본 글은 https://arxiv.org/abs/1908.07490 내용을 기반으로 합니다.
혹시 잘못된 부분이나 수정할 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
Abstract
vision과 language의 추론은 시각적 개념, 언어적 의미, 그리고 무엇보다도 두 가지 모달리티 간의 정렬과 관계를 이해하는 것을 요구한다. 따라서, 본 논문은 vision과 language의 연결을 학습하기 위해 LXMERT(Learning Cross-Modality Encoder Representations from Transformers)를 제안한다. LXMERT에서 object relationship encoder, language encoder, cross-modality encoder로 구성된 대규모 Transformer를 구축한다. 그 후, vision과 language의 의미를 연결하는 능력을 모델에 부여하기 위해, 다섯 가지 다양한 대표적인 pre-training task들을 통해 다량의 이미지와 문장 쌍으로 모델을 pre-train한다. 다섯 가지 pre-training task는 masked language modeling, masked object prediction(feature regression and label classification), cross-modality matching, image question answering이다. 이러한 task들은 모달리티 내 및 모달리티 간 관계를 학습하는데 도움을 준다. pre-train된 파라미터를 fine-tuning한 후, 모델은 두 가지 VQA dataset(VQA and GQA)에서 SOTA 성능을 달성한다. 또한, pre-train된 cross-modality 모델의 일반화를 보여주면서 visual-reasoning task(NLVR2)에 적응시켜 이전 최고 결과를 22% 개선한다. 마지막으로, 본 논문에서 소개한 새로운 모델 구성 요소와 pre-training 전략이 강력한 결과에 기여한다는 것을 증명하기 위해 상세한 ablation study들을 수행하고 다양한 인코더에 대한 attention 시각화를 제공한다.
1. Introduction
vision과 language 추론은 시각적 내용, 언어적 의미, cross-modal 정렬 및 관계를 이해하는 것을 요구한다. vision과 language의 단일 모달리티에 대해 더 나은 표현을 갖춘 모델을 개별적으로 개발하는 데 많은 과거 연구가 있었다. 하지만, vision과 language의 모달리티 쌍에 대한 대규모 pre-training과 fine-tuning 연구는 여전히 개발이 미흡한 상태이다.
따라서, 본 논문은 pre-train된 vision과 language cross-modality 프레임워크를 구축하는 최초의 작업 중 하나를 제시하며 여러 데이터셋에서 좋은 성능을 보여준다. 이 프레임워크를 "LXMERT: Learning Cross-Modality Encoder Representations from Transformers"라고 부른다. 이 프레임워크는 BERT 모델 기반으로 모델링되었으며 유용한 cross-modality 시나리오에 맞게 적응되었다. 이 새로운 cross-modality 모델은 vision과 language 상호작용을 학습하는 데 중점을 두고 있으며, 특히 단일 이미지와 설명 문장의 표현을 대상으로 한다. 본 모델은 세 가지 Transformer encoder로 object relationship encoder, language encoder, cross-modality encoder로 구성된다. vision과 language 간의 cross-modal 정렬을 더 잘 학습하기 위해, 다섯 가지 다양한 대표 task들을 통해 pre-train한다.
(1) masked cross-modality language modeling
(2) masked object prediction via RoI-feature regression
(3) masked object prediction via detected-label classification
(4) cross-modality matching
(5) image question answering
단일 모달리티 pre-training(e.g., masked LM in BERT)과 달리, 이 multi-modality pre-training은 동일한 모달리티의 시각적 요소 또는 다른 모달리티의 정렬된 구성 요소에서 masked 특징들을 추론할 수 있게 한다. 이렇게 함으로써 모달리티 내 및 cross-modality의 관계를 구축하는 데 도움을 준다.
LXMERT는 두 가지 인기있는 question-answering 데이터셋인 VQA와 GQA에 대해 평가한다. 모든 질문 카테고리(e.g., Binary, Number, Open)에서 이전 작업 성능을 능가하며 전체 정확도 측면에서 SOTA 성능을 달성한다. 또한, pre-train된 모델의 일반화 성능을 보여주기 위해, visual reasoning task인 Natural Language for Visual Reasoning for Real(NLVR2)에 fine-tuning을 하고 평가한다. 정확도에서 22% 및 일관성에서 30% 성능 개선을 달성한다. 마지막으로, 모델 구성 요소와 다양한 pre-training task의 효과를 증명하기 위해 여러 분석과 ablation study들을 수행한다. 특히, 기존 BERT 모델과 그 변형을 여러 가지 방법으로 사용하여 vision과 language task에서의 비효율성을 보여줌으로써 새로운 cross-modality pre-training 프레임워크의 필요성을 입증한다. 그리고 다양한 언어, object 관계, cross-modality encoder에 대한 여러 가지 attention 시각화를 제공한다.
2. Model Architecture
self-attention과 cross-attention layer들로 cross-modality model을 구축한다. Figure 1과 같이, 이미지와 그와 관련된 문장(e.g., a caption or a question)으로 두 가지 input을 받는다. 각 이미지는 object들의 시퀀스로 표현되고 각 문장은 단어들의 시퀀스로 표현된다. self-attention과 cross-attention layer들을 설계하고 조합하여 LXMERT는 input으로부터 언어 표현, 이미지 표현, cross-modality 표현을 생성할 수 있다. 이후 섹션에서는 모델의 구성 요소들을 자세히 설명한다.

2.1 Input Embeddings
LXMERT의 input embedding layer는 input(i.e., an image and a sentence)을 word-level sentence embedding과 object-level image embedding으로 두 개의 특징 시퀀스로 변환한다. 이러한 embedding 특징들은 이후 encoder layer에서 추가로 처리된다.
Word-Level Sentence Embeddings
문장은 먼저 BERT에서 사용된 것과 같이 WordPiece tokenizer를 통해 단어 {w1, ..., wn}으로 길이 n만큼 분할한다. 그 후, Figure 1과 같이 단어 wi와 index i(문장에서 wi의 절대적 위치)를 각각 계산한 후, 이 둘을 더한 결과를 LayerNorm을 통해 정규화한다.
Object-Level Image Embeddings
감지된 object의 특징을 이미지의 embedding으로 사용한다. 구체적으로, object detector는 이미지에서 m개의 object {o1, ..., om}을 감지한다(Figure 1에서 bounding box로 표시됨). 각 object oj는 그 position 특징(i.e., bounding box 좌표) pj와 2048차원의 region-of-interest(RoI) 특징 fj로 표현된다. 두 개의 fully-connected layer 층의 output을 더하여 position-aware embedding vj를 학습한다.
시각적 추론에서 공간 정보를 제공하는 것 이외에도 positional 정보를 포함하는 것은 masked object prediction pre-training task(section 3.1.2에서 설명)에 필수적이다. 이미지 embedding layer와 그 후의 attention layer는 input의 index에 무관하기 때문에 object의 순서는 지정되지 않는다. 마지막으로 방정식 1에서, 두 개의 특징에 대해 합산하기 전에 layer normalization을 적용하여 두 가지 다른 유형의 특징을 균형 있게 맞춘다.
2.2 Encoders
language encoder, object-relationship encoder, cross-madality encoder를 주로 두 가지 종류의 attention layer(self-attention layer와 cross-attention layer)를 기반으로 구축한다. 먼저 attention layer의 정의와 표기법을 검토한 후, 그것들이 어떻게 인코더를 구성하는지 논의한다.
Background: Attention Layers
Attention layer는 query vector x와 관련된 context vectors {yj} 집합에서 정보를 검색하는 것을 목표로 한다. attention layer는 먼저 query vector x와 각 context vector yj 간의 매칭 점수 aj를 계산한다. 그런 다음 점수는 softmax를 통해 정규화된다.
attention layer의 output은 softmax로 정규화된 점수에 대한 context vector의 가중 합이다.
query vector x가 context vectors {yj} 집합에 속할 때, 이러한 attention layer를 self-attention이라고 한다. Transformer 모델에 따라 multihead attention을 사용한다.
Single-Modality Encoders
embedding layer 이후, 두 개의 transformer encoder(i.e., language encoder와 object-relationship encoder)를 적용한다. 각각의 encoder는 하나의 모달리티(i.e., language or vision)에만 집중한다. BERT가 transformer encoder에 대해 language input만 만 적용한 것과 달리, vision input으로도 적용한다. 단일 모달리티 encoder의 각 layer(Figure 1의 왼쪽 점선 블록)는 self-attention sub-layer와 feed-forward sub-layer로 구성되며 feed-forward sub-layer는 두 개의 fully-connected sub-layer로 구성된다. language encoder와 object-relationship encoder는 각각 NL과 NR layer를 사용한다. 각 sub-layer 후에는 residual connection과 layer normalization을 추가한다.
Cross-Modality Encoder
cross-modality encoder의 각 cross-modality layer(Figure 1의 오른쪽 점선 블록)는 두 개의 self-attention sub-layer, 하나의 bi-directional cross-attention sub-layer, 그리고 두 개의 feed-forward sub-layer로 구성된다. crss-modality layer를 Nx개 쌓아서 encoder를 구현한다. k번째 layer 내에서, bi-directional cross-attention sub-layer가 먼저 적용되며, 두 개의 uni-directional cross-attention layer(language에서 vision으로 하나, vision에서 language로 하나)로 구성된다. query 및 context vector들은 k-1번째 layer의 output(i.e., language 특징과 vision 특징)이다.
cross-attention sub-layer는 두 모달리티 간의 정보를 교환하고 엔티티를 정렬하여 cross-modality 표현을 학습하는 데 사용된다. 내부 연결을 추가로 구축하기 위해, self-attention sub-layer는 cross-attention sub-layer의 output에 적용된다.
마지막으로, k번째 layer의 output은 feed-forward sub-layer를 적용하여 생성한다. 단일 모달리티 encoder와 마찬가지로 각 sub-layer 후에는 residual connection과 layer normalization을 추가한다.
2.3 Output Representations
Figure 1의 오른쪽 부분에 표시된 것처럼 LXMERT cross-modality model은 각각 language, vision, cross-modality에 대한 세 가지 output을 가진다. language와 vision output은 cross-modality encoder에 의해 생성된 특징 시퀀스이다. cross-modality output의 경우, BERT 모델과 같이 문장 단어들 앞에 [CLS] 토큰을 추가하고(Figure 1에서 노란색 블록으로 표시), language 특징 시퀀스에서 [CLS] 토큰에 해당하는 특징 벡터를 cross-modality output으로 사용한다.
3. Pre-Training Strategies
vision과 language 간의 연결을 이해하기 위해, 대규모 통합 데이터셋에서 다양한 모달리티를 pre-training task로 모델을 pre-train한다.
3.1 Pre-Training Tasks
3.1.1 Language Task: Masked Cross-Modality LM
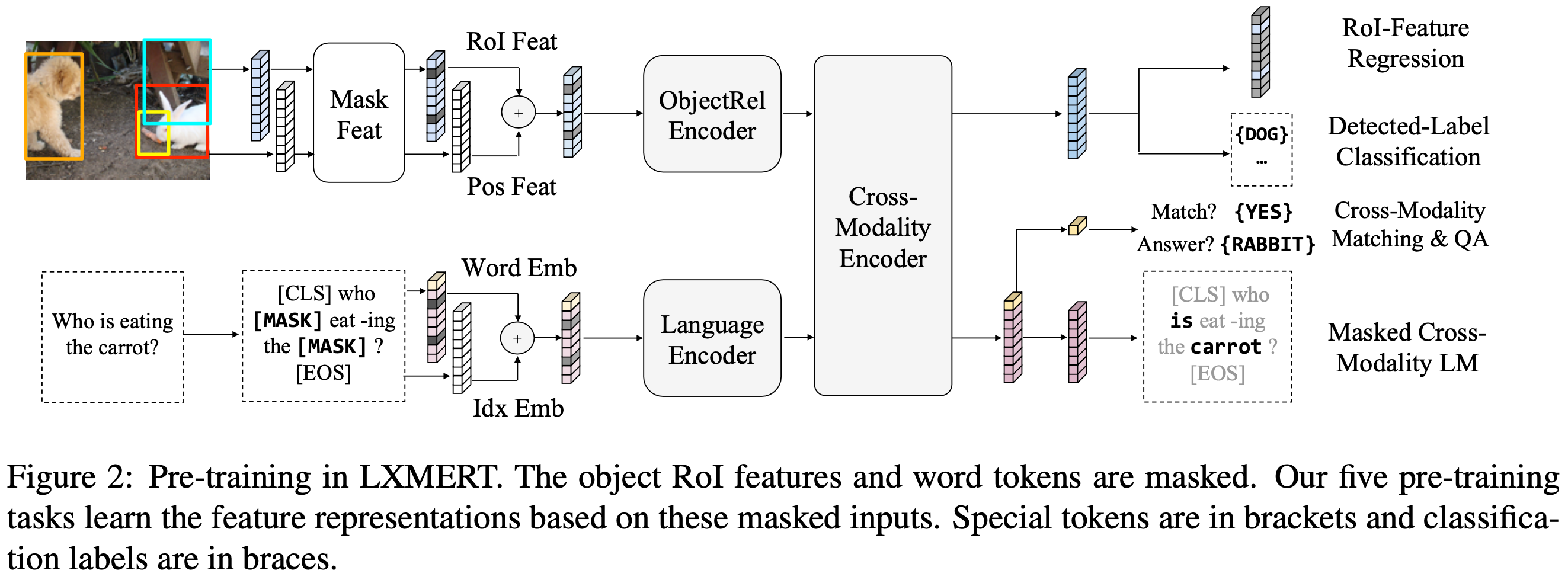
language 측면에서는 masked cross-modality language model (LM) task를 수행한다. Figure 2의 좌측 아래쪽에 표시된 것과 같이, 이 task 설정은 BERT와 동일하다. 단어는 0.15의 확률로 무작위로 마스킹되며 모델은 이 마스킹된 단어를 예측해야한다. BERT에서 마스킹된 단어를 language 모달리티의 마스킹되지 않은 단어들로부터 예측하는 반면, LXMERT는 cross-modality model 아키텍처를 통해 vision 모달리티로부터 마스킹된 단어를 예측할 수 있다. 예를 들어, Figure 2에 표시된 것처럼 언어 문맥으로부터 마스킹된 단어 'carrot'을 결정하는 것은 어렵지만 시각적 정보를 고려하면 단어 선택이 명확해진다. 따라서, 이것은 vision 모달리티에서 language 모달리티로의 연결을 구축하는 데 도움이 되며 이러한 task를 masked cross-modality LM이라고 부른다. 또한, BERT 파라미터를 LXMERT에 로드하면 pre-training 과정에 해를 끼친다는 것을 section 5.1에서 보여준다. 왜냐하면 BERT는 이러한 cross-modality 연결을 학습하지 않고도 language 모달리티에서 상대적으로 잘 수행할 수 있기 때문이다.
3.1.2 Vision Task: Masked Object Prediction
Figure 2의 좌측 상단에 표시된 것처럼, object를 무작위로 마스킹(i.e., RoI 특징을 0으로 마스킹)하고 0.15의 확률로 모델이 이러한 마스킹된 object의 속성을 예측하도록 하여 시각적 측면을 pre-train한다. language task(i.e., masked cross-modality LM)와 유사하게, 모델은 보이는 object들로부터 또는 language 모달리티로부터 마스킹된 object를 추론할 수 있다. 시각적 측면에서 object를 추론하는 것은 object 간의 관계를 학습하는 데 도움이 되고 language 측면에서 추론하는 것은 cross-modality 정렬을 학습하는 데 도움이 된다. 따라서, 두 가지 sub-task를 수행한다. RoI-Feature Regression은 object RoI 특징 fj를 L2 loss로 회귀하고 Detected-Label Classification은 cross-entropy loss로 마스킹된 object의 label을 학습한다. 'Detected-Label Classification' sub-task에서 대부분의 pre-training 이미지가 object 수준의 주석을 가지고 있지만 주석된 object의 실제 label은 서로 다른 데이터셋에서 일관되지 않는다(e.g., label 클래스의 수가 다름). 이러한 이유로, Faster R-CNN이 출력한 label을 사용한다. 비록 검출된 label이 노이즈가 있을 수 있지만 실험 결과는 이러한 label이 pre-training에 기여한다는 것을 section 5.3에서 보여준다.
3.1.3 Cross-Modality Tasks
Figure 2의 우측 중간 부분에 표시된 것처럼 cross-modality 표현을 학습하기 위해, language와 vision 모달리티 모두를 명시적으로 필요로 하는 두 가지 작업으로 LXMERT 모델을 pre-train한다.
Cross-Modality Matching
각 문장에 대해 0.5의 확률로 불일치하는 문장으로 교체한다. 그 후, 이미지와 문장이 서로 일치하는지 예측하기 위해 classifier를 훈련한다. 이 작업은 BERT 논문의 'Next Sentence Prediction'과 유사하다.
Image Question Answering (QA)
pre-training 데이터셋을 확장하기 위해 (자세한 내용은 section 3.2 참고), pre-training 데이터의 1/3 문장은 이미지에 대한 질문이다. 모델이 이미지와 질문이 일치할 때(i.e., cross-modality matching task에서 무작위로 교체되지 않는 경우), 이미지에 관련된 질문에 대한 답을 예측하도록 요구된다. section 5.2에서 보여주듯이, 이미지 QA task로 pre-training을 하면 더 나은 cross-modality 표현을 얻을 수 있다.
3.2 Pre-Training Data
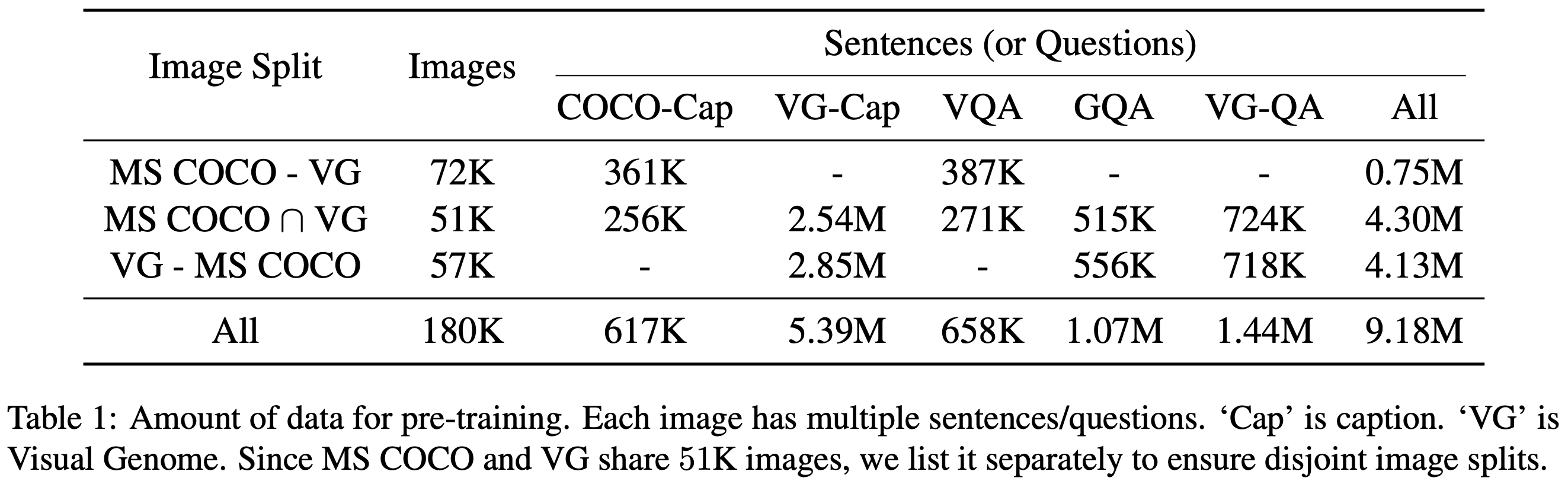
Table 1에서 보여주듯이, MS COCO 또는 Visual Genome에서 이미지를 가져온 다섯 가지 vision-and-language 데이터셋에서 pre-training 데이터를 통합한다. 두 가지 원본 캡션 데이터셋 이외에도, 세 개의 대규모 image question answering 데이터셋인 VQA 2.0, GQA balanced version, VG-QA를 통합한다. pre-training 과정에서 테스트 데이터를 보는 것을 피하기 위해 각 데이터셋에서 train 및 valid 데이터셋만 수집한다. 다섯 개의 데이터셋에서 최소한의 전처리를 수행하여 이미지와 문장 쌍을 정렬한다. 각 image question answering 데이터셋에 대해, 이미지와 문장 데이터 쌍에서 질문을 문장으로 하고 답변을 image QA pre-training task의 label로 사용한다 (section 3.1.3에서 설명됨). 이를 통해 18만 개의 고유 이미지에 대한 918만 개의 이미지-문장 쌍으로 구성된 대규모 vision-and-language 데이터셋을 확보한다. 토큰 측면에서, pre-training 데이터는 약 1억 개의 단어와 650만 개의 이미지 객체를 포함한다.
3.3 Pre-Training Procedure
대규모 통합 데이터셋 (section 3.2)에서 pre-training task (section 3.1)를 통해 LXMERT 모델을 pre-train한다. 데이터 분할에 대한 자세한 내용은 Appendix에 있다. input 문장들은 WordPiece 토크나이저를 사용하여 분할한다. object는 Visual Genome에서 pre-train된 Faster R-CNN에 의해 감지된다. Faster-RCNN detector를 fine-tuning하지 않고 feature 추출기로만 사용한다. 기존 Faster-RCNN에서 가변적인 수의 object를 감지하는 것과 달리, pre-training 계산 활용을 극대화하기 위해 각 이미지에서 일관되게 36개의 object를 유지한다. 모델 아키텍처의 경우, layer 수 NL, NX, NR을 각각 9, 5, 5로 설정한다. 시각적 특징은 101 layer Faster R-CNN에서 추출되므로 language encoder에서 더 많은 layer를 사용하여 균형을 맞춘다. hidden size는 BERT base 모델과 동일하게 768로 설정한다. encoder와 embedding layer의 모든 파라미터를 처음부터 pre-train한다(i.e., 모델 파라미터는 무작위로 초기화되거나 0으로 설정). section 5.1에서 pre-train된 BERT 파라미터를 로드한 결과도 보여준다. LXMERT는 여러 pre-training task와 함께 pre-train되므로 여러 loss들이 관여된다. 이러한 loss들을 동일한 가중치로 더한다. image QA pre-training task의 경우, 세 개의 image QA 데이터셋의 약 90% 질문을 대략적으로 커버하는 9500개의 답변 후보가 있는 답변 테이블을 만든다.
optimizer는 Adam을 이용하고 linear-decayed learning-rate schedule과 최고 learning rate는 1e-4를 사용한다. 모델은 256의 batch size로 20 epoch(i.e., 67만 번의 optimization step)동안 학습된다. 마지막 10 epoch 동안, image QA task만으로 pre-train을 진행한다. 이는 이 task가 더 빠르게 수렴하고 경험적으로 더 작은 learning rate를 필요로 하기 때문이다. 전체 학습 과정은 4개의 Titan Xp GPU를 이용해 10일이 소요된다.
Fine-tuning
각 task에 맞게 모델에 필요한 수정만 수행한다(section 4.2 참조). learning rate는 1e-5 또는 5e-5, batch size는 32를 사용하고 pre-train된 파라미터를 기반으로 모델을 4 epoch동안 fine-tuning한다.
4. Experimental Setup and Results
이 section에서는 LXMERT 프레임워크를 평가하기 위해 사용된 데이터셋을 소개하고 단일 모델 결과를 이전 최고 결과와 비교한다.
4.1 Evaluated Datasets
LXMERT를 평가하기 위해 세 가지 데이터셋 VQA 2.0, GQA, NLVR2를 사용한다. 자세한 내용은 Appendix를 참고하면 된다.
4.2 Implementation Details
VQA와 GQA에서 데이터 증강 없이 pre-train된 모델을 fine-tuning한다(section 5.2의 analysis 참조). GQA를 학습할 때는 원시 질문과 이미지만 input으로 사용하고 다른 supervision(e.g., 기능적 프로그램 및 장면 그래프)을 사용하지 않는다. NLVR2의 각 데이터는 두 개의 자연 이미지(img0, img1)와 하나의 언어 문장(s)을 포함하므로 LXMERT를 사용하여 두 개의 이미지-문장 쌍(img0, s) 및 (img1, s)을 인코딩하고 두 개의 cross-modality ouput의 연결을 기반으로 classifier를 학습한다. 자세한 내용은 Appendix를 참고하면 된다.
4.3 Empirical Comparison Results
VQA, GQA, NLVR2 테스트 세트에서 단일 모델 결과를 이전에 발표된 최고 결과와 비교한다. 이전 SOTA 방법 이외에도 가능할 경우 인간 성능 및 이미지 전용/언어 전용 결과도 함께 보여준다.
VQA
SOTA 결과는 BAN+Counter로 최근 연구들 중에서 가장 높은 정확도를 기록했다. LXMERT는 SOTA 성능보다 전체 정확도(Table 2에서 'Accu') 2.1% 향상시켰으며 'Binary'/'Other' 질문 하위 카테고리에서 2.4% 향상되었다.

GQA
GQA 데이터셋에서 SOTA 결과는 BAN에서 가져왔다. GQA 데이터셋에서는 SOTA 성능에 비해 3.2%의 정확도 향상을 이루었으며 이는 VQA보다 더 높은 향상이다. 이는 GQA가 더 많은 시각적 추론을 요구하기 때문일 수 있다. 따라서, LXMERT는 새로운 encoder와 cross-modality pre-training으로 인해 적합하며 개방형 질문(Table 2에서 'Open')에서 4.6%의 향상을 달성하였다.
NLVR2
NLVR2는 기존 몇몇 접근 방식이 실패한 도전적인 시각 추론 데이터셋으로 SOTA 방법은 MaxEnt이다. 기존 방법들(및 section 5.1의 pre-training 없는 LXMERT 모델)의 실패는 대규모 pre-training 없이 복잡한 vision-and-language task에서 vision과 language 간의 연결이 end-to-end로 학습되지 않을 수 있음을 시사한다. 그러나 본 논문에서 소개한 새로운 pre-training 전략을 통해 cross-modality 연결을 구축함으로써 정확도에서 22% 크게 향상시켰다. 또 다른 평가 지표인 일관성(consistency)은 관련된 모든 이미지 쌍에 대해 고유한 문장이 올바르게 예측되는 비율을 측정한다. LXMERT 모델은 일관성을 42.1%(i.e., 3.5배)로 향상시켰다.
5. Analysis
이 section에서는 LXMERT 프레임워크 일부를 비교하거나 특정 모델 구성 요소/pre-training 전략을 제외하여 분석한다.
5.1 BERT versus LXMERT
BERT는 여러 language task를 개선하는 pre-train된 language encoder이다. Table 3과 같이, BERT base pre-train된 모델을 vision-language task에 통합하는 몇 가지 방법을 논의하고 이를 LXMERT 접근 방식과 경험적으로 비교한다. NLVR2에서 74.9%의 정확도를 가지지만 LXMERT pre-train 없이의 모든 결과는 약 22% 낮다.

BERT+BUTD
Bottom-Up and Top-Down(BUTD) attention 방법은 GRU로 질문을 인코딩한 다음 객체 RoI 특징에 attend하여 답을 예측한다. 본 논문에서는 BUTD의 GRU language encoder를 BERT로 교체하여 BERT를 BUTD에 적용한다. Table 3의 첫 번째 블록에 표시된 것처럼 BERT encoder의 결과는 LSTM encoder와 비슷한 성능을 보인다.
BERT+CrossAtt
BUTD는 객체의 위치와 object 간의 관계를 고려하지 않고 단순히 RoI 특징만을 사용하기 때문에, BERT+BUTD를 새로운 위치 object embedding(section 2.1)과 cross-modality layer(section 2.2)로 강화한다. Figure 3의 두 번째 블록에 표시된 것처럼 1개의 cross-modality layer를 사용한 결과는 BUTD보다 좋았으며 더 많은 cross-modality layer를 쌓으면 성능이 더욱 향상된다. 그러나 cross-modality pre-training을 적용하지 않으면 3개의 cross-attention layer를 추가한 후 결과가 정체되며 전체 LXMERT 프레임워크(Table 3에서 마지막 굵은 행)와는 3.4%의 격차가 있다.
BERT+LXMERT
BERT 파라미터를 LXMERT에 로드하여 모델 학습(i.e., LXMERT pre-training 없이) 또는 pre-training에 사용하는 것도 시도했다. Table 3의 마지막 블록에서 결과를 보여준다. 'from scratch'(i.e., 모델 파라미터가 무작위로 초기화된) 방식과 비교할 때, BERT는 fine-tuning 결과를 개선하지만 전체 모델보다는 약한 결과를 보인다. 경험적으로, BERT 파라미터로 초기화된 LXMERT를 pre-training할 때 처음 3개의 pre-training epoch동안 pre-training loss가 더 낮았지만, 이후에는 'from scratch' 방식이 따라잡았다. 이렇게 가능한 이유로는 BERT가 이미 단일 모달리티 masked language model로 pre-train되어 있기 때문에, vision 모달리티와의 연결을 고려하지 않고도 language 모달리티로만 잘 수행할 수 있기 때문이다(section 3.1.1에서 논의된 바와 같이).
5.2 Effect of the Image QA Pre-training Task
image QA pre-training task(section 3.1.3에서 소개됨)의 중요성을 보여준다.
Pre-training w/ or w/o Image QA
기존 pre-training 절차(10 epoch은 QA 없이 + 10 epoch은 QA 포함)와 공정하게 비교하기 위해, image QA task없이 LXMERT 모델을 20 epoch동안 pre-train한다. Table 4의 2번째 및 4번째 행에서 볼 수 있듯이, QA loss를 포함한 pre-train은 세 가지 데이터셋 모두에서 좋은 결과를 보여준다. NLVR2에서 2.1% 향상은 image QA pre-train으로 인해 더 강력한 표현을 학습했음을 보여준다. 이는 NLVR2의 모든 데이터(이미지와 문장)가 pre-training에 사용되지 않았기 때문이다.

Pre-training versus Data Augmentation
Data Augmentation(DA)은 여러 VQA 구현에서 사용되는 기술이다. 이는 다른 이미지 QA 데이터셋에서 질문을 추가하여 학습 데이터의 양을 증가시킨다. LXMERT 프레임워크는 대신 여러 QA 데이터셋을 pre-training에 사용하고 특정 데이터셋에만 fine-tuning을 한다. pre-training과 DA에 사용된 전체 데이터 양이 유사하기 때문에, 두 가지 전략을 공정하게 비교할 수 있다. 결과는 QA pre-training 방식이 DA보다 우수하다는 것을 보여준다. 먼저, pre-training에서 QA task를 제외하고 DA fine-tuning 결과를 보여준다. Table 4의 첫 번째 행에서 볼 수 있듯이, DA fine-tuning은 두 번째 행의 non-DA fine-tuning보다 결과가 낮다. 다음으로, QA pre-training을 한 후 DA를 사용하면(세 번째 행) DA가 결과를 다시 떨어뜨린다.
5.3 Effect of Vision Pre-training tasks
Table 5에서 다양한 vision pre-training task의 효과를 분석한다. pre-training에 vision task를 전혀 포함하지 않은 경우(i.e., language 및 cross-modality pre-training task만 사용한 경우), Table 5의 첫 번째 행에 표시된 것처럼 Table 3의 BERT+3 CrossAtt와 유사하다. 두 가지 visual pre-training task(i.e., RoI-feature regression and detected-label classification)는 각각 합리적인 결과를 얻을 수 있으며(두 번째와 세 번째 행), 이 두 가지 task들을 함께 pre-training하면 가장 높은 결과를 달성한다(네 번째 행).

5.4 Visualizing LXMERT Behavior
appendix에서 LXMERT의 동작을 시각화하여 language encoder, object-relationship encoder, cross-modality encoder에서의 attention 그래프를 각각 보여준다.
6. Related Work
Model Architecture
본 모델은 세 가지 아이디어 bi-directional attention, Transformer, BUTD와 밀접하게 관련되어 있다.
Pre-training
ELMo, GPT, BERT가 대규모 pre-train된 language model을 통해 언어 이해 task에서 개선을 보인 후, cross-modality pre-training에 대한 진전이 이루어졌다. 그러나 여전히 단일 transformer encoder와 BERT 스타일의 token 기반 pre-training에 기반을 두고 있으므로 본 논문은 cross-modality task의 필요를 충족시키기 위해 새로운 모델 아키텍처와 새로운 pre-training task를 개발했다.
Recent works since our EMNLP submission
본 논문의 버전은 2019년 5월 VQA 및 GQA challenge에 참여하는 데 사용되었다. EMNLP 제출 이후, 유사한 cross-modality pre-training 방향에 대한 유용한 모델 ViLBERT와 VisualBERT가 출시되었다. LXMERT 방법은 여러 면에서 이들과 다르다. cross-modality 모델에 대해 더 자세한 다중 구성 요소 설계(i.e., object-relationship encoder와 cross-modality layer 포함)를 사용하고 추가적으로 유용한 pre-training task(i.e., RoI-feature regression과 image question answering)를 채택한다. 이러한 차이점으로 인해 현재 최고의 성능을 기록하고 있다. VQA 2.0에서 1.5%의 정확도 차이와 NLVR2에서 9% 정확도 차이(consistency에서 15%)를 보인다. 또한, LXMERT는 90개 이상의 팀 중 VQA와 GQA 챌린지에서 모두 상위 3위 안에 드는 유일한 방법이다. 이러한 추가 pre-training task가 fine-tuning에 어떻게 기여하는지에 대한 자세한 분석을 section 5.2와 5.3에서 제공한다.
7. Conclusion
vision과 language 간의 연결을 학습하기 위한 cross-modality 프레임워크인 LXMERT를 제시했다. Transformer encoder와 새로운 cross-modality encoder 기반으로 모델을 구축했다. 그런 다음 이 모델을 image와 문장 쌍의 대규모 데이터셋에서 다양한 pre-training task들을 통해 pre-train했다. 경험적으로, 두 개의 image QA 데이터셋(VQA와 GQA)에서 SOTA 성능을 보여주었으며 visual reasoning 데이터셋인 NLVR2에서 22%의 개선을 통해 모델의 일반화를 입증했다. 또한, 상세한 분석과 ablation study를 통해 여러 모델 구성 요소와 학습 방법의 효과를 보여주었다.
Appendix
A. Evaluated Datasets Description
LXMERT 프레임워크를 평가하기 위해 세 가지 데이터셋을 사용한다.
VQA
visual question answering(VQA)의 목표는 이미지와 관련된 질문에 답하는 것이다. VQA v2.0 데이터셋을 사용하며 이는 VQA v1.0에 비해 답변 편향을 줄였다. 이 데이터셋은 이미지당 평균 5.4개의 질문을 포함하며 총 질문 수는 110만 개이다.
GQA
GQA는 VQA와 동일하게 단일 이미지 관련 질문에 답하는 것이다. 그러나 GQA는 더 많은 추론 능력(e.g., 공간적 이해와 다단계 추론)을 요구한다. 데이터셋의 2200만 개 질문은 질문의 질을 명확하게 제어하기 위해 실제 이미지 장면 그래프에서 생성된다.
NLVR2
이전 두 데이터셋은 pre-training에 사용되어 pre-training 데이터의 양을 일정 규모로 늘리는 데 기여했기 때문에, 모든 문장과 이미지가 pre-training에 포함되지 않은 또 다른 시각 추론 데이터셋인 NLVR2에서 LXMERT 프레임워크를 평가한다. NLVR2의 각 데이터는 두 개의 관련된 이미지를 포함하고 하나의 자연어 문장을 포함한다. 이 task는 문장이 이 두 이미지를 올바르게 설명하는지 여부를 예측하는 것이다. NLVR2는 training, development, test set 각각 86K, 7K, 7K 데이터를 포함하고 있다.
B. Details of NLVR2 Fine-tuning
NLVR2의 각 데이터는 두 이미지 쌍(img0, img1)과 하나의 문장 s, 문장이 두 이미지를 올바르게 설명하는지 여부를 나타내는 실제 라벨 y*로 구성된다. 이 task는 주어진 이미지와 문장을 기반으로 라벨 y를 예측하는 것이다.
LXMERT 모델을 NLVR2에 적용하기 위해, 두 이미지의 cross-modality 표현을 연결한 다음 GeLU 활성화를 사용하는 classifier를 구축한다. LXMERT가 단일 벡터 cross-modality 표현이라고 가정하면 예측 확률은 다음과 같이 계산된다.
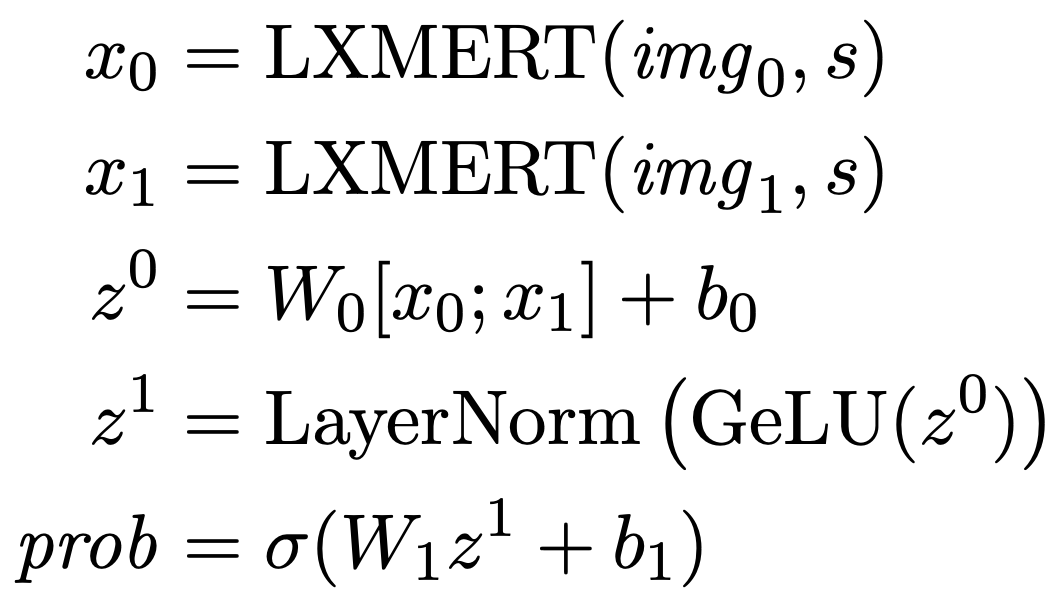
여기서 시그마는 시그모이드 함수이다. 모델은 log-likelihodd를 최대화하여 최적화되며 이는 binary cross entropy loss를 최소화하는 것과 동일하다.

이 식은 주어진 문장과 두 이미지 쌍이 올바르게 설명되는지 여부를 예측하기 위해 모델이 학습하는 방식을 설명한다.
C. Training, Validation, and Testing Splits
각 데이터셋을 신중하게 분할하여 모든 테스트 이미지가 pre-training이나 fine-tuning 단계에 포함되지 않도록 했다.
LXMERT Pre-Training
MS COCO에는 상대적으로 큰 검증 세트가 있으므로 MS COCO 검증 세트에서 5,000개의 이미지를 미니 검증 세트로 샘플링한다. 나머지 학습 및 검증 세트의 이미지들(i.e., COCO 학습 이미지와 미니 검증을 제외한 COCO 검증 이미지와 Visual Genome의 모든 이미지)은 pre-training에 사용된다. 비록 MS COCO 테스트 세트의 캡션과 질문이 이용 가능하지만, pre-training에서 테스트 이미지를 보지 않도록 하기 위해 이를 모두 제외한다.
Fine-tuning
VQA v2.0을 학습하고 검증하기 위해 LXMERT pre-training과 동일한 분할 규칙을 따른다. LXMERT 미니 검증 세트에 관련된 데이터는 모델 성능을 검증하는 데 사용되며 나머지 학습+검증 데이터는 fine-tuning에 사용된다. VQA v2.0 'test-dev'와 'test-standard' 분할에서 모델을 테스트한다. GQA fine-tuning을 위해 공식 GQA 지침에 따라 testdev를 검증 세트로 사용하고 학습+검증 세트를 합쳐 모델을 fine-tuning한다. GQA 'test-standard' 분할에서 GQA 모델을 테스트한다. NLVR2의 이미지는 MS COCO나 Visaul Genome에서 가져온 것이 아니므로 원래의 분할을 계속 사용한다. 학습 데이터에서 fine-tuning을 하고 검증 데이터로 모델 선택을 검증하고 공개 테스트('Test-P')와 비공개 테스트('Test-U')에서 테스트한다.
D. Training Details of 'BERT versus LXMERT'
BERT만을 사용하여 학습할 때, 각 실험을 배치 크기 64/128로 20 epoch동안 학습한다. 이는 BERT가 이러한 cross-modality 데이터셋에서 pre-train되지 않았기 때문이다. learning rate는 5e-5 대신 1e-4로 설정한다.
E. Visualizing LXMERT Behavior
이 section에서는 language encoder, object-relationship encoder, cross-modality enocder 각각 LXMERT의 동작을 시각화한다.
E.1 Language Encoder
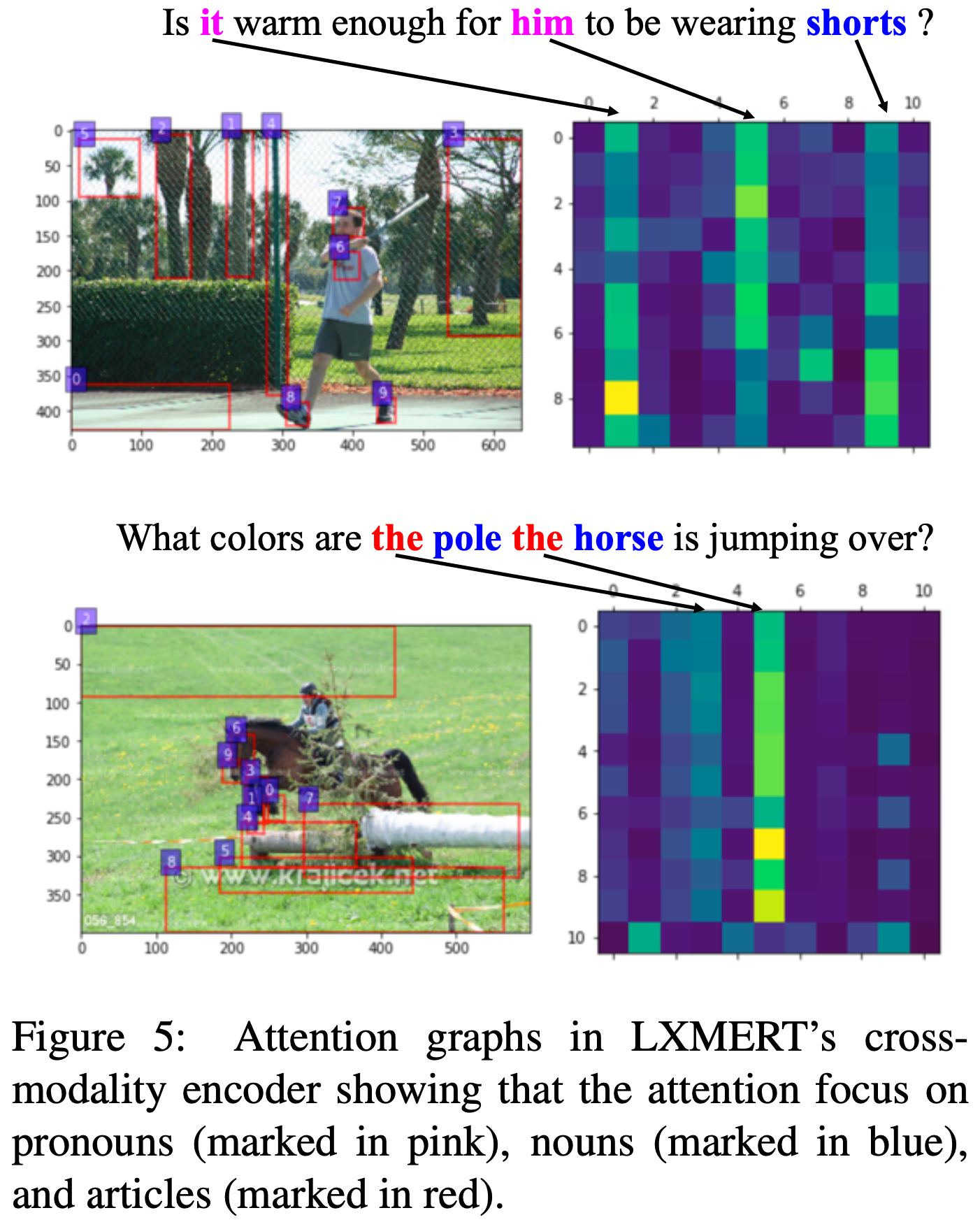
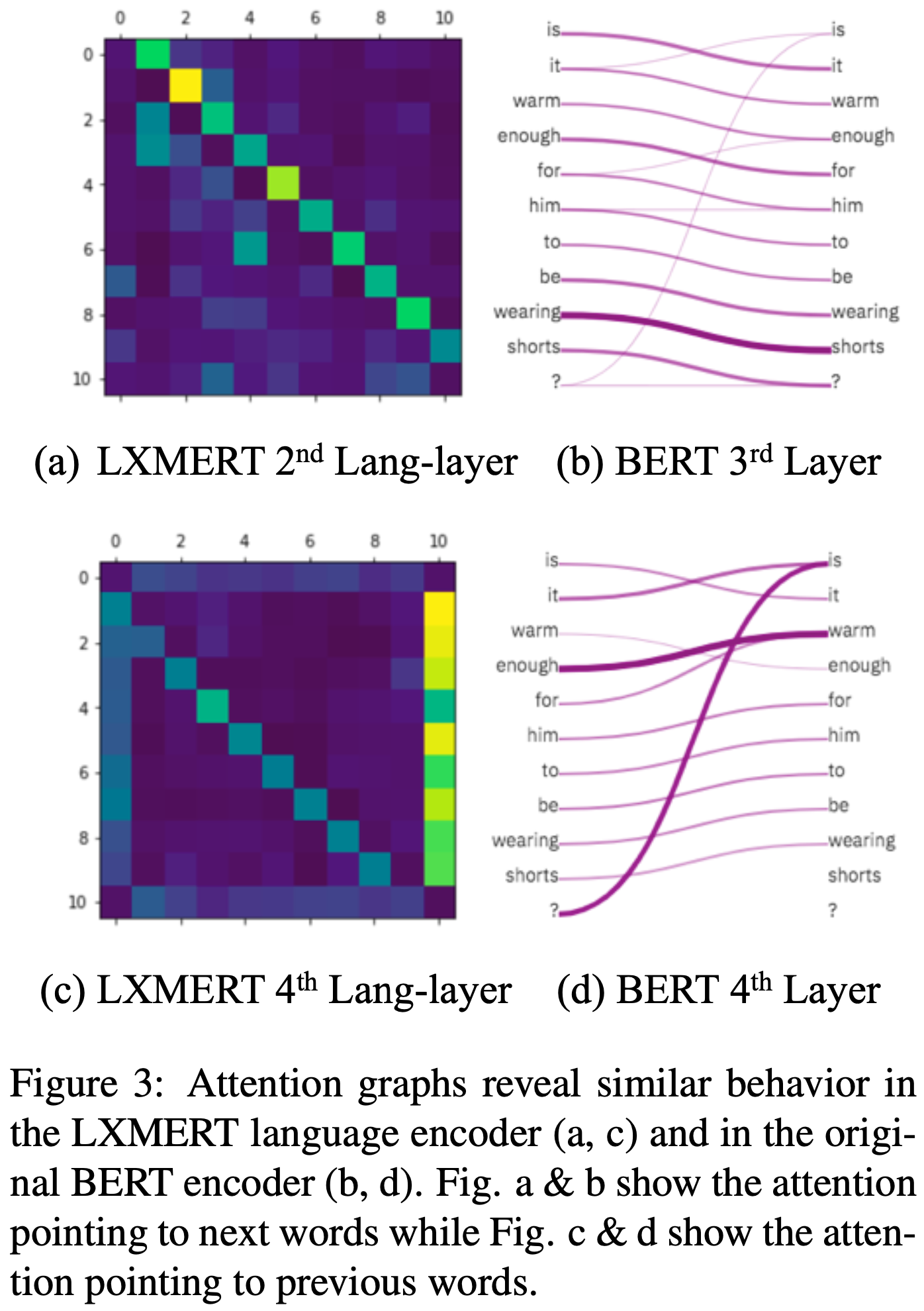
Figure 3에서 LXMERT language encoder가 원래 BERT encoder와 유사한 동작을 보인다는 것을 보여준다. 두 모델에 동일한 문장 "Is it warm enough for him to be wearing shorts?"를 입력으로 사용했다. LXMERT의 attention 그래프 (Figure 3(a,c))는 특정 task에 fine-tuning되지 않은 pre-train된 LXMERT에서 추출되었다. LXMERT의 두 번째 레이어(Figure 3(a))와 BERT의 세 번째 레이어(Figure 3(b))가 다음 단어를 가르키는 반면, LXMERT의 네 번째 레이어(Figure 3(c))와 BERT의 네 번째 레이어(Figure 3(d))가 이전 단어를 가리키는 것을 발견했다. 이는 두 encoder의 유사한 동작을 보여준다.
E.2 Object-Relationship Encoder
Figure 4에서 LXMERT의 object-relationship encoder의 첫 번째 레이어의 attention 그래프를 시각화했다. attention score가 가장 높은 object만을 강조 표시했으며 다른 object는 대부분 attend되지 않았다. attention 그래프에 따라 object간의 연결을 수동으로 구축했다(Figure 4(b)의 노란색 선으로 표시). 이러한 연결은 장면 그래프를 충실히 그리며 object간의 관계에 대해 상당히 좋은 네트워크를 학습하고 있음을 나타낸다.

E.3 Cross-Modality Encoder
Figure 5에서 object와 단어 사이의 연결을 밝히기 위해 LXMERT의 cross-modality encoder에서의 attention을 시각화했다. Figure 5의 상단 그림에서 알 수 있듯이, attention은 명사와 대명사에 집중되어 있다. 이는 현재 vision-and-language task에서 가장 정보가 많은 단어들이기 때문이다. 그러나 복수가 아닌 명사의 경우(Figure 5의 하단 예시), attention은 관사에 집중된다. 이러한 동작을 특별히 설계하지는 않았지만, 관사가 special 토큰(e.g., BERT의 [CLS], [SEP])처럼 작동하여 attention 레이어에 통합된 target 항목을 제공한다고 생각한다. 다음으로, 이미지와 텍스트 문장 사이의 명사-명사 및 명사-동사 관계를 직접적으로 캡처하는 pre-training task를 어떻게 활용할지에 대해서도 연구하고 있다.