이번 강의는 Neural Network와 Loss Function에 관해 학습한다.
Neural Network에서의 학습목표는 다음과 같다.
- Why is a Linear Classifier called a Linear Classifier?
- The problem of a Linear Classifier (Linear vs Non-linear)
- Neural Network
- Activation Function
저번 강의에서 했던 내용을 잠깐 복습하면 다음과 같다. 32x32x3 짜리 이미지가 있을 경우, linear classifier를 통해 세 가지 class에 대한 점수를 계산할 수 있었다.

이미지 데이터가 3차원이 아니라 숫자 하나라해도 그대로 세 가지 클래스에 대해서 점수가 나온다. 다만, 여기서는 일차방정식이 성립된다.
cat score = w0*x + b0
dog score = w1*x + b1
ship score = w2*x + b2

이미지 데이터가 두 개까지 늘어난다면? 바뀌는 부분은 가중치 행렬과 input x (노란색 부분)이다.
cat score = w00*x0+w10*x1+b0
dog score = w01*x0+w11*x1+b1
ship score = ...
input x 가 2x1 형태의 행렬이기 때문에 f(x,W) 결과가 아까와 다르다. 즉, x축이 두 개 생긴다.
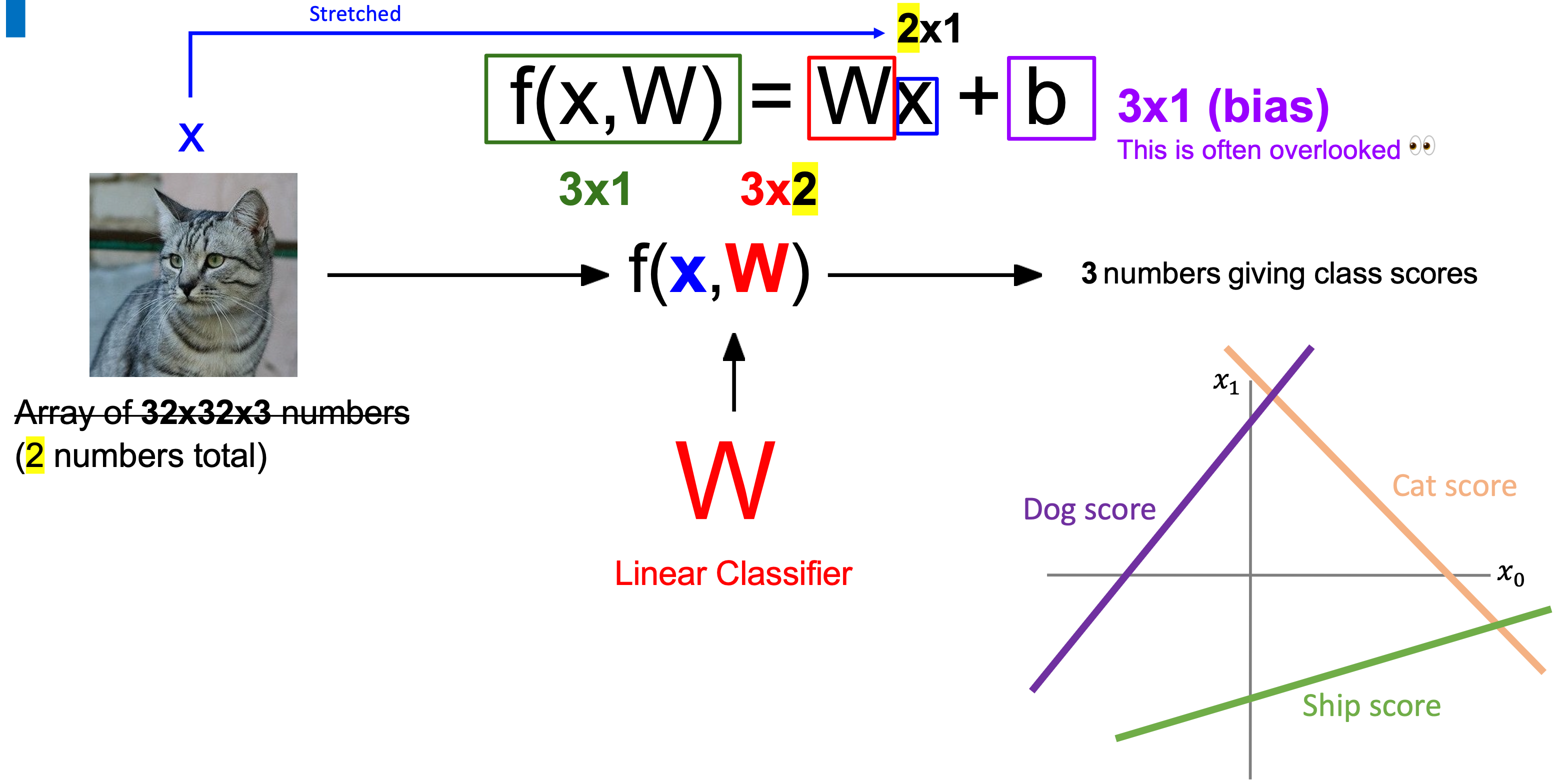
이미지 데이터가 3072로 늘어난다면 output f값과의 관계가 어떻게 변할까? 각 클래스마다의 구간이 생겨 각 구간에 따라 클래스를 나눌 수 있다.

근데 이걸 왜 Linear Classifier라고 부를까? 그 전에 Linear와 Non-Linear의 차이를 알아보자.
Linear
- the relationship between the input x and output y is proportional
- a stratight line
Non-linear
- a relationship where the change in output y is not proportional to the change in input x
- a curved line
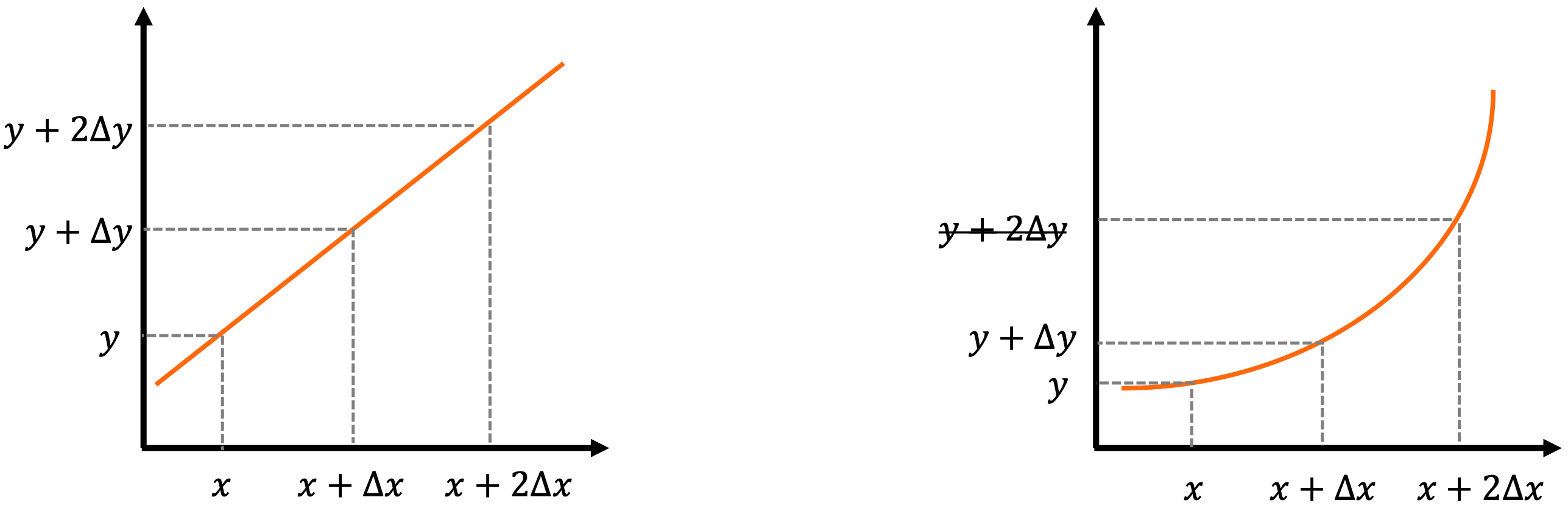
x의 증감에 따라 y의 변화량이 비례한 것을 linear하다고 한다. 따라서, 지금까지 봤던 결과들은 모두 linear하기 때문에 'Linear' Classifier라고 부른다.

하지만, Linear Classifier가 단순한 만큼 대부분의 경우에서 동작하지 않는다. 따라서, 더 복잡한 classifier가 필요하고 이는 non-linear classifier이다. Non-linear classifier가 등장하면서 Neural Network가 등장한다. Single layer network가 Linear classifier라고 생각할 수 있으며 Multi-layer network가 Non-linear layer를 설계하고 마지막에 linear classifier를 붙이는 형태로 구성된다.

그러면 Non-linear layer를 실행한 후, 마지막에 Linear classifier를 붙이면 대부분의 경우에서 동작할 수 있을까? Neural Network는 input data를 더 높은 차원의 공간으로 변환하는데 데이터가 linear classifier를 사용할 수 있을 만큼으로 변환하는 funtion을 학습한다. hidden layer가 많을수록 변곡점을 더 많이 생성할 수 있어 더 복잡한 decision boundary를 생성할 수 있다.

그러면 Neural Network에 Non-Linearity를 어떻게 포함시킬까? 이것은 Activation function이 해준다. 기존 Linear Classifier는 f=Wx였다면, Neural Network는 f=W*Activation_function(Wx)이다. Activation function이 왜 중간에 껴야될까? 행렬을 곱하는 과정에서 activation function을 넣지 않으면 단순하게 행렬이 되기때문에 결국 linear classifier이 된다.
f = W2*W1x에서 W3=W2*W1이라면 단순하게 아까 봤던것처럼 f=W3x가 되서 linear classifier가 되기 때문에 f = W2*Activation(W1x)를 거치게 만든다. 마지막에는 activation function을 붙이기 않기 때문에 마지막 레이어에서는 linear하다라고 한다.
그러면 Activation function은 뭘까? 대표적인 Activation function만 알아보면 다음과 같다. 엄청 유명한 Activation function만큼 식도 알아두자.!
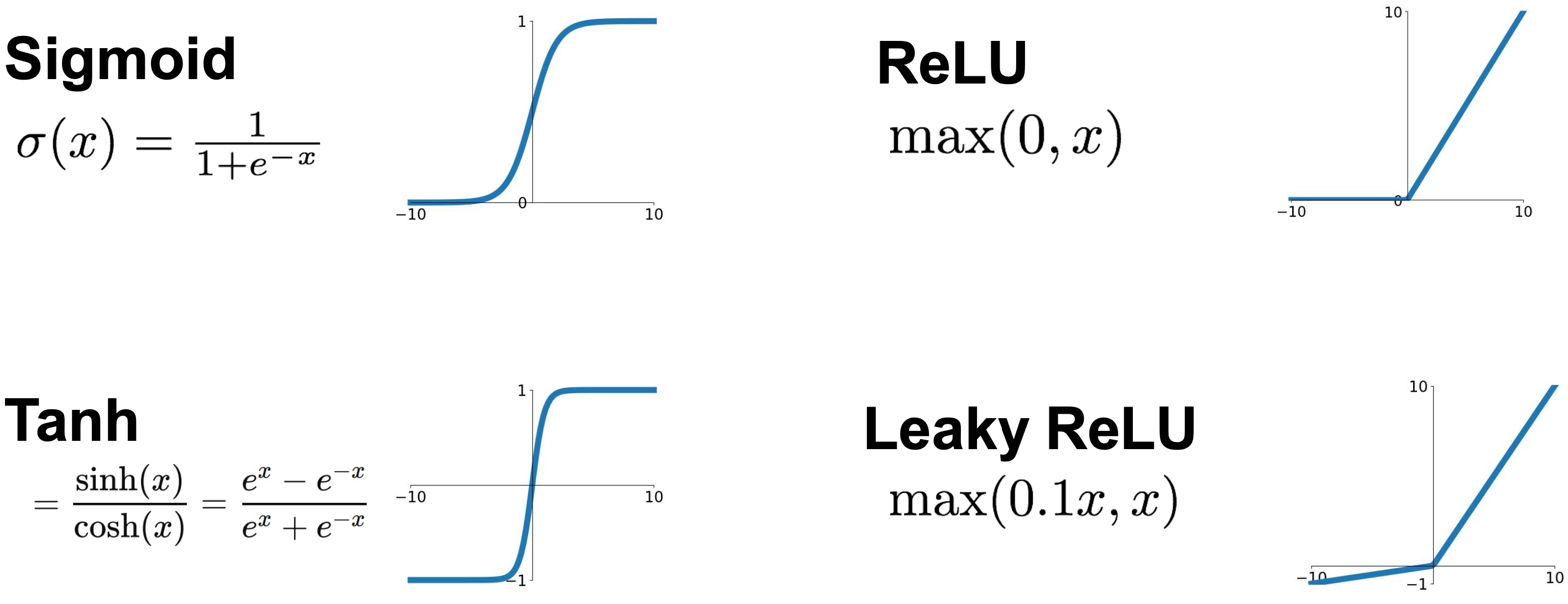
이제 Loss Function에 대해 학습한다.
Loss Function에서의 학습목표는 다음과 같다.
- What is a loss function?
- Hinge Loss
- Cross-Entropy Loss
그 전 챕터에서 W 가중치 행렬을 통해 output을 추출했는데 어떤 W 가중치 행렬이 좋은 것인가? 라는 의문이 생긴다.
How can we tell whether this W is good or bad?
여기서, Loss function이 등장한다. W가 얼마만큼 좋은지 수치화한 것이다.
여기서 또, 그 다음 강의에서 배울 Optimization이 등장한다. Optimization은 가장 loss를 최소화하는 최적의 W를 찾는 과정이다. 즉, learning이다.
Loss는 다음과 같이 정의할 수 있다. f(x,W)를 통해 나온 모델 예측값을 정답 레이블 y와 Loss function을 통해 loss 값을 계산하고 총 N개의 이미지에 대한 loss 값을 모두 더하여 N으로 나눈다.

Hinge Loss
Hinge Loss는 다음과 같이 정의된다.
조건문부터 보면, 정답 class score가 정답이 아닌 class score보다 1보다 크거나 같으면 loss 값은 0이다. 즉, (정답 class score) - (정답이 아닌 class score) 가 1보다 크거나 같으면 loss는 0이다. 음... 정답 class score가 정답이 아닌 class score보다 차이가 클수록 좋다고 생각하면 된다. 바로 뒤에 예제 있음.

다음과 같이 training image를 평가해보자.

cat score에 대한 loss 값은 다음과 같다. 정답이 아닌 class보다 정답인 class score가 높으면 좋은데 frog랑은 그렇지만 car랑은 아니다. car라고 판단할 확률이 더 높음. 즉, loss 값이 발생하며 loss 값은 2.9이다.



Total loss 는 (2.9 + 0.0 + 12.9) / 3 = 5.27이다.
Cross-Entropy Loss
Cross-Entropy Loss는 중요하며 Classification task에서 가장 널리 사용되는 loss이다. 좀 전까지는 각 클래스마다 score로 loss를 계산했는데 cross-entropy loss는 각 클래스마다의 score를 확률로 바꿔 계산한다. 확률은 softmax function을 이용해 계산한다(모든 클래스마다의 확률값의 합은 1이다). 각 클래스마다의 score를 지수함수를 취해주고 각 클래스마다의 지수함수 값을 모두 더해준 지수함수 값으로 나눈다. 그 후, 정답 레이블(Ground-truth label)과 비교한다. 정답 레이블은 정답 클래스를 1, 나머지를 0으로 원-핫 인코딩한다.

확률값과 정답 레이블과의 비교하는 방법은 다음과 같다. 각 클래스마다의 점수가 있을 때, 정답 레이블로 판단할 확률을 마이너스 log를 취한 것이다. 확률값은 위에서 모두 구했으니 마이너스 log만 취해주면 된다. 그러면 왜 마이너스 log를 취해주는 것일까?? 우리는 정답으로 판단할 확률이 100%가 되는 것을 원한다. 즉, 1로 가는 것을 목표로 한다. 마이너스 log를 취하면 정답 확률이 1일 때, loss 값이 가장 작아진다(0이 됨).

Cross Entropy vs Hinge Loss
Cross Entropy와 Hinge Loss와 비교하고자 다음과 같이 점수가 있다고 가정하자. 이럴 경우, Cross entropy loss 값은 생기지만, Hinge loss 값은 0이다.

그리고 score값을 조금만 변경하면 어떻게 될까? 예를 들어, 3을 3.1로 9를 8.9로 -100을 -99.9로 변경한다하면 Cross entropy loss 값은 변하지만 Hinge loss 값은 변하지 않는다.
정답 클래스에 대한 점수를 10에서 20으로 변하면 어떻게 될까? Hinge loss 값은 그대로 0이지만 Cross entropy loss 값은 score 값이 높아지므로 정답을 맞출 확률이 증가하여 loss 값은 작아질 것이다.
'Lectures > 딥러닝영상인식1' 카테고리의 다른 글
| [Lecture 6] Convolutional Neural Network & Training Neural Network (0) | 2024.12.16 |
|---|---|
| [Lecture 5] Convolutional Neural Network (CNN) (1) | 2024.10.21 |
| [Lecture 4] Convolution (1) | 2024.10.21 |
| [Lecture 3] Backpropagation (2) | 2024.10.20 |
| [Lecture 1] Image Classification and Classifiers (0) | 2024.09.06 |



