본 글은 https://arxiv.org/abs/1908.03557 내용을 기반으로 합니다.
혹시 잘못된 부분이나 수정할 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
Abstract
광범위한 vision-and-language task를 모델링 하기위한 간단하고 유연한 framework인 VisualBERT를 제안한다. VisualBERT는 self-attention을 통해 input text의 요소들과 연관된 input image의 영역을 정렬하는 Transformer layer로 구성된다. 추가적으로 image caption 데이터를 사용하여 VisualBERT를 pre-training을 하기 위한 두 가지 시각적으로 기반을 둔 언어 모델 objective를 제안한다. VQA, VCR, NLVR2, Flickr30K를 포함한 네 가지 vision-and-language task들에 대한 실험에서 VisualBERT는 SOTA 성능을 보여주고 훨씬 더 단순하다는 것을 보여준다. 추가적으로 분석한 결과, VisualBERT는 명시적인 supervision이 없이도 언어 요소를 이미지 영역에 연결할 수 있음을 보여준다. 예를 들어, 동사와 그 대상에 해당하는 이미지 영역 간의 연관성을 추적하는 등 구문적 관계에 대해서도 파악할 수 있다.
1. Introduction
visual question answering, visual reasoning과 같은 vision-and-language task들은 모델이 이미지의 객체, 속성, 부분, 공간적 관계, 행동 및 의도와 같은 다양한 상세한 의미를 이해하고 어떻게 이러한 모든 개념들이 자연어에서 어떻게 언급되고 연결되는지를 도전 과제로 제시한다.
본 논문에서는 image와 관련된 text의 풍부한 의미를 포착하기 위해 설계된 간단하고 유연한 모델인 VisualBERT를 제안한다. VisualBERT는 자연어 처리를 위한 최신 Transformer 기반 모델인 BERT와 pretrain된 Faster-RCNN을 통합하여 다양한 vision-and-language task들에 적용 가능하다. 특히, 객체 제안에서 추출된 image 특징들은 순서 없는 input token으로 처리되어 text와 함께 VisualBERT에 입력된다. text와 image input들은 VisualBERT의 여러 Transformer layer들에 의해 공동으로 처리된다(Figure 2). 단어들과 객체 제안들 간의 풍부한 상호작용을 통해 모델은 text와 image간의 복잡한 연관성을 포착할 수 있다.

BERT와 유사하게 VisualBERT를 pre-training하는 것은 downstream task에 도움이 될 수 있다. image와 text 간의 연관성을 학습하기 위해, image caption data에 VisualBERT를 pre-training하는 것을 고려한다. 여기서, 이미지의 상세한 의미들은 자연어로 표현된다. 본 논문은 pre-training을 위한 두 가지 시각적으로 기반을 둔 언어 모델 objective를 제안한다.
(1) text의 일부를 마스킹하고 모델이 남은 text와 시각적 맥락을 기반으로 마스킹된 단어를 예측하도록 학습
(2) 주어진 text가 이미지와 일치하는지에 대한 여부를 판단하도록 훈련
본 논문은 image caption 데이터에서 pre-training하는 것이 VisualBERT가 text와 시각적 표현을 학습하는 데 중요하다는 것을 보여준다.
네 가지 vision-and-language task들에 대해 실험을 수행
(1) visual question answering (VQA 2.0)
(2) visual commonsense reasoning (VCR)
(3) natural language for visual reasoning (NLVR)
(4) region-to-phrase grounding (Flickr30K)
COCO image caption dataset을 이용하여 VisualBERT를 pre-training함으로써 VisualBERT는 SOTA 성능을 달성한다. 추가적으로 디자인 선택에 있어 정당화하기 위해 상세한 ablation study를 제공한다. 추가적인 정량적 및 정성적 분석을 통해 VisualBERT가 단어와 이미지 영역을 내부적으로 정렬하기 위해 attention 가중치들을 어떻게 할당하는지 보여준다. 본 논문은 pre-training을 통해 VisualBERT가 개체를 연결하고 단어와 이미지 영역 간의 특정 의존 관계를 인코딩하여 모델이 이미지의 상세한 의미를 이해하는 데 기여하는 방법을 보여준다(Figure 1).
2. Related Work
vision과 language를 연결하는 연구는 오래되었으며 visual question answering, textual grounding 및 visual reasoning과 같은 다양한 task들이 제안되었고 이를 해결하기 위한 다양한 모델들이 개발되었다. 이러한 접근법들은 text encoder, image feature 추출기, multi-modal 융합 모듈과 answer classifier로 구성된다. 대부분의 모델들은 특정 task에 맞춰 설계된 반면 VisualBERT는 범용적으로 설계되어 새로운 task에 쉽게 적응하거나 다른 특정 task 모델에 통합될 수 있다.
image에 묘사된 상세한 의미를 이해하는 것은 시각적 이해에서 매우 중요하다. 이전 연구들은 이러한 의미를 모델링하는 것이 vision-an-language 모델에 도움이 될 수 있음을 보여줬다. VisualBERT에서 self-attention 메커니즘은 객체 간의 암묵적 관계를 포착할 수 있게 해준다. 더 나아가, image caption 데이터를 사용해 pre-training하는 것이 모델이 이러한 관계를 포착하는 방법을 가르치는 효과적인 방법이라고 주장한다.
본 연구는 Transformer 기반 표현 모델인 BERT에서 영감을 받았다. 이는 언어 모델링 objective(남아 있는 문맥을 기반으로 마스킹된 단어를 예측)를 통해 pre-training하여 language encoder를 학습한다. 논문 소개 시점 기준으로 동시에 연구된 두 가지 연구가 유사하다. VideoBERT는 요리 비디오에 대한 캡션 생성에서 평가되는 반면, 본 연구는 다양한 task에 대한 종합적인 분석을 수행한다. ViLBERT는 vision과 language를 위한 별도의 Transformer를 가지고 있다.
3. A Joint Representation Model for Vision and Language
이 섹션에서는 vision과 language의 표현을 학습하기 위한 모델인 VisualBERT를 소개한다. 먼저 BERT에 대한 배경을 설명하고(3.1), image와 text를 같이 처리할 수 있도록 하기 위해 본 논문에서 수행한 내용을 요약한다(3.2). 그리고 Figure 2에서 볼 수 있듯이, 마지막으로 training 절차를 설명한다(3.3).
3.1 Background
BERT는 subword를 입력으로 사용하고 언어 모델링 objective를 사용하여 훈련된 Transformer이다. 입력 문장의 모든 서브워드는 임베딩 집합 E에 매핑된다. 각 임베딩은 다음의 합으로 계산된다.
1) a token embedding
2) segment embedding
3) position embedding
BERT는 pre-training과 fine-tuning 두 단계를 통해 훈련된다. pre-training은 두 가지 언어 모델링 objective의 조합을 사용하여 수행된다. (1) masked language modeling, 입력 토큰의 일부를 무작위로 마스크 토큰으로 변경하고 모델이 그 토큰들을 예측해야 한다. (2) next sentence prediction, 모델이 문장 쌍을 받아 그것들이 연속된 두 문장인지 여부를 분류하도록 훈련된다. 마지막으로, 특정 task에 BERT를 적용하기 위해 task별 input, output layer 및 objective가 도입되며 모델은 task에 맞게 fine-tuning 된다.
3.2 VisualBERT
본 논문의 핵심 아이디어는 Transformer 내에서 self-attention 메커니즘을 재사용하여 input text의 요소들과 input image의 영역을 암묵적으로 정렬하는 것이다. BERT의 모든 구성 요소에서 추가로 이미지를 모델링하기 위해 visual embedding 집합 F를 도입한다. F의 각 f는 object detector에서 도출된 이미지 내의 bounding 영역에 해당한다.
F의 각 embedding은 세 가지 임베딩의 합으로 계산된다.
(1) fo, f의 bounding 영역에 대한 시각적 특징 표현 (CNN에 의해 계산)
(2) fs, text embedding과 반대되는 image embedding을 나타내는 segment embedding
(3) fp, position embedding
visual embedding은 기존 text embedding 집합과 함께 multi-layer Transformer로 전달되어 모델은 두 입력 집합 간의 유용한 정렬을 암묵적으로 발견하고 새로운 표현을 구축할 수 있게 한다.
3.3 Training VisualBERT
BERT와 유사한 훈련 절차를 채택하지만 VisualBERT는 언어와 시각적 input을 모두 처리할 수 있어야 한다. 따라서, 본 논문은 이미지마다 5개의 독립적인 캡션이 있는 COCO dataset을 사용한다. 훈련 절차는 세 단계로 구성된다.
Task-Agnostic Pre-Training
VisualBERT는 두 가지 시각적으로 기반한 언어 모델 objective를 사용하여 COCO에서 훈련한다.
(1) image와 함께하는 Masked language modeling. input text의 일부 요소는 마스킹되어 예측해야 하지만 image 영역에 해당하는 벡터는 마스킹되지 않는다.
(2) Sentence-image prediction. COCO dataset에는 하나의 이미지에 여러 가지 캡션이 있으므로 두 개의 캡션으로 구성된 text segment를 제공한다. 하나는 이미지를 설명하는 캡션이고 다른 하나는 50% 확률로 또 다른 해당 캡션이거나 50% 확률로 무작위로 선택된 캡션이다. 모델은 이 두 가지 상황을 구별하도록 훈련된다.
Task-Specific Pre-Training
VisualBERT를 downstream task에 fine-tuning하기 전에, image objective와 함께 masked language modeling을 사용하여 task의 데이터를 사용해 모델을 훈련하는 것이 유익하다는 것을 발견하였다. 이 단계는 모델이 새로운 target domain에 적응할 수 있도록 한다.
Fine-Tuning
이 단계는 BERT fine-tuning을 반영하며, task별 input, output 및 objective가 도입되고 Transformer가 task 성능을 극대화하도록 훈련된다.
4. Experiment
본 논문은 네 가지 다른 유형의 vision-language task에서 VisualBERT를 평가한다.
(1) Visual Question Answering (VQA 2.0)
(2) Visual Commonsense Reasoning (VCR)
(3) Natural Language for Visual Reasoning (NLVR2)
(4) Region-to-Phrase Grounding (Flickr30K)
각 task들은 다음 섹션과 부록에서 자세히 설명된다. 모든 task에서 pre-training을 위해 COCO의 Karpathy train 분할을 사용한다. 여기에는 약 10만 개의 이미지 당 5개의 캡션이 포함되어 있다. 모든 모델의 Transformer 인코더는 BERT base 모델과 동일한 구성을 갖는다. 12 layers, 768 hidden size, 12 self-attention heads. 파라미터들은 BERT base 파라미터로 초기화한다.
image 표현을 위해 각 dataset은 표준 object detector를 사용하여 영역 제안 및 영역 특징을 생성한다. 각 task마다 다른 image 특징들을 사용한다. 일관성을 위해, COCO에서 pre-training하는 동안 최종 task에서 사용된 것과 동일한 image 특징을 사용한다. 각 dataset에 대해 세 가지 모델 변형을 평가한다.
VisualBERT
BERT base 모델로 파라미터 초기화를 하고 COCO dataset으로 pre-training한 후, task에 맞게 fine-tuning한 모델
VisualBERT w/o Early Fusion
초기 Transformer layer에서 image 표현들이 text와 결합되지 않고 대신 마지막에 새로운 Transformer layer와 결합되는 모델. 이는 전체 Transformer에서 언어와 비전 간의 상호작용이 성능에 중요한지 테스트할 수 있음.
VisualBERT w/o COCO Pre-training
COCO dataset을 이용하여 pre-training을 생략한 모델. 이는 pre-training 과정의 중요성을 검증할 수 있음.
BERT 모델과 같이, 모든 모델들은 Adam을 사용하여 최적화한다. 별도로 명시하지 않는 한, 전체 training step의 10%를 warm-up step으로 설정한다. batch size는 길이가 128자를 초과하는 텍스트 시퀀스는 자른다. 실험은 Tesla V100s와 GTX 1080Ti에서 수행한다. COCO dataset을 이용한 pre-training은 하루 이내에 완료되고 task별 pre-training과 fine-tuning은 보통 그보다 적은 시간이 걸린다.
4.1 VQA
VQA는 image와 질문이 주어졌을 때, 올바르게 질문에 답하는 task이다. 본 논문은 COCO에서 가져 온 이미지에 대해 100만개 이상의 질문으로 구성된 VQA 2.0 dataset을 사용한다. 모델을 훈련시켜 가장 빈번한 3,129개의 답변을 예측하도록 하며 Visual Genome에서 pre-train된 ResNeXt 기반인 Faster RCNN에서 image 특징을 추출하여 사용한다.
Table 1은 결과를 보여주며 동일한 시각적 특징과 bounding region 수를 사용한 baseline(first section), 본 논문이 제안한 모델(second section), 그리고 Visual Genome에서 외부 question-answer 쌍과 multiple detector를 사용하고 앙상블을 사용하는 비교할 수 없는 다른 방법들(third section)을 포함한다. 비교 가능한 설정에서 본 논문에서 제안한 방법은 기존 작업보다 훨씬 단순하고 성능이 우수하다.

4.2 VCR
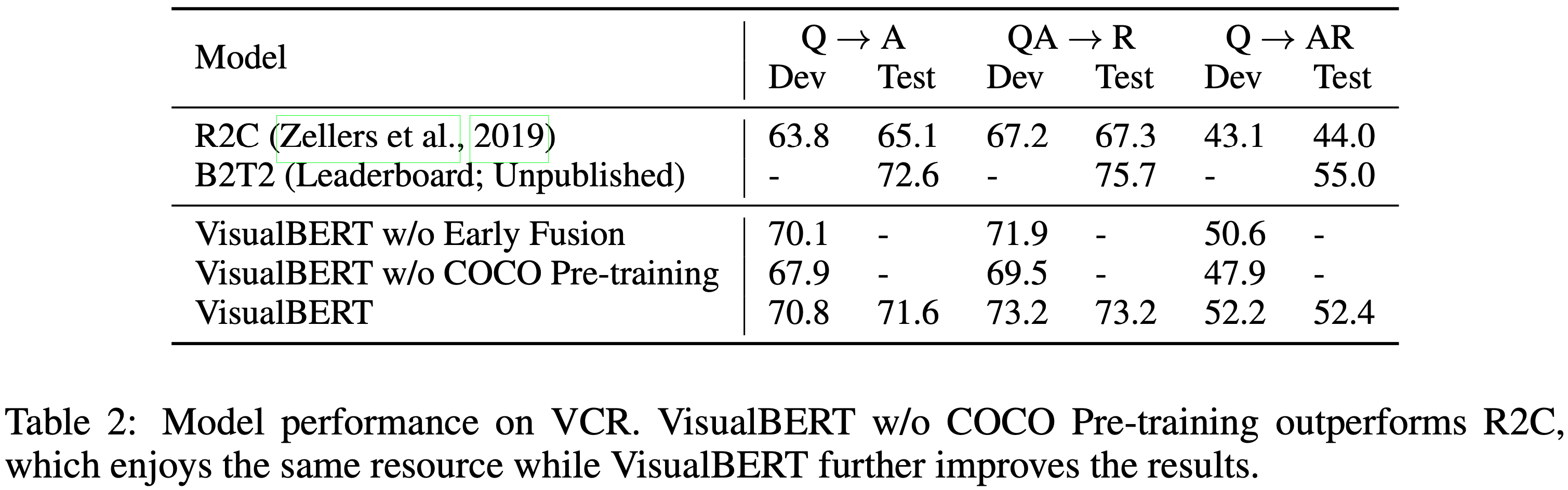
VCR은 11만 개의 영화 장면에서 파생된 29만 개의 질문으로 구성되어 있으며 질문은 시각적 상식(visual commonsense)을 중점으로 한다. 이 task는 두 개의 다중 선택 하위 과제로 나뉘며 본 논문은 개별 모델을 훈련시킨다. 질문 응답(Q->A)와 답변 정당화(QA->R). image 특징은 ResNet50에서 얻으며 dataset에서 제공된 "gold" detection bounding box와 segmentation을 사용한다. dataset은 또한 단어와 bounding 영역 간의 정렬을 제공하며 본 논문은 일치하는 단어와 영역에 동일한 position embedding을 사용하여 활용한다. 자세한 내용은 부록 B에 있다.
VCR에 대한 결과는 Table 2에서 보여준다. BERT를 기반으로 구축된 dataset과 함께 제공된 R2C 모델과 리더보드에서 가장 높은 성능을 보이는 모델 B2T2 모델과 비교한다. VisualBERT w/o COCO Pre-training 모델은 R2C 모델과 동일한 자원을 사용하며 훨씬 단순함에도 불구하고 큰 차이로 R2C를 능가한다. VisualBERT 모델은 더 좋은 성능을 보여주며 COCO와 VCR 간의 상당한 도메인 차이에도 불구하고 COCO를 이용한 pre-training은 큰 도움이 되었다.
4.3 NLVR2
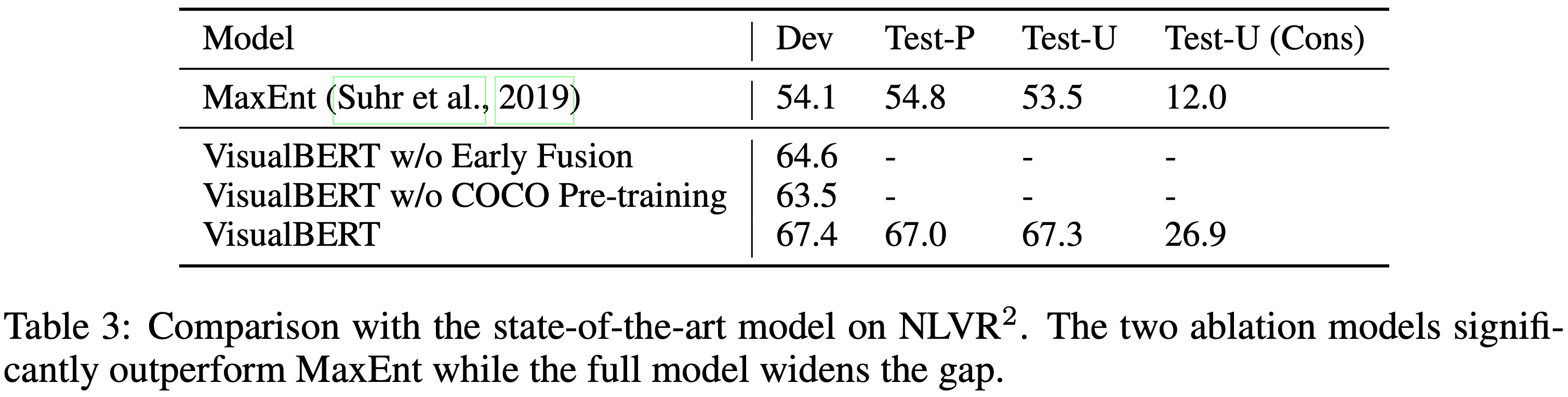
NLVR2는 자연어와 image를 함께 추론하는 dataset이다. 의미적 다양성, 구성성 및 시각적 추론 도전에 중점을 둔다. 이 task는 자연어 캡션이 한 쌍의 이미지에 대해 참인지 여부를 결정하는 것이다. 이 dataset은 웹 image와 짝을 이룬 10만 개 이상의 영어 문장 예시로 구성되어 있다. VisualBERT에서 segment embedding 메커니즘을 수정하여 다른 image에서 온 특징들에 서로 다른 segment embedding을 할당한다. image 특징을 제공하기 위해 off-the-shelf detector를 사용하며 이미지당 144개의 제안을 사용한다. 자세한 내용은 부록 C에 있다.
Table 3은 결과를 보여준다. VisualBERT w/o COCO Pre-training은 이전 최고 모델인 MaxEnt를 큰 차이로 능가하고 VisualBERT는 더 큰 격차로 성능을 능가한다.
4.4 Flickr30K Entities
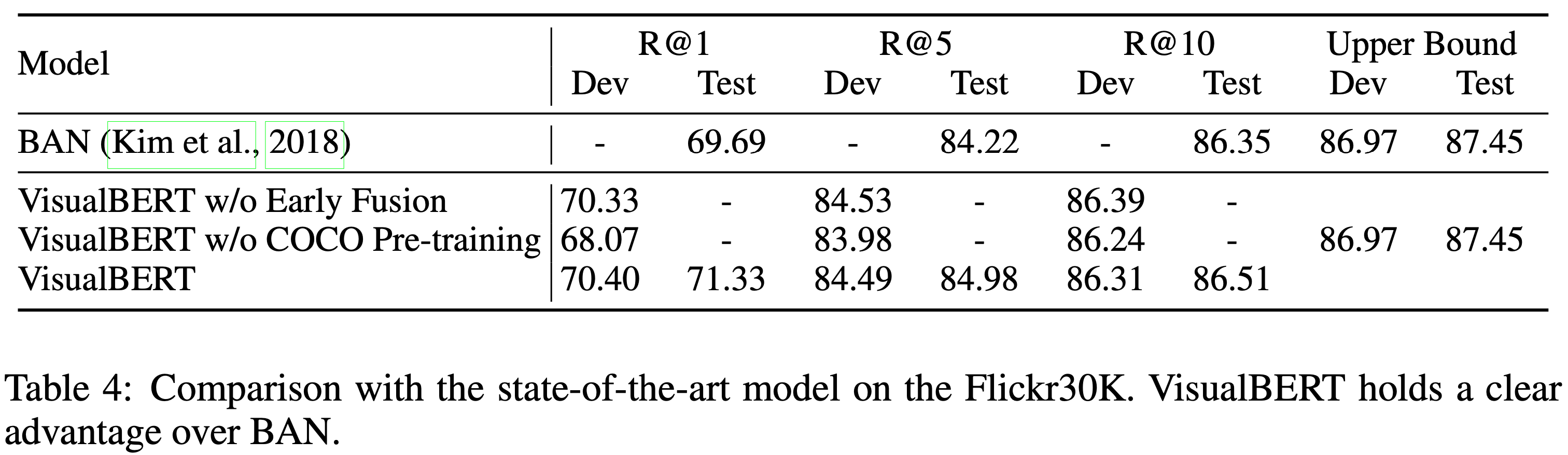
Fickr30K Entities dataset은 캡션의 구문을 image의 bounding 영역에 연결하는 시스템의 능력을 테스트한다. 이 task는 문장에서 특정 부분(span)이 주어졌을 때, 그것들이 대응하는 bounding 영역을 선택하는 것이다. 이 dataset은 3만 개의 image와 약 25만 개의 주석으로 구성되어 있다. Visual Genome에서 pre-train된 Faster R-CNN의 image 특징을 사용하는 BAN의 설정을 적용한다. task별 fine-tuning을 위해 추가적인 self-attention block을 도입하고 각 head에서 평균 attention 가중치를 사용하여 박스와 구문 간의 정렬을 예측한다. 구문이 연결되기 위해 구문의 마지막 서브워드로부터 가장 많은 주의를 받는 박스를 모델 예측으로 사용한다. 자세한 내용은 부록 D에 있다.
Table 4는 결과를 보여준다. VisualBERT는 SOTA 모델인 BAN을 능가한다. VisualBERT w/o Early Fusion 모델과 VisualBERT 모델 간에 유의미한 차이가 없음을 관찰하여 아마도 이 task는 더 얕은 아키텍처가 충분할 것이라고 주장할 수 있다.
5. Analysis
이 section에서는 VisualBERT의 높은 성능을 이끌게 해 준 중요한 접근 방식의 부분들을 광범위하게 분석한다(5.1). 그 다음, Flickr30K를 진단 dataset으로 사용하여 VisualBERT의 pre-training 단계가 실제로 모델이 bounding 영역과 text 구문 간의 암묵적인 정렬을 학습할 수 있도록 하는지 이해하고자 한다. VisualBERT 내의 많은 attention head들이 정확하게 정렬 정보를 추적하고 있으며 일부는 구문에 민감하여 문장에서 동사와 해당하는 논쟁 간의 bounding 영역을 주목하는 것을 보여준다(5.2). 마지막으로, Transformer의 여러 layer들을 통해 VisualBERT가 모호한 정렬을 어떻게 해결하는지에 대한 예시를 제공한다(5.3).
5.1 Ablation study
NLVR2에 대한 ablation study를 수행하고 section 4에서 소개한 두 개의 모델과 비교하기 위해 네 가지 VisualBERT 변형 모델을 포함한다. 계산 용이성을 위해 모든 모델들은 이미지당 36개의 특징만으로 훈련된다. 우리의 분석(Table 5)은 VisualBERT의 다음 네 가지 구성 요소의 기여도를 조사하는 것을 목표로 한다.
C1: Task-agnostic Pre-training.
pre-training 과정을 완전히 생략한 경우(VisualBERT w/o COCO Pre-training)와 COCO에서 text만 사용하고 image는 사용하지 않는 경우(VisualBERT w/o Grounded Pre-training)를 통해 이 구성 요소의 기여도를 조사한다. 두 변형 모두 성능이 저조하여 시각과 언어 데이터의 짝지어진 pre-training이 중요함을 보여준다.
C2: Early Fusion.
VisualBERT w/o Early Fusion 모델을 포함하여 image와 text 특징 간의 초기 상호작용을 허용하는 것이 중요한지 확인한다. 다시 한 번 시각과 언어 간의 여러 상호작용 layer가 중요함을 확인한다.
C3: BERT Initialization.
지금까지 논의된 모든 모델은 pre-train된 BERT 모델의 매개변수로 초기화되었다. BERT 초기화의 기여도를 이해하기 위해, 무작위로 초기화된 매개변수를 사용하는 변형 모델을 도입한다. 그런 다음 이 모델은 전체 모델과 동일하게 훈련된다. 언어로만 pre-train된 BERT의 가중치는 중요하지만, 성능 저하는 예상보다 크지 않아 모델이 COCO pre-training 과정에서 유용한 언어 요소를 많이 학습하고 있음을 시사한다.
C4: The sentence-image prediction objective.
pre-training 과정에서 sentence-image 예측 objective를 제외한 모델(VisualBERT w/o Objective 2)을 도입한다. 결과는 objective가 긍정적인 영향을 미치지만 다른 구성 요소에 비해 그 효과는 덜 중요함을 시사한다.
중합적으로, 결과는 가장 중요한 design 선택이 task-agnostic pre-training(C1)과 early fusion of vision and language(C2)임을 확인한다. pre-training 과정에서 추가적인 COCO data를 포함하고 image와 캡션을 모두 사용하는 것이 가장 중요하다.

5.2 Dissecting Attention Weights
이 section에서는 VisualBERT가 어떤 task에 fine-tuning되기 전에 단어가 어떤 bounding 영역에 주의를 기울이는지 조사한다.
Entity Grounding.
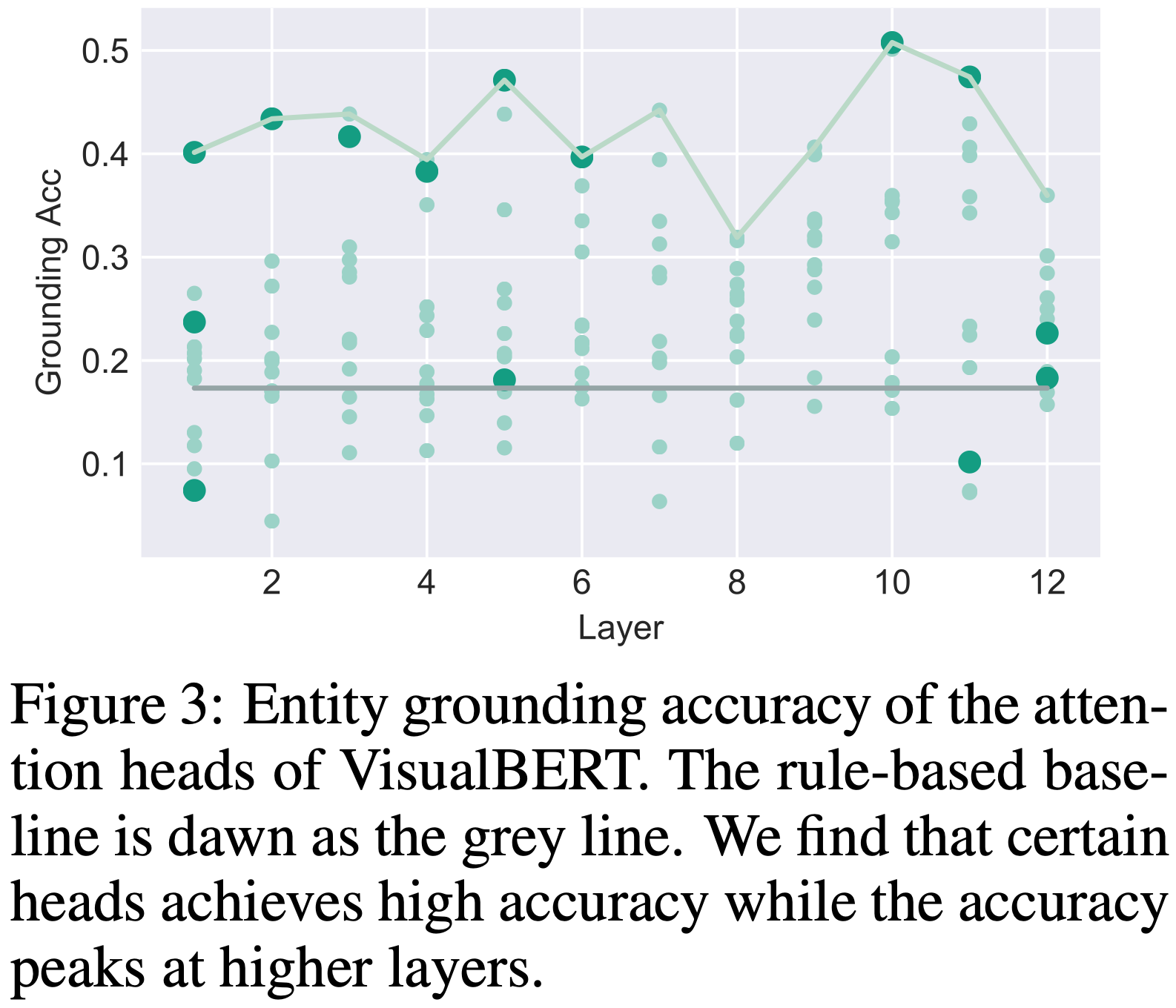
먼저, VisualBERT 내에서 문장의 entity와 대응하는 bounding 영역에 주목하는 attention head를 찾으려고 시도한다. 구체적으로, Flickr30K 평가 세트의 실제 정렬 정보를 사용한다. 문장의 각 entity와 VisualBERT의 각 attention head에 대해 가장 많은 attention weight를 받는 bounding 영역을 확인한다. 단어가 image 영역뿐만 아니라 text 내의 다른 단어에도 주목할 가능성이 있기 때문에 이 평가에서는 attention head가 단어에 주는 attend는 마스킹하고 image 영역에만 attend할 수 있도록 한다. 그 후, 특정 attention head가 Flickr30K의 주석과 얼마나 일치하는지 계산한다.
Figure 3은 VisualBERT의 144개 모든 attention head에 대해 layer별로 조직된 정확도를 보여준다. 또한, 가장 높은 탐지 신뢰도를 가진 영역을 선택하는 baseline도 고려한다. VisualBERT는 entity 정렬에 대해 직접적인 감독을 받지 않았음에도 불구하고 높은 정확도를 달성했다. 정렬 정확도는 상위 layer에서 더 향상되는 것으로 보이며, 이는 모델이 하위 layer에서는 두 입력을 통합하는 데 덜 확실하지만 상위 layer로 갈수록 더 잘 정렬된다는 것을 보여준다. 이러한 행동의 예는 5.3에 나와 있다.
Syntactic Grounding.
많은 연구자들이 BERT의 attention head가 구문 관계를 발견할 수 있음을 관찰한 바 있다. 따라서 우리는 VisualBERT가 발견할 수 있는 구문 관계를 통해 정렬 정보가 어떻게 전달되는지 분석한다. 특히, 의존 관계로 연결된 두 단어(w1과 w2)가 있을 때, w2에서의 attention head가 w1에 대응하는 영역에 얼마나 자주 attend하는지 그 반대의 경우도 살펴본다. 예를 들어, Figure 1에서 "walking"이라는 단어가 "man"에 대응하는 영역에 체계적으로 주목하는 attention head가 있는지 알고자 한다. 이는 "man"과 "walking"이 stanford 의존 구문 해석 형식에서 "nsubj" 관계로 연결되어 있기 때문이다.
VisualBERT의 이러한 구문 민감도를 평가하기 위해 먼저 Flickr30K의 모든 문장을 AllenNLP의 의존 구문 분석기를 사용하여 구문 분석을 한다. 그런 다음, VisualBERT의 각 attention head에 대해 두 단어가 특정 의존 관계를 가지고 있을 때, 하나의 단어가 Flickr30K에서 실제로 정렬된 경우, attention weight가 실제 정렬을 얼마나 정확하게 예측했는지 계산한다. 모든 의존 관계를 조사한 결과, VisualBERT는 각 attention head에 대해 가장 신뢰도가 높은 bounding 영역을 추정하는 것보다 성능이 뛰어난 attention head가 적어도 하나씩 존재함을 보여준다. Figure 4에서는 특히 흥미로운 몇 가지 의존 관계를 강조한다. VisualBERT가 문장 내에서 주어, 동사, 목적어 간의 관계를 이해하고 이를 이미지 내의 적절한 bounding 영역과 연결할 수 있음을 보여준다. 그리고 이러한 학습은 명시적인 지도 없이도 이루어진다.

5.3 Qualitative Analysis
마지막으로, 우리는 Figure 1과 Figure 5에서 VisualBERT가 image와 text를 처리할 때 layer를 거치며 attention이 어떻게 변하는지 보여주는 여러 흥미로운 예시를 제시한다. 이러한 예시를 생성하기 위해, 각 실제 bounding box에 대해 가장 가까운 예측 bounding 영역을 표시하고 수동으로 bounding 영역을 다른 카테고리로 그룹화했다. 또한, 실제 주석에는 없지만 모델이 적극적으로 주목하는 영역(별표로 표시)도 포함한다. 그런 다음 동일한 카테고리 내의 영역에 대한 단어의 attention 가중치를 집계한다. 가장 높은 entity 정렬 정확도를 달성하는 6개의 layer에서 가장 좋은 attention head를 보여준다.
전체적으로, VisualBERT가 연속적인 Transformer layer를 통해 정렬을 세분화하는 것처럼 보인다. 예를 들어, Figure 5의 왼쪽 하단 이미지에서 처음에는 "husband"와 "woman"이라는 단어가 모두 여성에 해당하는 영역에 상당한 attention weight를 가지고 있다. 계산이 끝날 때 쯤, VisualBERT는 여성과 남성을 분리하여 둘 다 올바르게 정렬한다.

6. Conclusion and Future Work
본 논문에서는 vision과 language의 표현을 위한 pre-train된 VisualBERT를 소개했다. VisualBERT는 단순하지만 네 가지 task에서 높은 성능을 달성하였다. 추가 분석에서는 모델이 attention 메커니즘을 사용하여 정보를 해석 가능한 방식으로 포착한다는 것을 시사한다. 향후 작업으로는 VisualBERT를 장면 그래프 파싱 및 상황 인식과 같은 image 전용 작업으로 확장할 수 있을지에 대한 궁금증이 있다. Visual Genome 및 Conceptual Caption과 같은 더 큰 캡션 dataset에 VisualBERT를 pre-training 하는 것도 유효한 방향이다.



