본 글은 https://arxiv.org/abs/2406.09403 내용을 기반으로 합니다. NeurIPS 2024에 accept된 논문입니다.
혹시 잘못된 부분이나 수정할 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
그리고 본 글은 computer vision task를 해결하는 method 위주로 작성합니다.
Abstract
현재 chain-of-thought 및 tool-use 패러다임은 중간 추론 스텝을 텍스트로만 처리한다. 본 연구에서는 MMLM에 visual SKETCHPAD와 이를 활용할 수 있는 도구를 제공하는 프레임워크인 SKETCHPAD를 소개한다. 이 모델은 스스로 그린 시각적 산물을 바탕으로 planning 및 reasoning을 수행한다. 기존의 text-to-image 모델을 활용해 모델이 이미지를 생성하게 하는 접근법과 달리, SKETCHPAD는 lines, boxes, marks 등으로 스케치를 가능하게 하며 이는 인간의 스케칭 방식에 더 가깝고 추론을 더욱 효과적으로 돕는다. SKETCHPAD는 스케치 과정에서 특화된 비전 모델(e.g., object detection 모델로 bounding box를 그리거나 segmentation 모델로 마스크를 생성)을 사용할 수도 있어 시각적 인식과 추론을 더욱 강화할 수 있다. 본 연구에서는 수학 문제와 복잡한 시각적 추론 작업을 대상으로 실험을 진행한다. 그 결과, 스케치를 사용하지 않은 강력한 기본 모델 대비 SKETCHPAD가 모든 task에서 성능을 크게 향상시켰으며 math task에서 평균 12.7%, vision task에서 평균 8.6%의 성능 향상을 보여주었다. 특히 SKETCHPAD를 사용하는 GPT-4o는 모든 task에서 SOTA 성능을 달성하였다.
1. Introduction
MMLM이 점차 발전하면서, 추론을 단순화하기 위해 중간 스케치를 그리는 task와 같은 과제를 해결할 수 있을 것으로 기대된다. 현재 인기 있는 벤치마크에는 기하학 문제나 복잡한 수학 문제와 같은 질문들이 포함되어 있다. 이러한 벤치마크에는 다이어그램 이미지를 모델에 제공하고 상징적 기반과 공간적 이해를 요구하는 질문을 한다. 이때, 보조선과 같은 중간 스케치를 활용하면 추론을 강화할 수 있다.
본 논문에서는 MMLM이 task를 추론하는 과정에서 중간 스케치를 생성할 수 있는 도구를 제공하는 프레임워크인 Visual SKETCHPAD를 소개한다. 텍스트 기반 언어 모델에서의 CoT 추론에서 영감을 받아, SKETCHPAD는 기본적인 시각 언어 모델이 텍스트, 프로그래밍적 접근, 시각적 추론이 혼합된 연쇄 과정의 일부로 시각적 산출물을 생성하도록 유도한다. 예를 들어, Figure 1(a)에서 삼각형의 내각의 합이 180도임을 증명하기 위해, SKETCHPAD는 agent가 새로운 보조선을 추가하여 다이어그램을 수정할 수 있도록 한다. 이 새로운 선과 추가된 각도 표기는 기하 문제를 해결하기 위한 핵심 정보를 제공한다. 마찬가지로, SKETCHPAD는 컴퓨터비전에서 모델의 공간적 추론 능력을 향상시킨다. 예를 들어, Figure 1(d)에서 쿠키가 다른 쿠키 위에 쌓여 있는지를 판단하기 위해 모델은 먼저 중간 깊이 추정을 생성한다. 이 깊이 추정을 분석하면 서로 다른 깊이에서 겹쳐진 쿠키들이 드러나며, 이를 통해 모델은 쿠키가 실제로 쌓여 있다는 올바른 답을 도출할 수 있다.
SKETCHPAD는 다양한 task를 해결하는 데 사용되었다. 기하학 문제의 경우, SKETCHPAD는 다이어그램 입력과 질문을 기반으로 보조선과 변수를 포함한 matplotlib 코드를 생성하도록 모델을 지원한다(Figure 1(a)). 특히, 입력이 단순히 언어 기반일 경우에도, SKETCHPAD는 함수 표현식을 입력으로 받아 해당 함수를 plot하고 그 특성을 추론할 수 있도록 지원한다(Figure 1(b)). 이러한 결과는 SKETCHPAD가 순수 언어 기반 입력에서도 추론을 도울 수 있음을 강조한다. 수학 task의 네 가지 카테고리에서 SKETCHPAD는 GPT-4o의 기본 성능을 꾸준히 개선하여 평균 11.2%의 성능 향상을 이루었다. 컴퓨터 비전의 경우, (1) 깊이, (2) 공간 추론, (3) 조각 맞추기, (4) 시각적 대응, (5) 의미론적 대응뿐만 아니라 (6) MMVP 및 (7) VBench 벤치마크에서의 문제를 포함한 다양한 task를 다룬다. SKETCHPAD는 모델이 세분화 마스크 생성, 이미지 자르기, 경계 상자 그리기, 이미지 영역 확대, 이미지 겹치게 하는 등을 수행할 수 있도록 지원한다. 수학 분야와 마찬가지로 SKETCHPAD는 컴퓨터 비전 task 7개에서 일관된 성능 향상을 보여준다. 예를 들어, SKETCHPAD로 강화된 GPT-4o는 VBench에서 14.3%의 성능 향상, BLINK의 깊이 및 의미론적 대응 task에서 각각 12.1%와 9.7%의 성능 향상을 기록하며 모든 task에서 SOTA 성능을 달성한다. 마지막으로, 모델이 생성한 plan과 사람이 작성한 plan을 비교하여 SKETCHPAD의 효과를 분석한 결과, 두 plan이 잘 정렬되어 있으며 유사한 추론 패턴을 보여주는 것을 확인했다. SKETCHPAD가 더 강력하고 해석 가능한 멀티모달 지능을 향한 새로운 연구 기회를 열기를 기대한다.

2. Related Work
SKETCHPAD는 멀티모달 도구 사용 및 시각적 프롬프트에 관한 최근 연구를 일반화한 것이다. 또한, 언어 모델을 agent로 탐구한다.
Visual programming and tool-use.
LMs의 발전에 따라, 연구자들은 복잡한 비전 작업을 간단한 하위 단계로 분해한 뒤 각각을 비전 도구를 사용하여 해결하는 가능성을 입증했다. 이 중 가장 관련 있는 연구는 Visprog와 ViperGPT이다. 이들은 LMs를 사용해 Python 코드를 생성하고 이를 통해 특화된 비전 도구를 순차적으로 호출한다. 이러한 방법들은 공통적으로 멀티모달 모듈이 LM이 미리 정의한 계획을 따르는 문제를 가지고 있다. 이에 비해, SKETCHPAD는 중간 시각적 인공물에 따라 plan을 변경할 수 있어 복잡한 멀티모달 task를 해결할 때 성능과 robust가 향상된다.
Visual prompting.
최근 연구는 이미지에 시각적 프롬프트를 추가하면 멀티모달 모델을 보강할 수 있음을 보여준다. 예를 들어, SoM은 이미지에 라벨링된 세분화 마스크를 추가하면 GPT-4V의 visual grounding 능력을 끌어낼 수 있음을 증명했다. SKETCHPAD는 이러한 방법들을 일반화한 프레임워크로, LMs가 멀티모달 추론 과정에서 사용할 시각적 프롬프팅을 스스로 결정할 수 있게 한다.
LMs as agents.
최근 연구는 LMs를 추론과 행동을 모두 수행할 수 있는 agent로 간주하기 시작했다. SKETCHPAD는 멀티모달 입력과 출력을 수용하는 agent로 볼 수 있다. 주요 차이점은 SKETCHPAD가 추론을 용이하게 하기 위해 시각적 인공물을 생성할 수 있다는 점이다. 반면, 기존 LM agent는 추론 중 텍스트만 생성한다.
3. Visual SKETCHPAD
Visual SKETCHPAD를 소개한다. 이는 MMLM이 추론 과정의 중간 단계로 스케치를 생성하고 이를 활용하여 추가적인 추론을 지원할 수 있는 프레임워크이다. Figure 2는 SKETCHPAD의 작동 방식을 보여준다. 멀티모달 쿼리가 주어지면, SKETCHPAD agent는 쿼리를 해결하기 위한 스케치 계획(Thought)를 생성한 후, 시각적 스케치를 생성하는 프로그램(Action)을 작성한다. 이후 생성된 스케치(Observation)을 분석하여 이를 추론 과정의 시각적 표현으로 활용하고 최종적으로 쿼리에 대한 응답을 생성한다.
이 프레임워크는 추가적인 파인튜닝이나 학습이 필요하지 않으며, MMLM은 별도의 수정 없이 SKETCHPAD 프레임워크를 통해 스케치를 생성하도록 프롬프트될 수 있다.
3.1 Overview of SKETCHPAD
멀티모달 쿼리가 주어지면, 쿼리에 답하는 데 필요한 정보를 수집하기 위해 일련의 thoughts, actions, observations 단계를 거친다. 각 시간 단계 t에서 모델은 다음의 세 가지 핵심 단계를 수행한다.
Thought.
모델은 현재 context c를 분석하여 다음 행동을 위한 p를 생성한다. context에는 쿼리, 이전 thought, action, observation이 포함된다. 예를 들어, Figure 2(a)의 쿼리 q가 "EIC 각도를 찾아라"라면, 모델의 첫 번째 생각 plan p는 보조선 IX를 BD와 평행하게 그려 문제를 해결하는 데 도움을 주는 visual sketch를 만드는 것이다.
Action.
모델은 thought plan 기반으로 시각적 및 텍스트 콘텐츠를 조작할 수 있는 action a를 실행한다. 예를 들어, 보조선을 그리겠다는 thought를 실현하기 위해 모델은 원래의 기하 도형 다이어그램을 수정하는 python 코드를 생성한다. 생성된 코드는 컴파일 및 실행된다.
Observation.
action a에 따라, SKETCHPAD의 환경은 새로운 observation o를 반환한다. 기하학 예제에서는 보조선을 그려진 새로운 다이어그램이 반환된다. 이후 멀티모달 context는 (c,p,a,o)로 업데이트된다.
이러한 멀티모달 상호작용 과정은 모델이 context c에서 쿼리에 답하는 데 충분한 정보를 수집했다고 판단할 때까지 계속된다. 이 시점에서 모델은 특별한 Terminate action (종료 행동)을 생성하고 답을 제공한다.
기존 연구에서는 LMs가 주로 텍스트 기반의 observation 및 action을 생성하고 조작한 반면, SKETCHPAD는 모델이 멀티모달 관찰 o와 행동 a를 처리하며, 시각적 및 텍스트적 콘텐츠를 모두 조작할 수 있도록 한다. 이를 통해 모델은 스스로 그린 visual sketch를 활용해 계획하고 추론할 수 있으며 문제 해결 능력을 향상시킨다.
3.2 Sketching via Code Generation
SKETCHPAD의 핵심 구성 요소는 스케치 기능으로 이를 통해 언어 모델이 다양한 전문 비전 모델이나 python plotting 패키지를 호출하는 프로그램을 생성하여 visual sketch를 생성할 수 있다.
Program Generation.
ViperGPT 및 VPD와 같은 최근 연구와 유사하게, SKETCHPAD는 코드 생성을 통해 스케치를 수행할 수 있다. 언어 모델은 프롬프트를 통해 멀티모달 콘텐츠를 생성할 수 있는 도구들에 대한 상세 설명을 제공한다(예제 프롬프트와 설명은 $C에 나와 있음). 모델은 제공된 도구를 사용해 코드 블록 내에서 python 코드를 생성한다. 코드를 실행하면 새로운 이미지와 텍스트 출력을 생성한다. display 함수는 생성된 스케치 이미지를 다음 observation 단계에서 시각화할 수 있도록 한다.
Modules for sketching.
SKETCHPAD는 task에 따라 다양한 도구를 활용하여 스케치 과정을 지원한다. 수학 task의 경우, SKETCHPAD는 matplotlib,networkX와 같은 일반적인 python 패키지를 사용하여 plotting 작업을 수행한다. vision task의 경우, SKETCHPAD는 스케치 과정에서 전문 비전 모델을 활용한다. 이러한 모델에는 bounding box를 그리는 detection 도구, 색상 마스크를 그리는 세분화 및 표시 도구가 포함된다. 각 세분화 마스크는 숫자 레이블로 라벨링되어 있다. 이러한 도구들은 시각적 추론 task에서 유용한 인식 능력을 제공한다. SKETCHPAD는 이러한 도구를 멀티모달 언어 모델에 효과적으로 통합함으로써 모델의 문제 해결 및 추론 능력을 크게 향상시킨다.
5. Sketching to Solve Computer Vision Tasks
복잡한 visual reasoning task에서 SKETCHPAD를 실험한다. BLINK 연구는 MMLM이 많은 핵심적인 시각적 인식 능력을여전히 결여하고 있다는 점을 지적했다. SoM 연구는 이미지 위에 세분화 마스크를 그리는 task가 GPT-4V의 강력한 시각적 기반 능력을 발휘하게 한다고 밝혔다. SKETCHPAD는 이러한 아이디어를 일반화하여 LMs가 전문 비전 모델을 사용해 스케치를 생성할 수 있도록 한다. 모듈의 세부 사항은 $5.1에서 다루며, SKETCHPAD가 MMLM의 시각적 추론 능력을 향상시키고 7개 task에서 SOTA 성능을 보여준다.
Tasks.
(1) V*Bench: 이미지 내 작은 물체에 관한 질문을 포함. (2) MMVP benchmark: CLIP 기반 MMLM의 시각적 한계를 드러내기 위해 특별히 설계된 시각적 질문을 포함. (3) BLINK benchmark: 인간에게는 쉬운 시각적 인식 task이지만, MMLM에는 큰 도전 과제가 되는 task를 포함.(상대적 기핑, 공간적 추론, 퍼즐 조합, 시각적 대응, 의미적 대응)
5.1 Vision Specialists as Sketching Tools in SKETCHPAD
LMs는 다음과 같은 모듈을 사용하여 이미지를 스케치하고 조작할 수 있다. 이러한 모듈은 LM이 호출할 수 있도록 python 함수로 감싼다. 함수 정의는 $C를 참조하면 된다.
Detection.
이 모듈은 이미지를 입력으로 받고 간단한 텍스트 쿼리(e.x. "cat")을 처리한다. Grounding-DINO open vocabulary object detection 모델을 실행하여, 탐지된 객체의 bounding box(숫자 레이블 포함)을 이미지에 plot한다. 또한, bounding box의 좌표를 반환한다.
Segmentation.
이 모듈은 이미지를 입력으로 받아 색상 세분화 마스크가 적용된 이미지를 반환한다. 각 마스크에는 숫자 레이블이 부여된다. SoM 구현을 따르며, 기본 세분화 모델로는 SegmentAnything 및 Semantic-SAM을 사용한다.
Depth estimation.
이 모듈은 이미지를 입력으로 받아 depth map을 반환한다. 기본 모델로는 DepthAnything을 사용한다.
Visual search via sliding window.
이 모듈은 인간이 이미지에서 작은 물체를 찾는 방식을 모방한다. 텍스트 쿼리를 입력으로 받아, 이미지를 슬라이딩 윈도우 방식으로 검색한다. 윈도우 크기는 이미지 크기의 1/3. 스텝 크기는 이미지 크기의 2/9. 결과적으로 이미지는 4x4=16개의 윈도우를 가진다. 쿼리가 탐지된 이미지 패치들의 시퀀스를 반환한다.
Other image manipulation modules.
zoom-in and crop. 이미지를 입력으로 받고 bounding box를 기반으로 해당 박스 내부의 이미지 패치를 반환한다. overlap images. 두 개의 이미지와 알파 값을 입력으로 받아, 오버랩된 이미지를 반환한다.
5.2 Results
SKETCHPAD를 사용할 경우와 사용하지 않을 경우의 성능을 비교했으며, Gemini, Claude 3, open source model LLaVA 1.5, LLaVA-NeXT와 같은 MMLM과도 비교했다.
Main results. Table 2는 SKETCHPAD와 비교 대상 모델의 성능을 보여준다. SKETCHPAD는 모든 task에서 기본 모델의 성능을 꾸준히 향상시켰다. V*Bench에서 SKETCHPAD는 특히 효과적이였으며, GPT-4 Turbo는 18.5%의 정확도 향상을, GPT-4o는 14.3%의 정확도 향상을 기록했다. 이는 이 task를 위해 특화된 시각 검색 모델을 사용했던 이전 SOTA 모델인 SEAL을 능가한 결과이다.
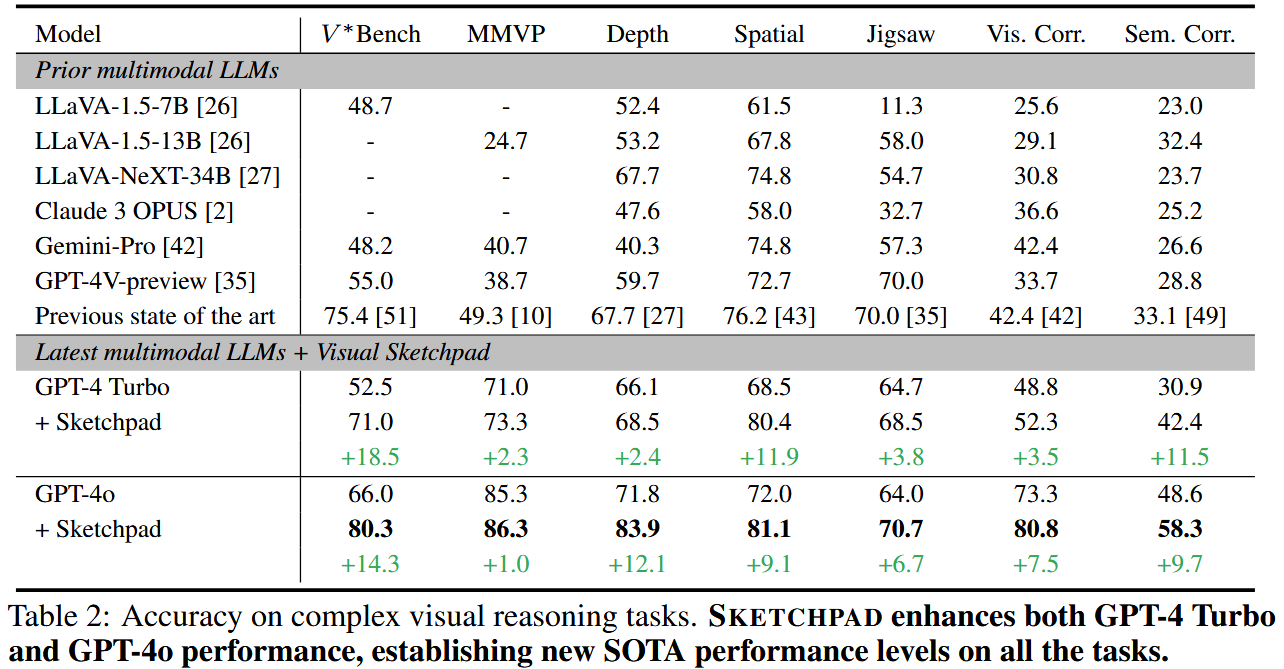
How many times is each vision specialist used?
각 비전 전문가 모듈이 얼마나 자주 사용되는지 확인하기 위해, Figure 4에 나타난 바와 같이 각 task에서 모듈이 사용된 횟수를 계산했다. 여기서는 가장 큰 성능 향상을 보인 네 가지 task(V*Bench, 상대적 깊이, 공간 추론, 의미적 대응)을 분석 대상으로 선택했다.
(1) the use of vision specialist is task-dependent, and the two LMs analyzed utilize similar tools.
비전 전문가의 사용은 task에 따라 다르다. 분석된 두 모델(GPT-4 Turbo와 GPT-4o)는 유사한 도구를 활용했다.
(2) GPT-4o likes to use more tools.
GPT-4o는 GPT-4 Turbo보다 비전 전문가 모듈을 더 자주 사용한다. 두 모델은 의미적 대응 task에서 다른 행동을 보였다.
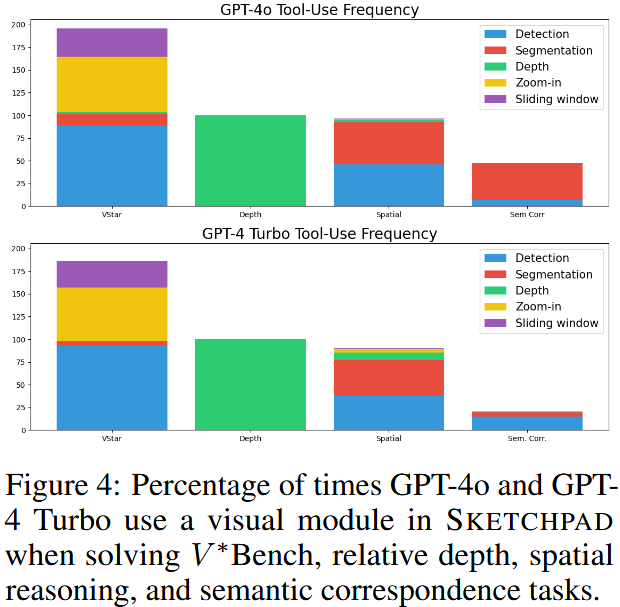
Comparison with visual prompting and tool-use frameworks.
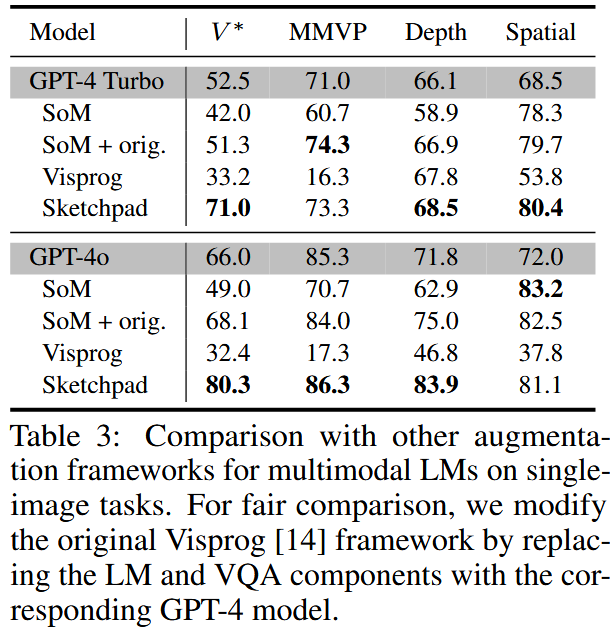
Table 3에서는 SKETCHPAD를 visual prompting 프레임워크인 SoM과 LLM 도구 사용 프레임워크인 Visprog와 비교한다.
6. Analysis and Discussion
Why does SKETCHPAD work? (왜 SKETCHPAD가 효과적인가?)
시각적 정보는 언어를 보완하는 다목적 인터페이스로 깊이 추정이나 세분화 같은 밀집된 정보는 언어로 쉽게 표현하기 어렵다.
중간 시각적 산출물을 기반으로 한 계획 및 추론을 통해, SKETCHPAD에서는 MMLM이 스스로 생성한 중간 시각적 산출물을 바탕으로 계획을 세우고 추론할 수 있다.
인간과 유사한 계획을 세움으로써 LMs가 비슷한 추론 패턴을 가진 데이터를 학습한 덕분에 이점을 얻을 가능성이 높다.
Do LMs have the same plans as humans? (LMs의 계획은 인간과 같은가?)
기하학 문제에서는 인간이 GPT-4o와 동일한 보조선을 80%의 경우에 그렸다.
비전 task에서는 인간 참가자 2명에게 GPT-4o의 전체 계획을 보여주고 해당 계획의 타당성을 평가하도록 했다. 인간 평가에서 GPT-4o의 계획은 92.8%의 경우 유효하다고 평가받았다. 대부분의 오류는 계획 자체의 문제가 아니라, 비전 전문가(ex. 객체 탐지 실패)나 간단한 VQA의 실수로 인해 발생했다.
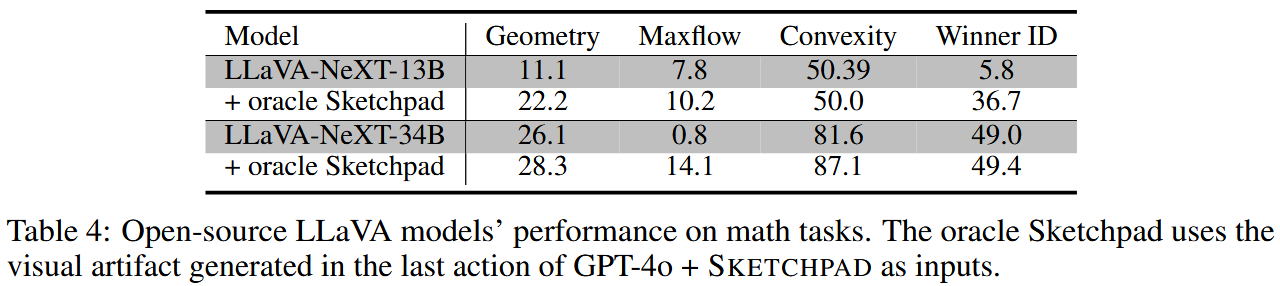
Experiments on open-source models. (오픈 소스 모델에 대한 실험)
스케치(다이어그램, 플롯, 보조선 등)이 기존 오픈 소스 MMLM을 지원할 수 있는가? 이 질문에 답하기 위해 Table 4의 실험을 수행했다. GPT-4o + SKETCHPAD 실험에서 마지막 행동으로 생성된 시각적 산출물을 LLaVA-NeXT 모델의 이미지 입력으로 사용했다. SKETCHPAD는 수학 task에서 일관된 성능 향상을 가져왔으며, 수학적 추론 능력을 크게 향상시켰다.
7. Conclusion
Visual SKETCHPAD는 MMLM이 task를 추론하는 과정에서 중간 스케치를 생성할 수 있는 도구를 제공하는 프레임워크이다. 복잡한 수학적 추론 task에서는 보조선, 수학 함수, 그래프, 게임 등을 시각화하여 큰 성능 향상을 이뤄냈다. visual reasoning task에서는 SKETCHPAD에 비전 전문가 모듈을 추가했다. 언어 모델은 추론 중에 이러한 전문가를 호출하여, 이들의 예측 시각화(ex. 객체 탐지 모델의 bounding box, segmentation 모델의 마스크)를 관찰한 후, 추가적인 계획 및 추론을 수행할 수 있다. 실험 결과, SKETCHPAD는 모든 task에서 LMs의 성능을 향상시키고 SOTA 성능을 달성했다. SKETCHPAD는 언어와 시각의 상호 보완적인 강점을 활용하여 점점 더 복잡해지는 추론 과제를 해결할 수 있는 인간과 유사한 다중 모달 지능을 LM에 부여하는 방향으로 한 걸음 더 나아간 프레임워크이다.
Limitations and future directions.
1. 컴퓨팅 자원 요구.
SKETCHPAD는 언어 토큰만 직접 출력하는 것보다 더 많은 컴퓨팅 자원이 필요하다. 컴퓨팅 비용에 대한 논의는 Section E에 있다.
2. 기존 모델에 초점
본 연구는 기존 off-the-shelf LMs에 초점을 맞추고 있다. 향후 연구는 SKETCHPAD의 학습 측면을 탐구할 수 있다. 최신 MMLM은 본래 멀티모달성을 갖추고 있어 텍스트와 이미지를 모두 출력할 수 있다. 텍스트와 이미 SKETCHPAD는 이러한 모델의 instruction tuning을 위한 새로운 패러다임으로 떠오를 가능성이 있다.
3. 다양한 응용 분야로의 확장
더 많은 분야(ex. robotics)에 적용될 수 있다.
Appendix C. Prompts
V*Bench의 visual search 문제를 해결하기 위해 GPT-4o + SKETCHPAD가 실행한 로그를 제공한다. 본 연구에서는 모든 컴퓨터 비전 문제에 동일한 프롬프트 템플릿을 사용한다. 시각화를 위해, 코드가 포함된 프롬프트는 별도로 표시하지만, 실제 구현에서는 모두 LLM에 텍스트 입력을 제공된다.

Initial Prompt + Request
Here are some tools that can help you. All are python codes. They are in tools .py and will be imported for you.
The images has their own coordinate system. The upper left corner of the image is the origin (0, 0). All coordinates are normalized, i.e., the range is [0, 1].
All bounding boxes are in the formate of [x, y, w, h], which is a python list . x is the horizontal coordinate of the upper-left corner of the box, y is the vertical coordinate of that corner, w is the box width, and h is the box height.
Notice that you, as an AI assistant, is not good at locating things and describe them with coordinate. You can use tools to generate bounding boxes.
You are also not good at answering questions about small visual details in the image. You can use tools to zoom in on the image to see the details. Below are the tools in the tools .py:
"""python
class AnnotatedImage:
# A class to represent an annotated image. It contains the annotated image and the original image.
def __init__(self, annotated_image: Image.Image, original_image: Image.Image=None):
self.annotated_image = annotated_image
self.original_image = original_image
def detection(image, objects):
'''
Grounding DINO 모델을 사용하여 객체 탐지 수행.
input은 이미지와 탐지할 간단한 객체 이름(ex. "bus", "red car").
output은 Annotated Image(bounding box와 주석이 추가된 이미지)와 탐지된 객체의 bounding box list.
제한 사항은 탐지가 완벽하지 않으므로, 결과를 참고 자료로만 사용하고 이중 확인이 필요.
'''
def sliding_window_detection(image, objects):
'''
작은 물체가 탐지되지 않을 경우, 슬라이딩 윈도우 방식으로 탐색 수행.
input은 이미지와 탐지할 간단한 객체 이름.
output은 zoomed-in 이미지 패치 리스트와 각 패치에서 탐지된 객체의 bounding box list.
'''
def segment_and_mark(image, anno_mode:list=['Mask', 'Mark']):
'''
segmentation 모델을 사용하여 이미지 분할 및 마스크 추가.
각 분할 영역은 색상 마스크와 번호 레이블로 표시.
'''
def depth(image):
'''
DepthAnything 모델을 사용하여 input 이미지의 Depth Map 생성.
물체의 거리 정보를 색상으로 시각화.
가까운 물체는 따뜻한 색상. 먼 물체는 차가운 색상.
'''
def zoom_in_image_by_bbox(image, box, padding=0.05):
'''
탐지된 bounding box를 기반으로 이미지를 확대하여 세부정보 확인.
input은 이미지, bounding box, 확대 시 padding.
output은 확대된 이미지.
'''
def overlay_images(background_img, overlay_img, alpha=0.3, bounding_box=[0,0,1,1]):
'''
두 이미지를 overlay하여 결합.
원본 이미지에 Depth Map이나 heatmap을 겹쳐 시각적 관계를 명확히 표시.
'''
각 도구는 단계별로 작업을 지원하며, 이전 단계의 결과를 기반으로 다음 작업을 진행.
예를 들어, detection으로 객체 탐지 후, 탐지된 객체를 zoom_in_image_by_bbox로 확대하고 depth로 공간적 관계를 분석.



