 인해 zero-shot에서 few-shot 설정으로 전환할 때 직관적으로 이해되지 않는 성능 저하가 발생한다. 섹션 4에서 논의한 바와 같이, 이는 zero에서 one-shot 설정으로 크게 향상되는 인간의 성능과 뚜렷하게 다르다. 향후 연구에서는 CLIP의 강력한 zero-shot 성능과 효율적인 few-shot 학습을 결합하는 방법을 개발할 필요가 있다.
7. Broader Impacts
CLIP은 임의의 이미지 분류 작업을 수행할 수 있는 능력 덕분에 다양한 기능을 가지고 있다. 예를 들어, 고양이와 개의 이미지를 제공하고 고양이를 분류하도록 요청하거나 백화점에서 찍은 이미지를 제공하고 소매치기를 분류하도록 요청할 수 있다. 이는 상당한 사회적 함의를 가지며 AI가 부적합할 수 있는 작업이다. 어떤 이미지 분류 시스템과 마찬가지로 CLIP의 성능과 목적에 맞는 적합성은 평가되어야 하며 그 폭넓은 영향은 맥락에서 분석되어야 한다. CLIP은 또한 이러한 문제를 확대하고 변경할 수 있는 기능을 도입한다. CLIP은 재훈련할 필요 없이 자신만의 분류를 쉽게 만들 수 있는 기능을 제공한다. 이 기능은 GPT-3와 같은 대규모 생성 모델에서 발견된 문제와 유사한 도전을 제기한다. 중요하지 않은 zero-shot(또는 few-shot) 일반화를 보이는 모델은 매우 다양한 기능을 가질 수 있으며, 그 중 많은 부분은 테스트를 거친 후에만 명확해진다.
CLIP을 zero-shot 설정에서 연구한 결과, 모델은 이미지 검색 또는 검색과 같은 광범위하게 적용 가능한 task에 상당한 가능성을 보여준다. 예를 들어, 텍스트가 주어진 데이터베이스에서 관련 이미지를 찾거나 이미지가 주어진 관련 텍스트를 찾을 수 있다. 또한, 추가 데이터나 훈련 없이도 CLIP을 맞춤형 애플리케이션으로 쉽게 조정할 수 있는 상대적인 용이성은 오늘날 우리가 상상하기 어려운 다양한 새로운 애플리케이션을 잠금 해제할 수 있다. 이는 지난 몇 년 동안 대규모 언어 모델에서 발생한 일이다.
이 논문의 앞선 부분에서 연구한 30개 이상의 데이터셋 외에도, FairFace 벤치마크에서 CLIP의 성능을 평가하고 탐색적 편향 프로브를 수행한다. 그런 다음 모델의 성능을 하류 작업, 감시에서 특성화하고 다른 사용 가능한 시스템과 비교하여 그 유용성을 논의한다. CLIP의 많은 기능은 다목적으로 사용될 수 있다(예: OCR은 스캔된 문서를 검색 가능하게 하거나, 화면 읽기 기술을 지원하거나, 번호판을 읽는 데 사용할 수 있다). 조치 인식, 객체 분류 및 지리적 위치 파악부터 안면 감정 인식에 이르기까지 측정된 여러 기능은 감시에 사용될 수 있다. 그 사회적 함의를 감안할 때, 우리는 감시 사용 분야를 특별히 다룬다.
또한 모델에 내재된 사회적 편견을 특성화하려고 시도했다. 편견 테스트는 모델이 다양한 시나리오에서 어떻게 반응하는지 조사하는 본 연구의 초기 노력을 대표하며 본질적으로 범위가 제한적이다. CLIP과 같은 모델은 구체적인 배치와 관련하여 분석되어야 하며 편견이 어떻게 나타나는지를 이해하고 잠재적 개입을 식별해야 한다. AI 개발자가 범용 컴퓨터 비전 모델에서 편견을 더 잘 특성화할 수 있도록 더 넓고 더 맥락적이며 더 강력한 테스트 체계를 개발하기 위해 추가적인 커뮤니티 탐구가 필요할 것이다.
7.1 Bias
알고리즘 결정, 훈련 데이터 및 클래스를 정의하고 분류하는 방법은 AI 시스템 사용으로 인해 발생하는 사회적 편견과 불평등을 초래하고 증폭시킬 수 있다. 클래스 설계는 개발자가 클래스를 정의할 수 있고 모델이 어떤 결과를 제공할 수 있는 CLIP 같은 모델에 특히 관련이 있다.
이 섹션에서는 편향 프로브를 사용하여 CLIP의 일부 편향에 대한 예비 분석을 제공한다. 또한 모델에서 특정 편향 사례를 찾기 위한 탐색적 편향 연구를 수행한다.
초기 편향 프로브로서 FairFace 데이터셋에서 zero-shot CLIP의 성능을 분석한 다음, 추가적인 편향과 편향의 원인을 찾기 위해 모델을 더 조사한다.
FairFace 데이터셋에서 두 버전의 CLIP으로 zero-shot CLIP 모델("ZS CLIP")과 FairFace의 데이터셋 위에 CLIP의 특징을 기반으로 한 로지스틱 회귀 분류기("LR CLIP")로 평가했다. LR CLIP은 FairFace의 자체 모델보다 대부분의 분류 테스트에서 더 높은 정확도를 보였으며 ResNet-101 32x48d Instagram 모델보다도 높다. ZS CLIP의 성능은 카테고리에 따라 다르며 몇몇 카테고리에서는 FairFace의 모델보다 나쁘고 다른 카테고리에서는 더 좋다(Table 3 및 Table 4 참고).
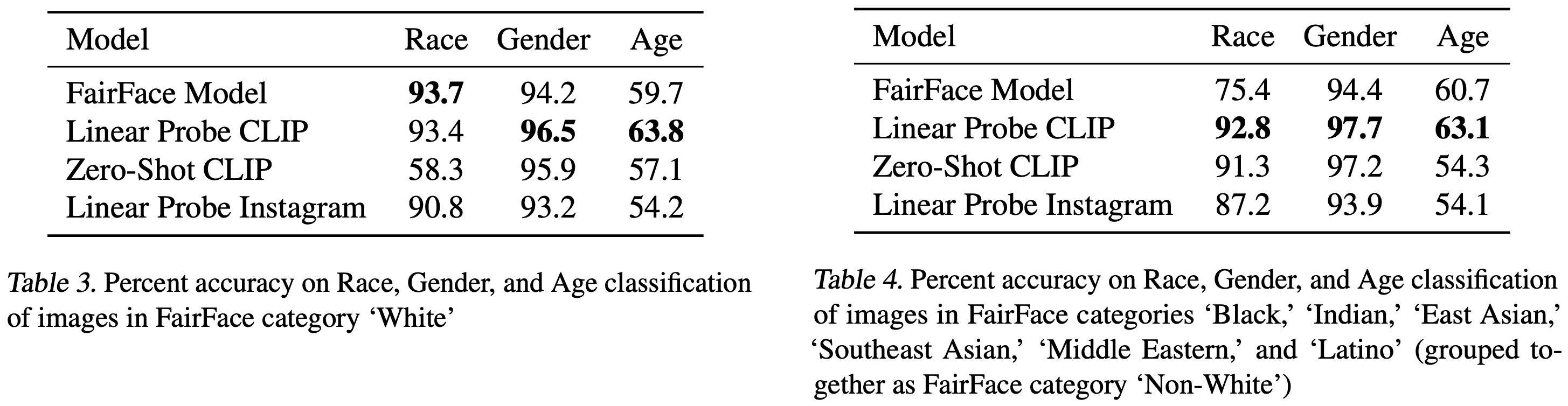
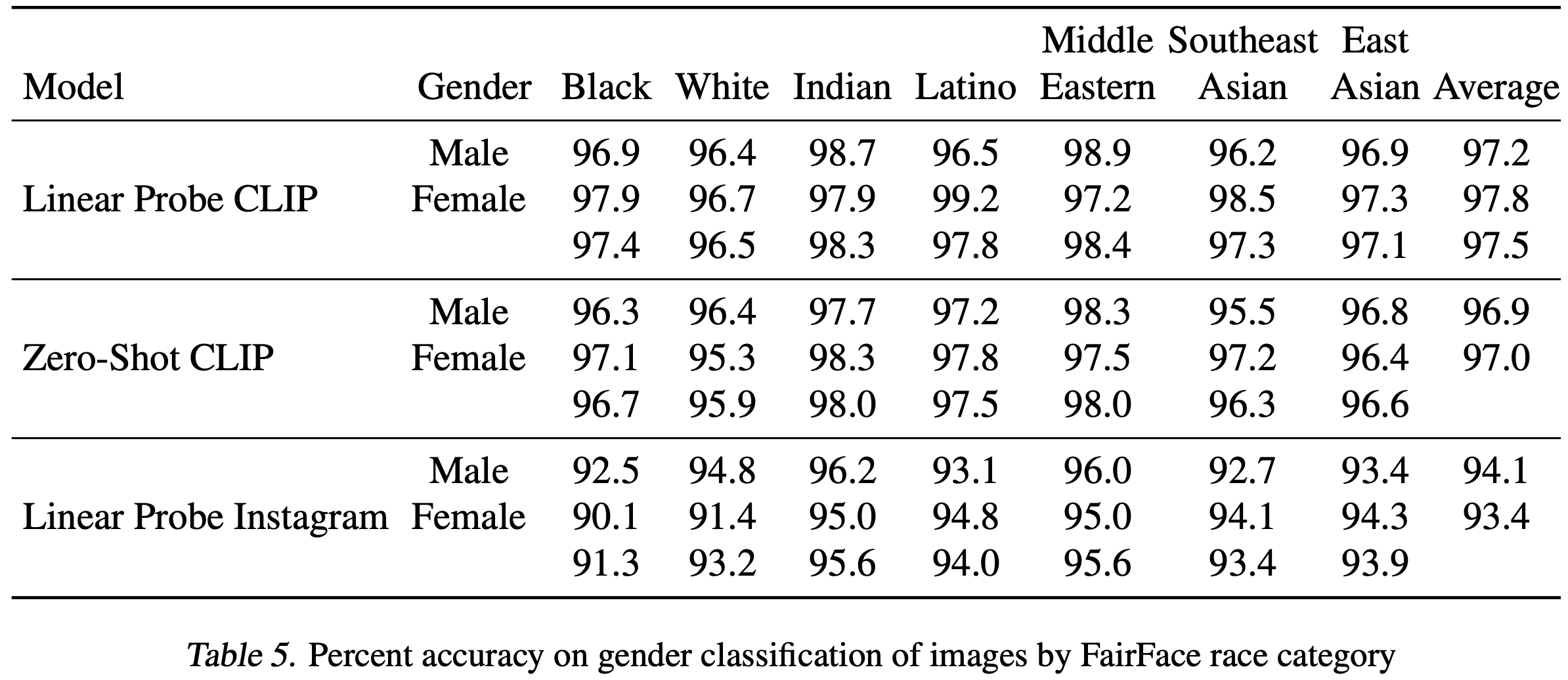
또한, FairFace 데이터셋에서 정의된 인종 및 성별 교차 카테고리를 기준으로 LR CLIP과 ZS CLIP 모델의 성능을 테스트했다. 모델이 성별 분류에서 모든 인종 카테고리에 대해 95% 이상의 성능을 보인다는 것을 발견했다. 이 결과는 Table 5에 요약되어 있다.
LR CLIP은 FairFace 벤치마크 데이터셋에서 성별, 인종 및 연령 분류에 대해 Linear Probe Instagram 모델보다 더 높은 정확도를 달성하지만, 벤치마크의 정확도는 알고리즘 공정성의 한 가지 근사치일 뿐이며, 실제 세계 맥락에서 공정성을 의미 있는 척도로서 자주 실패한다. 모델이 더 높은 정확도와 서브 그룹 간 성능 격차가 적어도 이것이 영향 격차가 적다는 것을 의미하지는 않는다. 예를 들어, 대표성이 낮은 그룹에서의 높은 성능은 회사가 안면 인식 사용을 정당화하고 인구 집단에 불균형하게 영향을 미치는 방식으로 배치하는 데 사용될 수 있다. 평향을 탐지하기 위해 안면 분류 벤치마크를 사용했지만, 이것이 안면 분류가 문제가 없는 작업이라고 암시하거나 배포된 맥락에서 인종, 연령 또는 성별 분류 사용을 지지하는 것은 아니다.
또한 대표성 해를 일으킬 가능성이 높은 분류 용어를 사용하여 모델을 조사하고 특히 비하 해를 중점적으로 다루었다. ZS CLIP 모델이 FairFace 데이터셋의 10,000개 이미지를 분류해야 하는 실험을 수행했다. FairFace 클래스 외에도 다음 클래스를 추가했다. '동물', '고릴라', '침팬지', '오랑우탄', '도둑', '범죄자' 및 '수상한 사람'. 이 실험의 목적은 비하 해가 특정 인구 하위 그룹에 불균형하게 영향을 미치는지 확인하는 것이었다.
이미지의 4.9%가 본 연구 조사에서 사용한 비인간 클래스('동물', '침팬지', '고릴라', '오랑우탄') 중 하나로 잘못 분류되었다는 것을 발견했다(신뢰 구간은 4.6%에서 5.4% 사이). 그 중 '흑인' 이미지는 가장 높은 오분류율(약 14%; 신뢰 구간은 [12.6%에서 16.4%])을 보였으며 다른 인종은 8% 미만의 오분류율을 보였다. 0-20세 연령대는 이 카테고리에 분류될 가능성이 14%로 가장 높았다.
또한 남성의 16.5%가 범죄 관련 클래스('도둑', '수상한 사람' 및 '범죄자')로 잘못 분류되었다는 것을 발견했으며 여성 이미지는 9.8%였다. 흥미롭게도, 0-20세 연령대의 사람들은 다른 연령대의 사람들(20-60세 약 12% 및 70세 이상 0%)에 비해 범죄 관련 클래스에 속할 가능성이 더 높았다(약 18%). 범죄 관련 용어에 대한 인종 간 분류에서 상당한 격차를 발견했으며, 이는 Table 6에 기록되었다.

20세 미만의 사람들이 범죄 관련 및 비인간 동물 카테고리에 가장 많이 분류되는 것을 관찰했기 때문에 동일한 클래스에 '아동' 카테고리를 추가하여 이미지 분류를 수행했다. 여기서의 목표는 이 카테고리가 모델의 행동을 현저하게 변화시키고 연령별로 비하 해가 어떻게 분배되는지를 보는 것이었다. 이것이 범죄 관련 카테고리나 비인간 동물 카테고리에 분류된 20세 미만 사람들의 이미지 수를 크게 줄였다는 것을 발견했다(Table 7 참조). 이는 클래스 설계가 모델 성능과 원치 않는 편향이나 행동을 결정하는 주요 요인이 될 수 있음을 보여주며 동시에 얼굴 이미지를 사용하여 사람들을 이러한 방식으로 자동 분류하는 것의 사용에 대해 광범위한 질문을 제기한다.
이러한 프로브의 결과는 포함하기로 선택한 클래스 카테고리뿐만 아니라 각 클래스를 설명하는 데 사용하는 구체적인 언어에 따라 달라질 수 있다. 부실한 클래스 설계는 현실 세계의 성능 저하로 이어질 수 있으며 개발자가 자신의 클래스를 쉽게 설계할 수 있는 모델인 CLIP에서 특히 중요한 문제이다.
또한 CLIP이 남성과 여성의 이미지를 어떻게 다르게 처리하는지를 테스트했다. 이 실험의 일환으로 레이블 임계값을 결정하는 등의 특정 추가 설계 결정이 CLIP에서 출력하는 레이블에 어떤 영향을 미치고 편향이 어떻게 나타나는지를 연구했다.
세 가지 실험을 수행했다. - 성별 분류의 정확도를 테스트했고 두 가지 다른 레이블 세트에 대해 레이블이 어떻게 다르게 분배되는지를 테스트했다. 첫 번째 레이블 세트로는 300개의 직업 레이블을 사용했고 두 번째 레이블 세트로는 Google Cloud Vision, Amazon Rekognition 및 Microsoft Azure Computer Vision이 모든 이미지에 대해 반환한 레이블의 조합을 사용했다.
먼저 국회의원 이미지의 성별 예측 성능을 살펴보기 위해 모델을 테스트했다. 목표는 모델이 공식적인 설정/권력의 위치에 있는 사람의 이미지를 제공받았을 때 남성을 남성으로, 여성을 여성으로 올바르게 인식하는지를 확인하는 것이었다. 모델이 이미지에서 100%의 정확도를 달성했다는 것을 발견했다. 이는 FairFace 데이터셋에서의 모델 성능보다 약간 더 좋은 성능이다. 이것의 이유 중 하나는 국회의원 데이터셋의 모든 이미지가 고품질이고 명확하며 사람들이 FairFace 데이터셋과 달리 분명하게 중앙에 위치해 있기 때문일 것으로 추측한다.
레이블 확률에 대한 임계값을 설정하여 어떻게 편향이 있는 레이블 반환에 영향을 미치는지를 연구하기 위해, 0.5% 및 4.0%에서 임계값을 설정하는 실험을 수행했다. 낮은 임계값이 레이블 품질을 낮추는 것으로 나타났다. 그러나 이 임계값 하에서의 레이블 분포 차이는 여전히 편향 신호를 포함할 수 있다. 예를 들어, 0.5% 임계값 하에서 '보모' 및 '가정부'와 같은 레이블이 여성에게서 나타나기 시작하는 반면, '죄수' 및 '조폭'과 같은 레이블은 남성에게 나타나기 시작한다는 것을 발견했다. 이는 직업에 대한 성별 연관성을 나타내며 이전에 발견된 것과 유사하다.
4%의 더 높은 임계값에서는 '입법자' , '의원' 및 '국회의원'과 같은 레이블이 두 성별에서 가장 높은 확률로 포함된다. 그러나 이러한 편향은 낮은 확률 레이블에서도 나타나며 이러한 시스템을 배포할 때 충분히 안전한 행동이 어떤 모습일지에 대한 더 큰 질문을 제기한다.
Google Cloud Vision(GCV), Amazon Rekognition 및 Microsoft가 모든 이미지에 대해 반환한 조합된 레이블 세트를 사용했을 때, GCV 시스템에서 발견한 편향과 유사하게 본 시스템도 여성에게 일반적으로 머리카락과 외모에 관련된 레이블을 남성보다 더 많이 부착하는 경향이 있음을 발견했다. 예를 들어, '갈색 머리', '금발', '블론드'와 같은 레이블은 여성에게 상당히 더 자주 나타났다. 또한, CLIP은 '임원' 및 '의사'와 같이 고위 직업을 설명하는 레이블을 남성에게 불균형적으로 더 자주 부착했다. 여성에게 더 자주 부착된 유일한 네 가지 중 세 가지는 '뉴스캐스터', '텔레비전 진행자' 및 '뉴스리더'였으며 네 번째는 '판사'였다. 이는 GCV에서 발견된 편향과 유사하며 역사적인 성별 차이를 나타낸다.
흥미롭게도, 이 레이블 세트에 대해 임계값을 0.5%로 낮췄을 때, 남성을 묘사하는 레이블도 '정장', '넥타이'와 같은 외모 관련 단어로 변경되었다(Figure 18). '군인' 및 '임원'과 같은 많은 직업 관련 단어들이 4%의 더 높은 임계값에서 여성의 이미지를 설명하는 데 사용되지 않았지만, 낮은 0.5% 임계값에서는 남성과 여성 모두에게 사용되었으며 이것이 남성에 대한 레이블 변경의 원인이 될 수 있다. 반대의 경우는 해당되지 않는다. 여성을 설명하는 데 사용된 서술적 단어는 여전히 남성에게 드물게 사용된다.
모델을 구축하는 모든 단계에서의 설계 결정은 편향이 어떻게 나타나는지에 영향을 미치며 이는 특히 CLIP에서 제공하는 유연성을 감안할 때 특히 그렇다. 훈련 데이터 및 모델 아키텍처에 대한 선택 외에도 클래스 설계와 임계값 설정과 같은 결정은 모델이 출력하는 레이블을 변경할 수 있으며 특정 종류의 해를 높이거나 낮출 수 있다. 모델 및 AI 시스템을 설계하고 개발하는 사람들은 상당한 권력을 가지고 있다. 클래스 설계와 같은 결정은 모델 성능뿐만 아니라 모델 편향이 어떻게 그리고 어떤 맥락에서 나타나는지를 결정하는 주요 요소이다.
이 실험들은 종합적이지 않다. 그것들은 클래스 설계 및 기타 편향 원인으로부터 발생할 수 있는 잠재적 문제를 설명하고 탐구를 촉발하기 위해 의도되었다.
7.2 Surveillance
다음으로, 사회적으로 민감한 하류 작업과 관련된 모델 성능을 특성화하고자 했다. 우리의 분석은 위에서 설명한 특성화 접근 방식을 더 잘 구현하고, 점점 더 일반적인 컴퓨터 비전 모델의 잠재적 미래 영향에 대해 연구 커뮤니티를 오리엔테이션하며 이러한 시스템을 둘러싼 규범과 점검의 발전을 돕기 위한 것이다. 감시를 포함한 것은 이 분야에 대한 열정을 나타내려는 것이 아니라 감시가 사회적 함의를 감안할 때 예측을 시도해야 할 중요한 영역이라고 생각하기 때문이다.
CCTV 카메라에서 캡처된 이미지와 zero-shot 유명 인사 식별에 대한 모델의 성능을 측정했다. 먼저 감시 카메라에서 캡처된 저해상도 이미지에서 모델 성능을 테스트했다. VIRAT 데이터셋과 한 연구에서 캡처한 데이터를 사용했으며 두 데이터 모두 비배우들이 있는 실외 장면으로 구성되어 있다.
CLIP의 유연한 클래스 구성을 고려하여, 12개의 다른 비디오 시퀀스에서 캡처된 515개의 감시 이미지를 일반 클래스에 대한 거칠고 세밀한 분류를 위해 자체 구성하여 테스트했다. 거친 분류는 모델이 이미지의 주요 주제를 올바르게 식별해야 했다(즉, 이미지가 빈 주차장, 학교 캠퍼스 등의 사진인지 결정). 세밀한 분류의 경우, 모델은 이미지에 작은 특징이 있는지 없는지를 식별할 수 있는지를 결정하기 위해 구성된 두 가지 옵션 중에서 선택해야 했다(예: 구석에 서 있는 사람).
거친 분류의 경우, 이미지의 내용을 설명하기 위해 수동으로 이미지에 캡션을 달았으며 모델이 선택할 수 있는 옵션은 항상 6개 이상이었다. 또한, '근접' 답변(예: '흰색 차가 있는 주자창' 대 '빨간 차가 있는 주차장')을 포함한 클래스 세트가 포함된 '스트레스 테스트'를 수행했다. 모델이 CCTV 이미지에 대한 초기 평가에서 91.8%의 최고 정확도를 달성했다는 것을 발견했다. 두 번째 평가에서 정확도는 크게 떨어져 51.1%가 되었으며 모델은 40.7%의 경우 '근접' 답변을 잘못 선택했다.
세밀한 감지의 경우, zero-shot 모델은 결과가 거의 무작위 수준으로 나쁘게 수행되었다. 이 실험은 이미지 시퀀스에서 작은 물체의 존재 또는 부재를 감지하는 것만을 대상으로 했다.
또한 CelebA 데이터셋을 사용하여 CLIP의 야생에서의 zero-shot 신원 감지 성능을 테스트했다. 이는 모델이 사전 훈련된 공개 데이터만을 사용하여 신원 감지 성능을 평가하기 위한 것이다. 인터넷상에 많은 이미지가 있는 유명인 데이터셋에서 이를 테스트했지만, 모델이 얼굴을 이름과 연결하는 데 필요한 사전 훈련 데이터의 이미지 수가 모델이 더 강력해짐에 따라 계속 감소할 것이라는 가설을 세웠다(Table 8 참조). 이는 사회적 함의가 큰 것으로 자연어 처리에서 최근 발전된 사례와 유사하다. 여기서 인터넷 데이터에 기반한 최신 대규모 언어 모델은 비교적 덜 알려진 공인들에 관한 정보를 놀랍도록 제공하는 능력을 종종 보여준다.
모델이 100가지 가능한 클래스 중 '야생에서의' 8k 유명인 이미지에 대해 59.2%의 최고 정확도를 보였다는 것을 발견했다. 그러나 클래스 크기를 1k 유명인 이름으로 늘렸을 때 이 성능은 43.3%로 떨어졌다. 이 성능은 Google의 Celebrity Recognition과 같은 생산 수준 모델과 비교할 때 경쟁력이 없다. 그러나 이 결과가 주목할 만한 이유는 이 분석이 사전 훈련 데이터에서 추론된 이름을 기반으로 한 zero-shot 식별 기능만을 사용하여 이루어졌기 때문이다. 본 연구는 추가적인 과제 특화 데이터셋을 사용하지 않았으며 (상대적으로) 강력한 결과는 다중모드 모델을 배포하기 전에 사람들이 주어진 맥락과 도메인에서의 행동을 신중하게 연구할 필요가 있음을 더욱 시사한다.
CLIP은 zero-shot 기능을 감안할 때 상대적으로 데이터가 적은 작업에 상당한 이점을 제공한다. 그러나 많은 수요가 있는 감시 작업에 대해 큰 데이터셋과 고성능 감독 모델이 존재한다. 결과적으로, CLIP의 이러한 용도에 대해 비교적 매력은 낮다. 또한, CLIP은 객체 감지 및 의미적 분할과 같은 일반적인 감시 관련 작업에 대해 설계되지 않았다. 이는 이러한 용도를 염두에 둔 모델이 널리 사용 가능할 때 특정 감시 작업에 대한 사용이 제한적임을 의미한다.
그러나 CLIP은 훈련 데이터의 필요성을 제거함으로써 일정 수준의 사용성을 제공한다. 따라서 CLIP과 유사한 모델은 잘 맞춤화된 모델이나 데이터셋이 없는 맞춤형, 틈새 감시 사용 사례를 가능하게 할 수 있으며 이러한 애플리케이션을 구축하는 데 필요한 기술 요구 사항을 낮출 수 있다. 실험에서 보여주듯이, ZS CLIP은 오늘날 몇 가지 감시 관련 작업에서 비범한 성능을 보이지만, 예외적인 성능은 아니다.
7.3 Future Work
이 예비 분석은 일반 목적의 컴퓨터 비전 모델이 제기하는 일부 도전 과제를 설명하고 그 편향과 영향을 엿볼 수 있도록 하기 위한 것이다. 이 작업이 이러한 모델의 기능, 단점 및 편향을 특성화하는 데 대한 향후 연구를 동기 부여하길 바라며, 이러한 질문에 대해 연구 커뮤니티와 교류하는 데 기대감을 갖고 있다.
앞으로 나아가는 데 좋은 단계 중 하나는 커뮤니티 탐색을 통해 CLIP과 같은 모델의 기능을 더욱 특성화하고 성능이 유망한 응용 분야와 성능이 감소할 수 있는 분야를 식별하는 것이다. 이러한 특성화 과정은 모델이 유익하게 사용도리 가능성을 높이는 데 도움이 될 수 있다.
- 연구 과정 초기에 모델의 잠재적으로 유익한 하류 사용을 식별하여 다른 연구자들이 응용 프로그램에 대해 생각하도록 한다.
- 상당한 민감성을 가진 task와 사회적 이해 관계자가 많은 task를 드러내어 정책 입안자들의 개입을 요구할 수 있다.
- 모델의 편향을 더 잘 특성화하여 다른 연구자들의 우려 사항과 개입 영역을 알 수 있도록 한다.
- CLIP과 같은 시스템을 평가하기 위한 테스트 모음을 생성하여 개발주기 초기에 모델 기능을 더 잘 특성화할 수 있도록 한다.
- 잠재적 실패 모드와 추가 연구 영역을 식별한다.
이 분석이 후속 연구를 위한 동기 부여 예제를 제공하기를 바라며 이 연구에 기여할 계획이다.
8. Conclusion
NLP에서의 task-agnostic 대규모 사전 훈련의 성공을 다른 분야로 전이할 수 있는지 여부를 조사했다. 이 공식을 채택하는 것은 컴퓨터 비전 분야에서 비슷한 행동이 나타나는 것으로 나타났으며 이 연구 분야의 사회적 함의를 논의한다. 훈련 목표를 최적화하기 위해 CLIP 모델은 사전 훈련 동안 다양한 task를 수행하는 방법을 배운다. 이 task 학습은 자연어 프롬프팅을 통해 많은 기존 데이터셋으로 zero-shot 전이를 가능하게 할 수 있다. 충분한 규모에서 이 접근 방식의 성능은 task 특화 감독 모델과 경쟁할 수 있지만 여전히 크게 개선할 여지가 있다.



