본 글은 https://arxiv.org/abs/2410.03176 내용을 기반으로 합니다. 본 논문은 EMNLP 2024에서 소개되었습니다.
혹시 잘못된 부분이나 수정할 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
Abstract
Large Vision-Language Models (LVLMs)는 인상적인 성능을 달성했지만, 연구에 따르면 이러한 모델에서 object hallucination이라는 심각한 문제가 지적되고 있다. 그러나, 이러한 hallucination이 모델의 어느 부분에서 비롯되는지에 대한 명확한 결론이 없다. 본 논문에서는 많은 SOTA vision-language system의 기반이 되는 CLIP 모델에서 object hallucination 문제에 대한 심층적인 조사를 제시한다. CLIP 모델이 독립적으로 사용될 때조차도 object hallucination에 취약하다는 사실을 밝혀내었으며, 이는 hallucination 문제가 vision과 language 모달리티 간의 상호작용에만 기인하는 것이 아님을 시사한다. 이를 해결하기 위해, 다양한 hallucination 문제를 포함한 negative sample을 생성함으로써 반사실적 데이터 증강 방법을 제안한다. 본 논문에서 제안한 방법이 CLIP 모델에서 object hallucination을 효과적으로 완화할 수 있음을 입증하고 개선된 모델이 visual encoder로 활용되어 LVLM에서 object hallucination 문제를 효과적으로 완화할 수 있음을 보여준다.
* 반사실적 데이터 증강(Counterfactual Data Augmentation) : "counterfactual"는 "사실과 반대되는"이라는 의미로 데이터에서 어떤 특정 속성을 변경하여 그 속성이 달랐을 경우를 가정한 데이터를 생성하는 것을 의미. 즉, 반사실적 데이터 증강은 원본 데이터의 일부 속성을 조작하여 있었을 법한 데이터를 생성함으로써 모델이 특정 패턴이나 편향에 의존하지 않도록 도움.
1. Introduction
현재 LVLM은 image captioning, visual question answering, visual grounding, autonomous agents와 같은 시각적 및 언어적 인지가 필요한 task에서 상당한 잠재력을 보여주고 있다. LVLM의 성공에도 불구하고 이전 연구들은 이러한 모델이 실제 사용에서 object hallucination, spatial hallucination, attribute hallucination 등과 같은 hallucination 문제를 흔히 겪는다는 것을 밝혀냈다. hallucination 문제는 모델의 성능과 신뢰성을 저하시킬 뿐만 아니라, 실제 응용에서 사용자 경험을 심각하게 저해한다고 널리 인식되고 있다.
* visual grounding : 텍스트로 설명된 객체를 이미지에서 식별하는 task
* autonomous agents : 주어진 환경에서 스스로 의사 결정을 내리고 목표를 수행하며 task를 처리할 수 있는 인공지능 시스템
본 연구에서, 크게 우려되는 object hallucination의 원인을 조사하는 것에 중점을 두었으며, 즉 object hallucination은 LVLM이 이미지에 존재하지 않는 object를 생성하는 현상을 의미한다. 일반적인 LVLM은 LLM을 cognitive foundational model로 사용하며, 사전학습된 image encoder (주로 CLIP encoder)를 시각적 인식 모듈로 활용한다. Kamath et al. (2023)은 LVLM에서 발생하는 spatial hallucination(예: "왼쪽에"와 "오른쪽에"를 혼동하는 현상)을 조사했으며, 다양한 CLIP 인코더가 단순한 공간적 관계를 인식하는 데 어려움을 겪는다는 사실을 발견했다(벤치마크에서 55.0%의 정확도를 기록한 반면, 인간은 98.8%를 기록). 그들의 발견에 영감받아, CLIP visual encoder가 object hallucination의 원인 중 하나일 수도 있다는 가설을 세웠다.
* cognitive foundational model : 지능적인 사고, 추론, 이해와 같은 인지적 기능을 수행하기 위한 기반이 되는 핵심 모델을 의미.
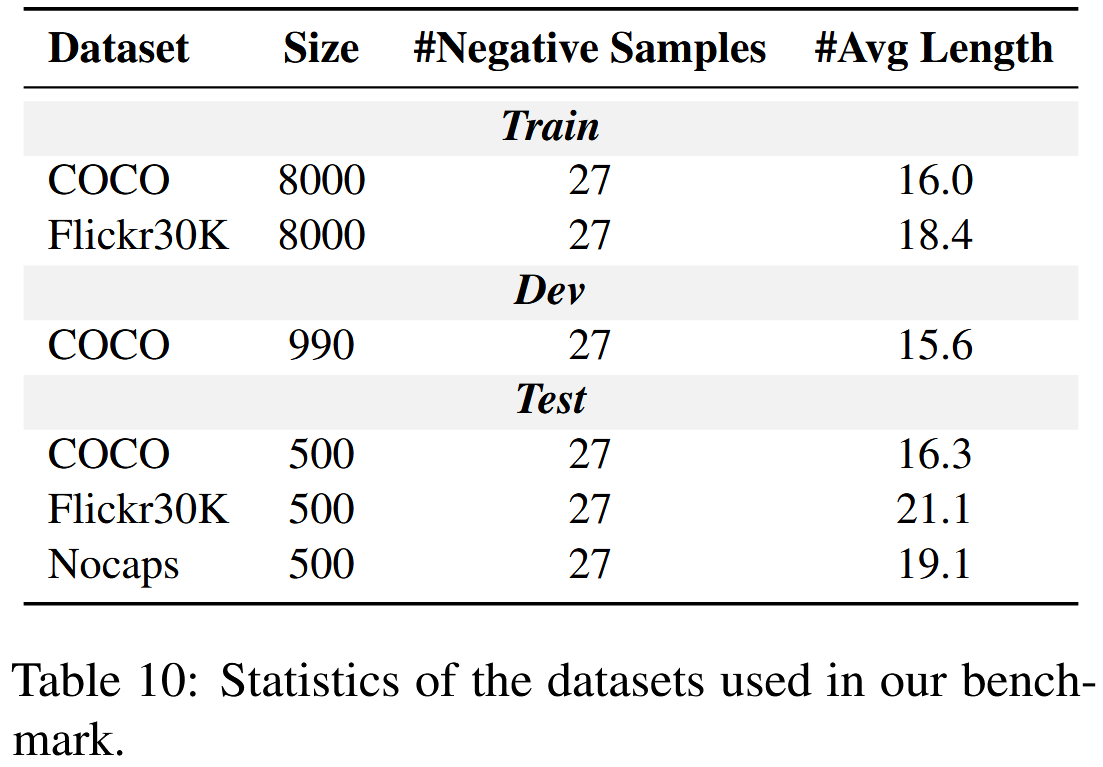
따라서, CLIP encoder에서 나타나는 object hallucination의 정도를 보다 엄격하게 측정하기 위해 COCO, Flickr30K 및 Nocaps(보이지 않은 객체를 포함하기 때문에 out-of-domain 벤치마크로 사용) image caption dataset의 하위 집합으로부터 Object Hallucination Detection (OHD-Caps) 벤치마크를 우선적으로 구축하였다. 16k/1k/1.5k (train/dev/test) 샘플을 무작위로 선택하며, 각 샘플은 하나의 이미지, 하나의 positive descriptive text, 27개의 negative descriptive text를 포함한다. negative sample은 positive sample의 변형으로, 존재하지 않는 object를 묘사하거나 기존 object의 묘사를 줄이는 방식으로 생성된다. 이론적으로, object hallucination이 없는 CLIP 모델은 positive sample에 가장 높은 CLIP 점수를 정확히 할당해야 한다. 그러나, LVLM에서 가장 흔히 사용되는 "CLIP ViT-L/14"를 예로 들면, positive sample에 가장 높은 점수를 부여하는 경우는 단 19.0%에 불과하다. CLIP encoder가 이미 심각한 object hallucination을 가지고 있다는 것을 관찰했으니, 이를 어떻게 완화할 수 있을까?
CLIP의 contrastive pretraining에서, negative sample이 배치 내에서 다른 이미지들의 텍스트 설명에서 생성되며, 이로 인해 negative sample과의 구분이 비교적 간단해진다. 그러나, object hallucination을 완화하려면 CLIP encoder는 object 수준에서의 미묘한 오류를 구분할 수 있어야 한다. OHD-Caps의 training set을 사용하여 CLIP 모델을 추가적으로 파인튜닝한다. fine-grained object-level contrastive loss를 도입함으로써, CLIP에서 object hallucination을 크게 감소시킬 수 있었다. 그 후, 파인튜닝된 CLIP을 visual encoder로 사용함으로써 재학습된 LVLM인 LLaVA-1.5에서도 object hallucination이 감소하였다.
본 논문에서, CLIP 모델의 object hallucination을 연구하며 main contribution은 다음과 같다.
- CLIP 모델에서 object hallucination을 평가하기 위해 OHD-Caps라는 벤치마크를 제안한다.
- CLIP 계열의 다양한 encoder들을 정량적으로 평가한 결과, 모두 심각한 object hallucination 문제를 나타낸다는 것을 발견하였다.
- CLIP 모델을 추가 파인튜닝하기 위해 fine-grained object-level contrastive loss를 제안하였으며, 이를 통해 CLIP 모델의 object hallucination 문제를 크게 완화할 수 있었다(예: "CLIP ViT-B/32"의 경우 14.3에서 82.5로 개선). 동시에 이를 visual encoder로 사용하는 LLaVA-1.5의 hallucination 문제도 완화되어 Nocaps 기준으로 80.2에서 83.2로 향상되었다.
2. Related Work
2.1 Large Vision-Language Model
최근에, LLM의 성공에 영감받아 연구자들은 강력한 LLM을 통합하여 VLM을 개선하려는 노력을 기울이기 시작했으며 이를 통해 모델의 지식 범위를 확장하고 언어 이해 능력을 증대시키는 것을 목표로 하고 있다.
LVLM 아키텍처는 일반적으로 세 가지 요소 visual encoder, modality connection module, LLM으로 구성된다. visual encoder와 LLM은 일반적으로 고정된 대규모 사전학습 모델로, 시각적 특징을 추출하는데 사용되는 visual encoder는 보통 CLIP 모델의 변형이다. LLaMA와 Vicuna와 같은 LLM은 이미지 정보와 텍스트 정보를 통합하는 데 사용되고 target 예측을 완료하는 데 사용된다. 연구자들은 modality connection module을 최적화하는 데 중점을 두고 있으며 Flamingo의 cross-attention, LLaVA의 linear layer, BLIP-2의 Q-former와 같은 다양한 접근법들이 있지만, 모두 다양한 vision-language task에서 VLM 성능을 향상시키고 있다.
2.2 Hallucination in LVLMs
LVLM이 visual-language task를 잘 해결한다는 사실에도 불구하고 hallucination에 시달린다. LVLM에서 hallucination의 문제는 주로 visual input과 textual output 간의 불일치를 나타낸다. 예를 들어, image captioning task에서 hallucination은 이미지에 존재하지 않는 object를 묘사하는 caption을 생성되는 것을 의미한다. LLM의 hallucination 문제가 NLP 분야에서 널리 연구되었지만, LVLM의 hallucination 문제를 완화하기 위한 연구는 충분하지 않았다. LVLM에서 hallucination을 완화하기 위한 최근 노력들은 모델의 각 구성요소를 향상시키는 데 중점을 두고 있다. 예를 들어, Liu et al. (2023b)와 Hu et al. (2023)은 LVLM을 위한 contrastive question-answer 쌍을 포함한 instruction-tuning dataset을 구축하였고 Sun et al. (2023b)와 Yu et al. (2023)은 모달리티 간 connection module을 강화하기 위해 Reinforcement Learning from Human Feedback (RLHF)를 적용하였다. 또한, Leng et al. (2023)은 LLM decoding을 위한 visual contrastive decoding 전략을 제안하였다. CLIP 모델이 VLM에서 널리 사용되고 pairwise 비교 맥락에서 심층적으로 연구되어 왔음에도 불구하고, hallucination과 관련된 평가에 대해서는 논의가 거의 없었다. 본 연구는 이러한 문헌상의 공백을 다루고자 한다(아직 다뤄지지 않은 연구 주제를 탐구한다).
3. The OHD-Caps Benchmark
최근 연구에 따르면 LVLM이 object hallucination에 취약한 경향이 있는 것으로 밝혀졌다. 이에 대응하여, 연구자들은 이러한 모델에서 hallucination의 정도를 평가하기 위해 여러 데이터셋을 개발하였다. 그러나, LVLM에서 visual encoder로 널리 사용되는 CLIP 모델의 hallucination 효과에 대한 평가 연구는 상대적으로 부족하다. 이 section에서는 CLIP 모델의 object hallucination 문제를 평가하기 위해 구축한 Object Hallucination Detection benchmark (OHD-Caps)와 평가를 위한 파이프라인을 소개한다. Figure 1은 본 논문의 벤치마크 생성 과정의 파이프라인을 보여준다.

3.1 Dataset Construction
CLIP은 이미지 이해에 뛰어난 다재다능한 neural network로 zero-shot 방식으로 이미지에 대한 텍스트를 예측할 수 있다. CLIP 모델이 쌍별 비교 시나리오에서 object hallucination을 처리하는 능력을 평가하기 위해, 올바른 캡션이 포함된 이미지에 대해 hallucination 내용을 포함한 잘못된 캡션을 생성한다. 이는 모델이 hallucination 없이 올바른 텍스트를 정확하게 선택할 수 있는지를 관찰하기 위함이다.
Inserting Hallucinatory Objects
이전 연구에 따르면, LVLM은 dataset에 자주 등장하는 object에 대해 hallucination 응답을 생성할 가능성이 더 높은 것으로 나타났다. 이것에 영감을 받아, hallucination에 취약한 object를 올바른 caption에 삽입하여 negative sample을 만든다. object annotation을 수집하기 위해, 우선 이미지에 있는 object를 자동으로 segment 해주는 SEEM을 사용한다. 세 가지 종류의 hallucination object를 수집한다. 무작위로 샘플링된 random objects, 전체 데이터셋에서 가장 자주 등장하는 popular objects, segmented object와 함께 전체 데이터셋에서 가장 자주 등장하는 adversarial objects. 각 카테고리는 세 가지 object들을 포함한다. 다양한 수준의 hallucination에 대해 예제를 생성하기 위해, 각 카테고리에 한 개에서 세 개의 object를 삽입하려고 시도하며, 그 결과 각 유형의 hallucination은 총 7개의 샘플을 포함하게 된다.
* segment : 이미지를 분할하여 object의 경계와 영역을 식별하는 task
주어진 caption text와 여러 hallucination object를 기반으로, 해당 object를 적절한 위치에 삽입하며 이는 GPT-4의 도움을 통해 효과적으로 수행할 수 있다. caption과 object는 Add_Prompt (see Table 13)으로 구성된 prompt로 GPT-4에 자동으로 입력된다.
Removing existing Objects
hallucinatory object를 삽입하는 것 외에도, caption에서 object를 제거하여 negative sample을 생성한다. 이미지에서 1개 혹은 2개의 segmented object를 무작위로 선택하여 6개의 negative sample을 생성한다. 그런 다음, GPT-4에게 Remove_Object_Prompt를 사용하여 해당 object를 caption에서 제거하도록 요청한다. 식별된 object가 title text에 존재하지 않는 시나리오를 고려하기 위해, GPT에게 원본 caption에서 object, 색상, 속성과 같은 요소를 변경하도록 요청하며 사용하는 prompt는 Alter_Object_Prompt이다. 해당 prompt는 Table 13에서 볼 수 있다.
** 6개의 negative sample을 생성한다는 것은 SEEM 모델로부터 3개의 object만 뽑는다는 것을 가정하는데, 이를 저자에게 문의해보니 3개 미만 object를 뽑을 경우 제거하고 4개 이상 뽑을 경우 앞에 3개 object만 이용한다고 답변이 왔다. 4개는 왜 이용을 안했을까 생각을 해보면 비용이 2배 넘게 증가하여서 3개까지만 이용하지 않았을까 싶다. (4C1+4C2+4C3+4C4=15개 생성됨)
COCO, Flickr30K, 그리고 NoCaps validation dataset의 out of domain subset에 대해 각각 500개의 샘플로 구성된 데이터셋을 구축하였으며, 각 이미지에 대해 27개의 negative sample을 포함시켰다. 구체적으로, Nocaps의 out of domain subset은 COCO dataset에서 보지 않은 object로 구성되어 있으며, 이는 일반적으로 모델이 보지 못한 클래스에 대해 일반화하는 능력을 측정하는 데 사용된다. 데이터셋에서 caption의 평균 길이는 Table 10에서 보여준다. (Nocaps를 out of domain dataset으로 선택한 것은 Section 4에서의 파인튜닝 과정에 국한된 것이며 CLIP의 사전학습 과정과는 관련이 없다.)
3.2 Evaluation and Analysis
본 논문에서 구축한 벤치마크에서 성능을 평가하기 위해 여러 가지 모델들을 연구한다. 각 이미지는 올바른 caption과 27개의 negative sample 쌍으로 이루어져 있고 모델은 이미지와 caption 후보 간의 유사도를 계산하여 올바른 caption을 선택한다.
Models
CLIP의 ViT-B/32 및 ViT-L/14를 포함한 다양한 모델을 벤치마크에서 평가한다. 평가 모델에는 데이터 정제이후 고품질 데이터셋에서 사전학습된 MetaCLIP과 DFN2B CLIP, 훈련 기간동안 계산 부하를 줄이기 위해 더 짧은 image/text 시퀀스를 사용하여 효율적인 훈련을 달성한 CLIPA, 모델 성능 향상을 위해 혁신적인 representation 학습 기술, 최적화 기법, 향상 전략을 활용한 EVA CLIP, 그리고 언어 및 이미지 데이터에 대해 전통적인 softmax 대신 sigmoid 함수 기반의 contrastive learning loss를 사용하여 사전학습된 SigLIP, image encoder로 ConvNext를 사용하는 CLIP 모델의 변형인 CLIP ConNext, NLLB 모델의 text encoder와 SigLIP 모델의 image encoder를 결합한 또 다른 CLIP 모델의 변형인 CLIP NLLB-SigLIP, CLIP ViT-B/32를 기반으로 object, attribute, 단어 순서 간의 관계 이해를 강화하기 위해 구문을 교체하는 방식을 사용하는 NegCLIP, 더 나은 negative sample을 개발하고 contrastive loss를 활용하여 조합적 추론을 향상시킨 CECLIP, vision 및 language 그리고 vision-and-language multi-modal task를 수행할 수 있는 단일 통합 기반 모델인 FLAVA, contrastive and generative learning objective를 가진 사전학습 모델인 CoCa, 14M 및 16M pretrained image를 통해 시각적 개념과 텍스트 input을 다중 세분화 방식으로 정렬하는 XVLM, 14M 및 129M pretrained image를 통해 caption을 bootstrapping하여 web data의 노이즈를 효과적으로 활용한 BLIP, Q-former를 통해 visual and textual 모달리티 간의 격차를 해소한 BLIP2가 포함된다.
Results
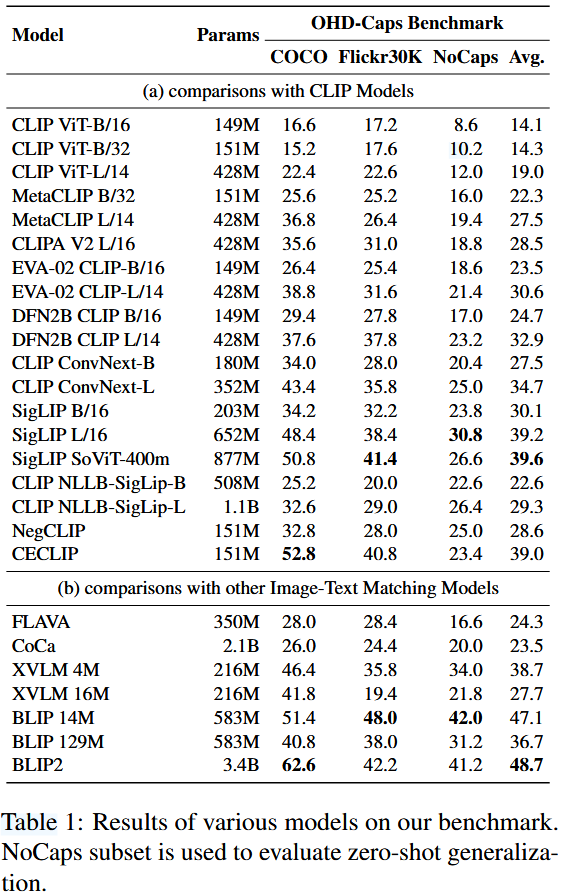
Table 1은 벤치마크에 대한 모델 결과를 보여준다. 결과로부터 다음과 같은 사실을 발견할 수 있었다.
- 우선, 기본 CLIP 모델은 세 가지 데이터셋 모두에서 저조한 성능을 보이며, 이미지에서 환각 OBJECT를 인식하는 능력이 제한적임을 나타낸다. 데이터 개선(예: MetaCLIP, DFN2B CLIP), 모델 아키텍처 개선(예: CLIP ConvNext, CLIP NLLB-SigLip), 학습 방법(예: CLIPA, EVA CLIP, SigLip)을 통해 여러 CLIP 변형 모델들이 기존 CLIP 모델보다 약간의 성능 향상을 달성하였다. 이러한 변형 모델 중에서 SigLIP은 가장 뛰어난 성능을 보여주며, out-of-domain dataset에서 최고 결과를 기록하고 우수한 일반화 능력을 입증하였다.
- 두번째로, NegCLIP은 구문을 분석하고 대체하는 방식을 통해 모델의 텍스트 이해 능력을 향상시키려고 시도하였으나 기존 CLIP 모델에 비해 단지 미세한 성능 향상만을 달성하였다. CECLIP은 상대적으로 더 나은 성능을 보이며, 이는 주로 생성된 negative sample이 모델의 문장 결합 의미에 대한 이해를 향상시키는 데 기여했기 때문이다. NegCLIP과 CECLIP 모델은 positive sample과 향상된 negative sample을 구별하기 위해 COCO training set으로 훈련된다. 이는 CECLIP이 COCO dataset에서 좋은 성능을 보이는 데 기여할 수 있으며, 부분적으로는 모델이 원래 올바른 텍스트를 기억하고 있기 때문일 수 있다. 그러나 NoCaps 데이터셋에서의 성능은 이러한 모델들이 hallucinated object를 효과적으로 구분하지 못한다는 것을 보여준다.
- 게다가, generative vision-language model은 image와 text representation의 보다 정밀한 alignment 덕분에 기본 CLIP 모델보다 더 높은 성능을 달성하는 경향이 있다. 또한, 일반적으로 모델 파라미터가 클수록 성능이 더 좋아지는 것으로 관찰된다. 특히, 가장 많은 파라미터를 가진 BLIP2는 세 가지 데이터셋 모두에서 최고 성능을 발휘한다. 이에 비해, XVLM 4M 모델은 상대적으로 적은 파라미터를 가지고 있음에도 불구하고 여전히 우수한 성능을 보여준다. 이는 XVLM의 multi-scale alignment 전략이 실제로 모델이 이미지 내의 세분화된 세부 사항을 더 정확하게 포착하는 데 도움을 준다는 것을 나타낸다.
- 마지막으로, 다양한 모델들 사이에서 전반적인 경향은 세 가지 데이터셋에서 일관되며, 일반적으로 NoCaps 데이터셋에서의 성능이 가장 낮게 나타난다. NoCaps 데이터셋에서 인식되는 객체의 수는 Flickr30K보다 적지만, out-of-domain 카테고리를 포함하고 있기 때문에 성능이 가장 낮게 나타난다. BLIP 14M 모델은 Flickr와 NoCaps 모두에서 최고 성능을 보여주며 이는 강력한 일반화 성능을 나타낸다.
Analysis
모델이 hallucinated object를 인식하지 못하는 주된 원인은 사용된 데이터와 적용된 학습 방법에 있다. 기본 CLIP 모델은 인터넷에서 수집된 대량의 image-caption 쌍을 사용하여 contrastive loss 함수를 통해 최적화되었다. 이러한 caption들은 짧고 noise한 경우가 많으며, 모델은 올바른 image-text 쌍과 다수의 잘못된 image-text 쌍을 구별하도록 최적화되어 있다. 그러나, 잘못된 쌍은 일반적으로 올바른 쌍과 상당히 다르기 때문에 모델에서는 이를 쉽게 구별할 수 있다. 이는 모델이 올바른 예측을 하기 위해 그림에서 풍부한 세부 사항을 학습할 필요가 없다는 것을 의미한다. 이러한 문제를 해결하기 위해, 데이터 활용과 학습 방법론 측면에서 기존 CLIP 모델을 개선할 필요가 있다.
4. Methodology
먼저 원본 CLIP 모델의 훈련 과정을 다시 살펴본다. 이미지를 I, 텍스트를 T라고 할 때, CLIP의 학습 목표는 이미지와 텍스트 쌍 간의 유사성을 극대화하고 일치하지 않는 이미지와 텍스트 쌍 간의 유사성을 최소화하는 것이다. loss function은 다음과 같이 정의된다.
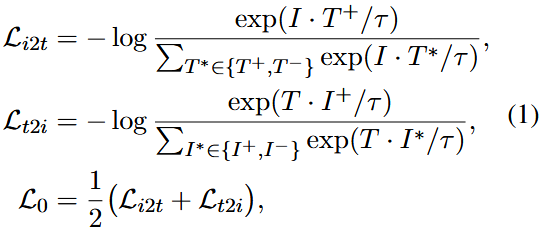
T+와 I+는 올바른 텍스트와 이미지이고 T-와 I-는 부정확한 텍스트와 이미지이다.
이전 section에서 생성된 negative sample Tneg를 추가함으로써, loss Li2t를 다음과 같이 수정할 수 있다.
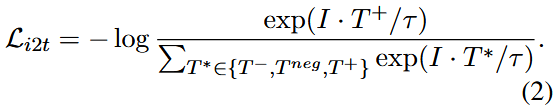
모델이 positive sample과 negative sample을 구분하는 능력을 더욱 향상시키기 위해, 추가적으로 margin loss를 도입한다. 이는 이미지와 해당하는 올바른 텍스트 간의 거리가 잘못된 텍스트와의 거리보다 특정 임계값(threshold)만큼 작아지도록 보장하기 위한 것이다. 이 개념은 다음과 같이 공식화될 수 있다.
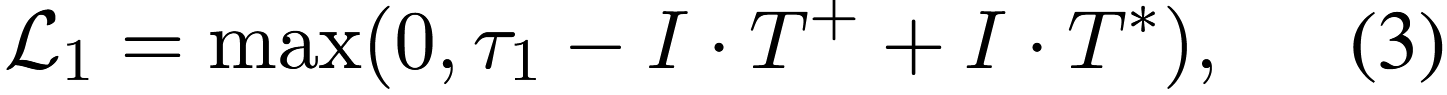
τ1은 margin threshold를 나타내며 T*는 {T-, Tneg}이다.
추가적으로, 기존 positive sample에 변형을 가하여 향상된 negative sample을 생성한다. 이러한 negative sample들은 전형적으로 같은 배치 내에서 다른 negative sample보다 구별하기가 더 어렵다. 모델이 향상된 negative sample에 포함된 올바른 정보를 인식하도록 유도하기 위해, 향상된 negative sample이 배치 내에서 다른 negative sample보다 positive sample과 더 높은 유사성을 가지도록 다음과 같은 margin loss를 도입한다.
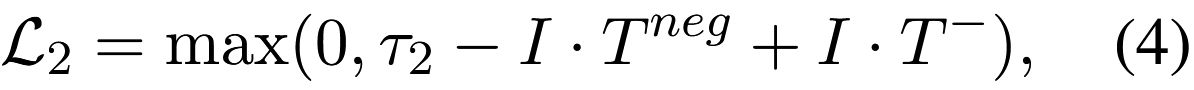
τ2는 margin threshold를 나타낸다.
다음으로, 앞서 언급한 loss 항목들에 서로 다른 가중치를 할당하여 모델이 적응적으로 학습할 수 있도록 한다. 따라서, 최종 loss function은 다음과 같이 표현될 수 있다.
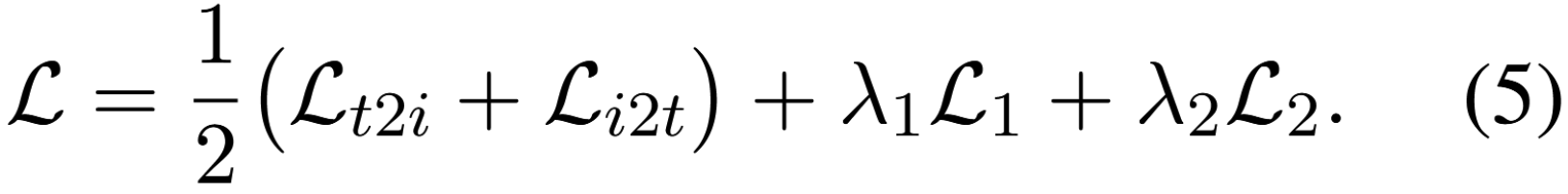
5. Experiments
Training Datasets
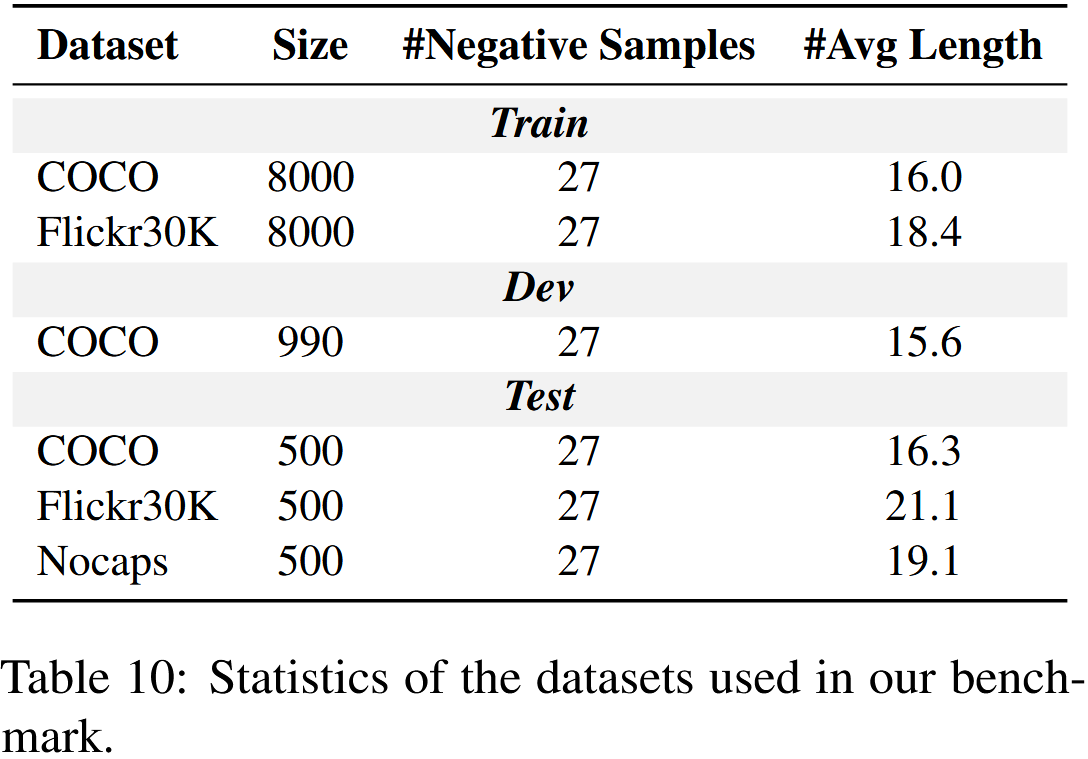
COCO training set에서 8k images, Flickr30k dataset에서 8k images를 샘플링한 후 section 3에서와 같이 각 이미지에 대해 negative sample을 생성한다. 추가적으로, 하이퍼파라미터 선택을 위해 dev set으로 COCO dataset의 validation set에서 ~1k sample을 무작위로 선택한다. 데이터셋에 대한 자세한 정보는 Table 10에서 제공된다.
Training Details
초기 모델로 huggingface에서 구현된 CLIP ViT/32-B와 CLIP ViT/14-L-336px를 활용하며 파인튜닝에서 10 epoch을 수행한다. 학습 과정은 단일 A6000 GPU에서 진행되며 base 모델과 large 모델에 대해 bach size를 각각 56과 14로 설정하고 learning rate는 1e-6으로 설정한다. 하이퍼파라미터는 validation set에서의 성능을 기준으로 선택하며
Evaluation
본 논문의 방법이 모델의 일반화 능력에 미치는 영향을 검증하기 위해, 다음 데이터셋으로 zero-shot 실험을 수행하였다. CIFAR-10/100, ImageNet-1K, DTD, Eurosat, GTSRB, and STL10.
5.1 Main Results
Table 2에는 자체 구축한 데이터셋에 대한 결과를 제시하고 Table 3에는 다양한 zero-shot 데이터셋에 대한 결과를 제시한다.
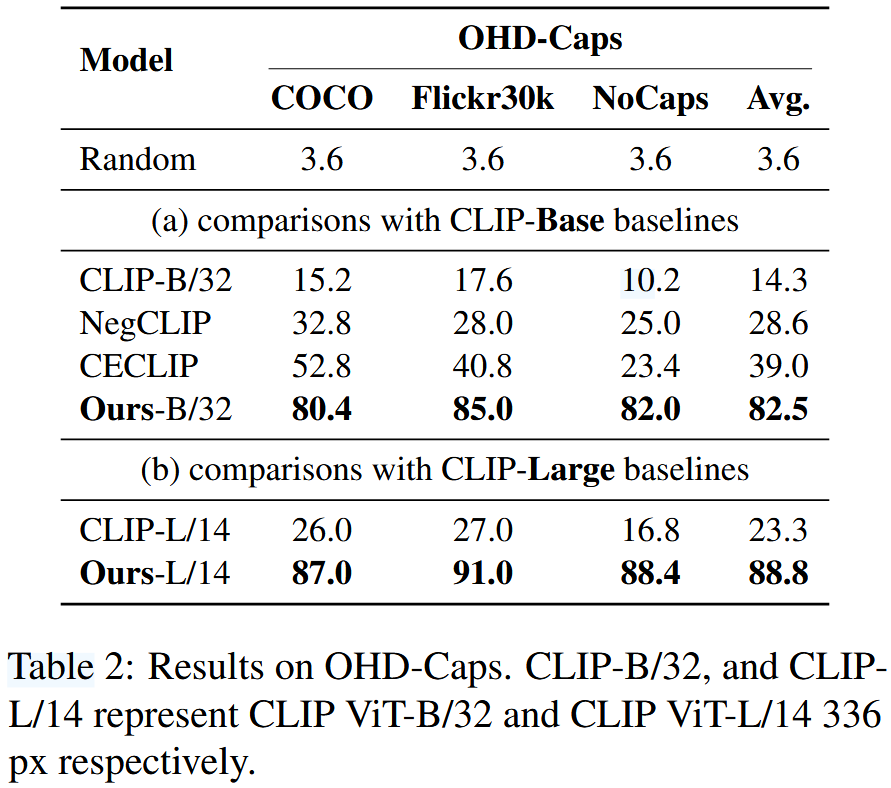
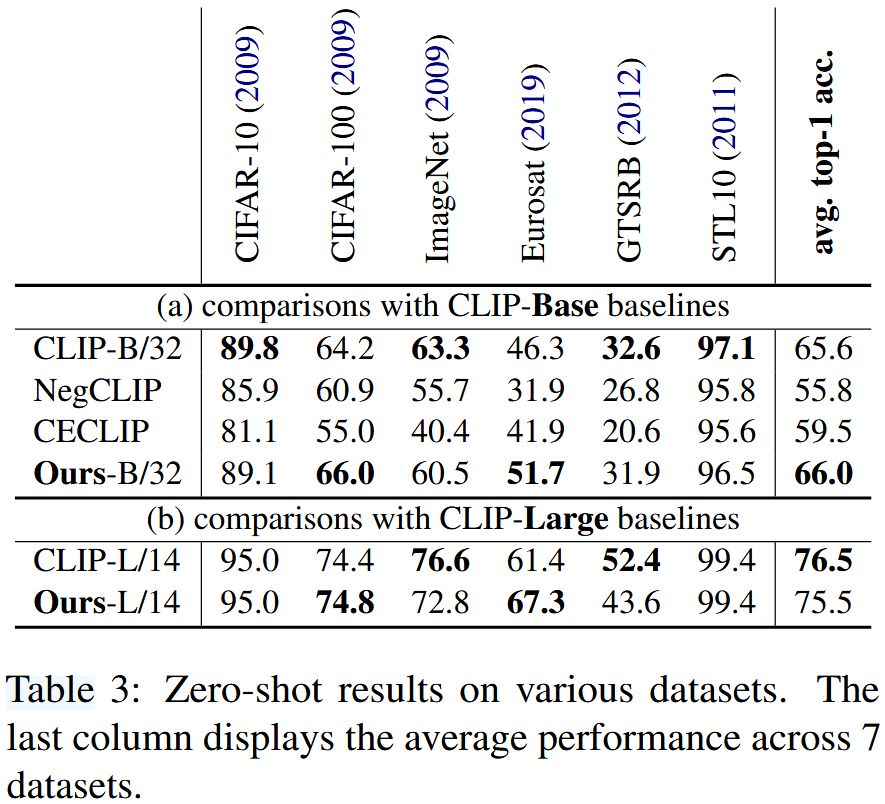
결과로부터 다음과 같은 점을 찾을 수 있다.
- 기본 CLIP 모델과 유사한 zero-shot 성능을 보였으며 (65.6 vs 66.0) hallucination 인식 성능에서 상당한 개선을 달성하였다 (14.3 vs 82.5). NegCLIP과 CECLIP은 negative sample을 생성함으로써 복합적인 정보를 이해하는 모델의 능력을 강화했으며 OHD-Caps 벤치마크에서 성능이 14.3%에서 39.0%로 상승하는 적당한 개선을 이루었다. 그러나, NegCLIP과 CECLIP의 zero-shot 성능은 크게 감소하였다. 이는 negative sample을 생성하기 위해 구문 교체와 같은 규칙 기반 방법에 의존하기 때문일 수 있으며, 이러한 방식이 모델의 문장 의미 이해를 방해했을 가능성이 있다.
- 본 논문에서 제안한 모델은 hallucination 인식에서 강력한 일반화 성능을 보여준다. NegCLIP, CECLIP, 그리고 본 논문에서 제안한 모델은 모두 COCO dataset의 training set에서 파인튜닝을 거쳤다. COCO와 관련된 hallucination test에서는 각 모델이 성능 향상을 보여주지만 (NegCLIP: 32.8%, CECLIP: 52.8%), unknown 카테고리에 직면했을 때는 성능이 저조했다 (NegCLIP: 25.0%, CECLIP: 23.4% for NoCaps images). 이는 모델들의 일반화 능력이 제한적임을 나타낸다. 반면, 본 논문에서 제안한 모델은 세 가지 서로 다른 데이터셋에서 일관된 성능(약 82%)을 보여준다. 이 결과는 모델이 다양한 데이터셋에서 hallucinated object를 효과적으로 구별할 수 있으며, 데이터셋 간 일반화 능력을 가지고 있음을 검증한다.
5.2 Evaluation for LVLM
object hallucination 문제를 완화하기 위해 large vision-language 모델을 지원하는 데 있어 기존 CLIP과 비교하여 향상된 CLIP 모델의 효과성을 검증하기 위해, LLaVA-1.5에서의 baseline 모델인 CLIP ViT-L/14-336px를 본 논문에서 파인튜닝된 버전으로 대체한다. 원본 논문에서 명시된 하이퍼파라미터를 사용하여 처음부터 LLaVA를 학습한다. SFT 데이터를 구축하거나 추가적인 alignment를 위해 DPO process를 도입하는 등의 다양한 방법들과의 비교 결과는 appendix B에서 확인할 수 있다.
Hallucination Detection
모델 내에서 판별적(discriminative) 응답과 생성적(generative) 응답에서의 hallucination 현상 발생을 평가하기 위해, 다음 평가 방법을 분석에 사용한다. POPE 데이터셋은 판별적 응답에서의 환각을 평가를 위한 데이터셋으로 POPE에 포함된 질문의 형식은 "Is there a X in the image?"이며 여기서 X는 object 이름을 나타낸다. 데이터셋의 질문은 object가 존재하는 경우와 존재하지 않는 경우가 동일한 비율이 되도록 설계되었으므로, 이상적인 "yes" 응답률은 약 50%이어야 한다. POPE 데이터셋을 확장하고 Flickr30k 및 NoCaps 도메인을 포함하여 모델의 일반화 능력을 테스트한다. CHAIR 평가는 생성적 응답에서 환각을 평가하기 위한 metric으로 환각된 객체(ground-truth에 없는 객체)가 텍스트에 얼마나 자주 나타는지 측정한다. 즉, 참조된 객체 중 실제 환각된 객체의 비율을 측정한다. AMBER 데이터셋은 판별적 및 생성적 응답을 모두 평가할 수 있는 데이터셋으로 모델의 환각 문제를 종합적으로 평가한다.
CHAIR metric은 세 가지 수준에서 평가한다.
(1) 문장 수준 (Sentence-level, CHAIR S)
- 하나의 문장에서 환각된 객체 비율을 계산

(2) 이미지 수준 (image-level, CHAIR I)
- 하나의 이미지에 연결된 모든 캡션 중, 환각된 객체를 포함한 캡션의 비율을 계산
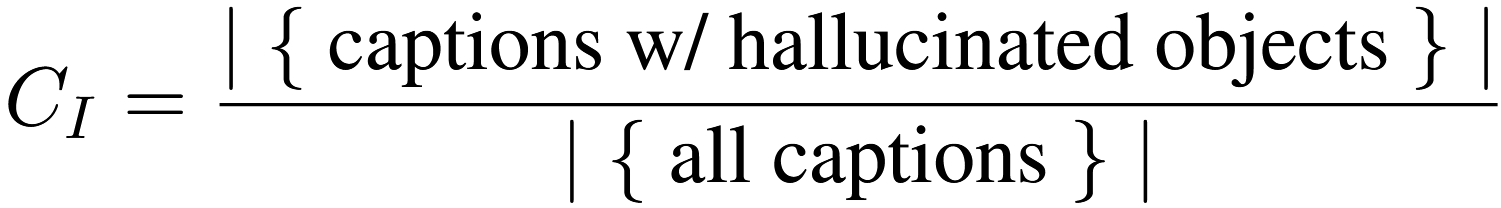
(3) 객체 커버리지 (Coverage, Cover)
- 생성된 캡션이 ground-truth 객체를 얼마나 포괄했는지 평가
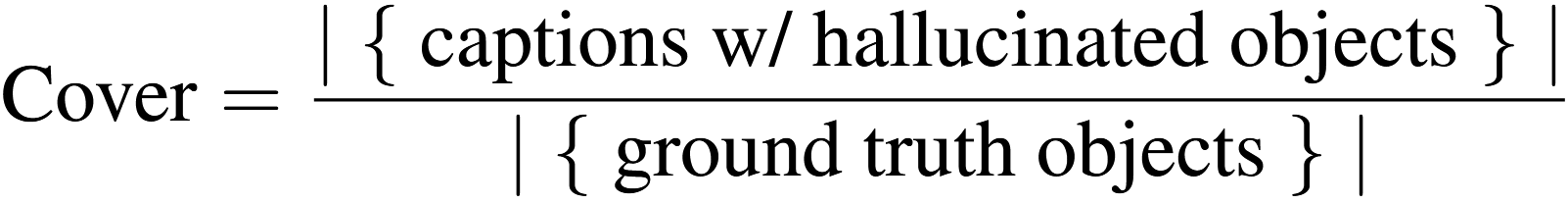
** 위 cover metric은 오타이다. 분자는 captions w/o hallucinated obejcts 이여야한다. 즉, Cover가 높을수록 좋다. 저자한테 문의해봤는데 오류라고 답변받았다.
* 판별적 응답 (discriminative response) : 모델이 사전 정의된 선택지 중에서 가장 적합한 응답을 선택할 때, 환각 현상이 발생하는지 평가.
* 생성적 응답 (generative response) : 주어진 입력을 바탕으로 새로운 텍스트를 생성할 때, 환각 현상이 발생하는지 평가.
* 문장 수준 (sentence level) : Cs는 모델이 생성한 각 문장을 독립적으로 평가하는 방식으로 문장 하나에서 hallucinated object가 얼마나 많이 언급되었는지 분석.
* 이미지 수준 분석 (image-level analysis) : Ci는 하나의 이미지에 연결된 모든 캡션을 종합적으로 평가하는 방식으로 이미지와 관련된 캡션에서 환각 현상이 얼마나 자주 발생하는지 확인.
* 객체 포괄성 (object coverage) : Cover는 모델이 생성한 캡션의 객체 포괄성을 평가한다. 생성된 캡션이 실제 존재하는 객체를 얼마나 잘 포함하는지 측정.
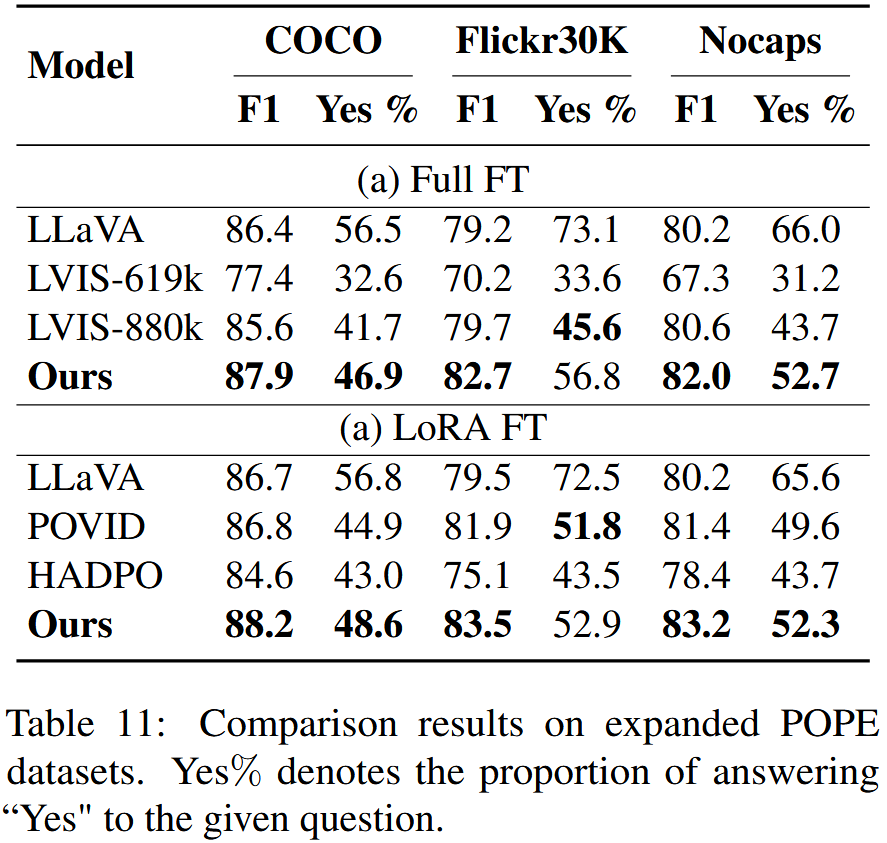
Table 4,5,6은 각각 확장된 POPE 데이터셋, CHAIR 평가, AMBER 데이터셋에 대한 결과를 보여준다.
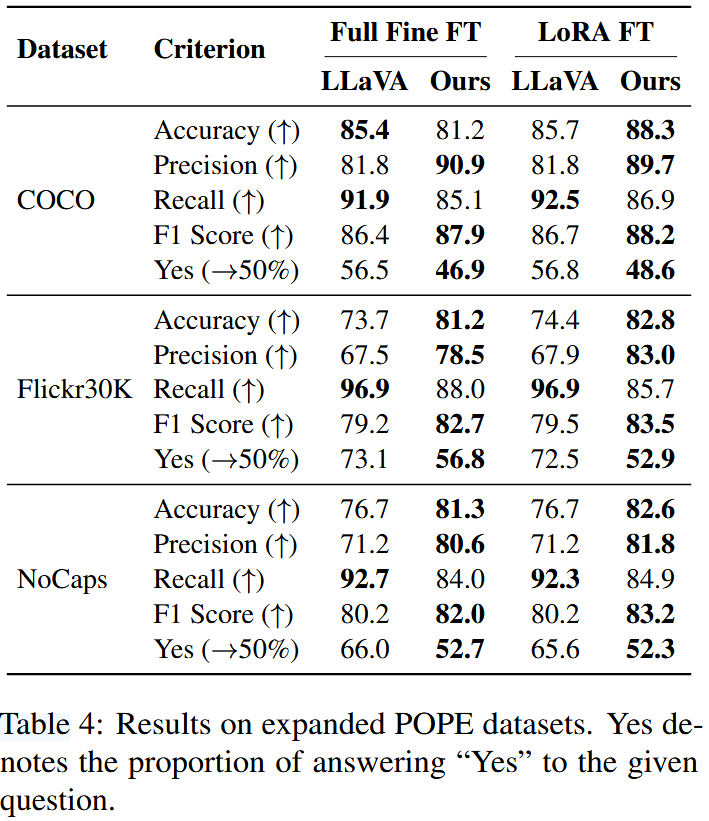
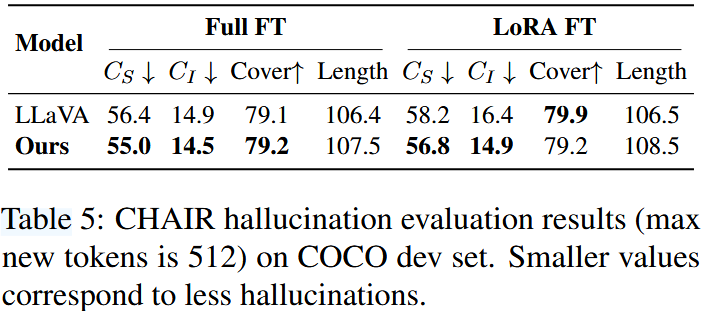
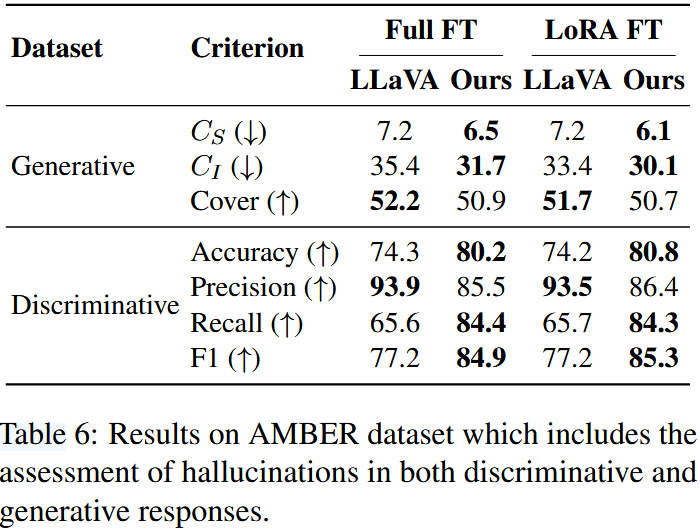
결과로부터 다음과 같은 점을 확인할 수 있다.
- 판별자 응답의 경우, 다양한 데이터셋에서 상당한 성능 향상을 달성하였다. POPE 데이터셋에서는 기존 모델에 비해 정확도와 recall 간의 더 나은 균형을 이루어 더 높은 F1 score를 달성하였으며, "Yes" 응답 비율에서도 보다 이상적인 균형에 근접하였다. 동일한 성능 향상 현상은 AMBER 데이터셋에서도 관찰되었다.
- 생성적 응답의 경우, COCO validation set과 AMBER 데이터셋에서 더 낮은 hallucinated object 비율을 보여주었으며 상대적으로 안정적인 포괄성과 응답 길이를 유지하였다.
General Performance
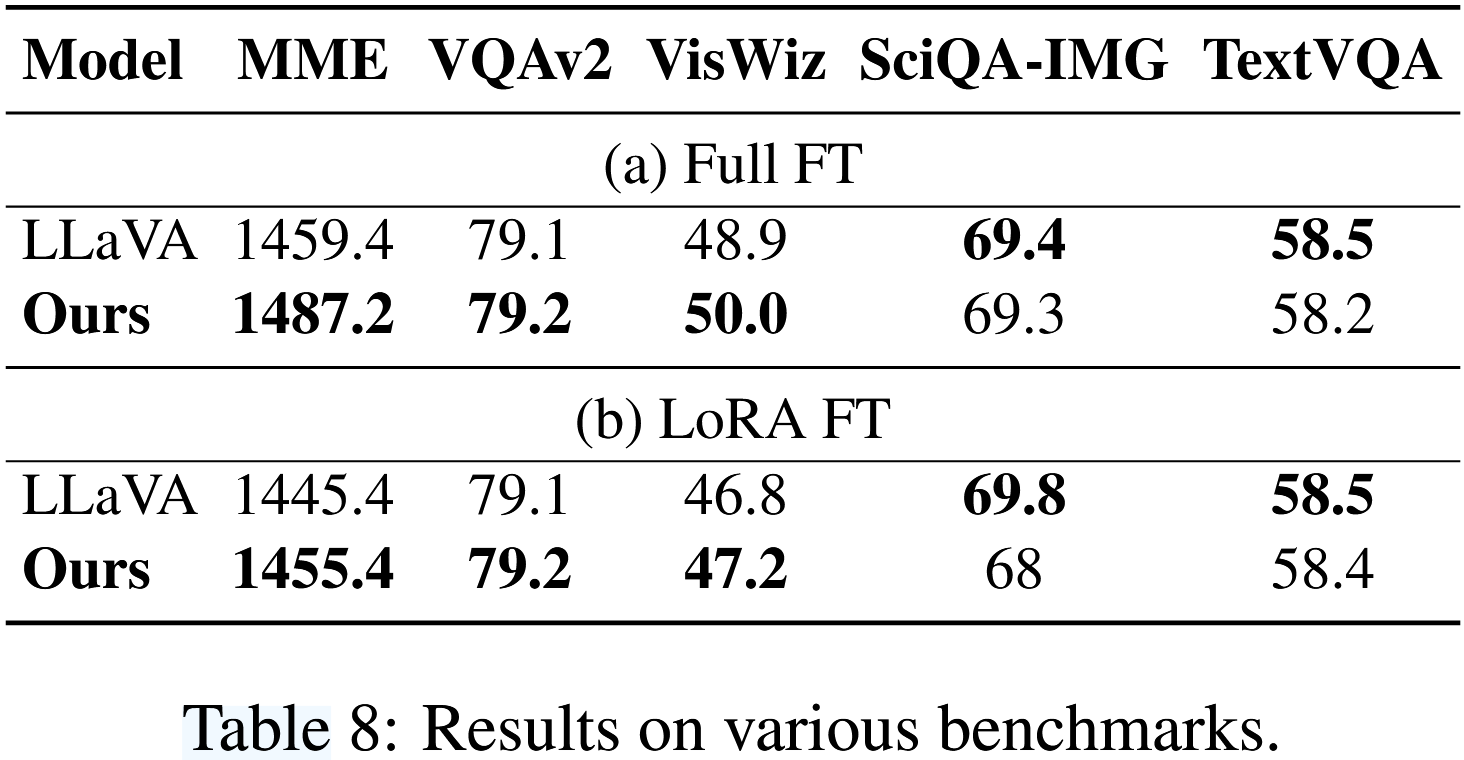
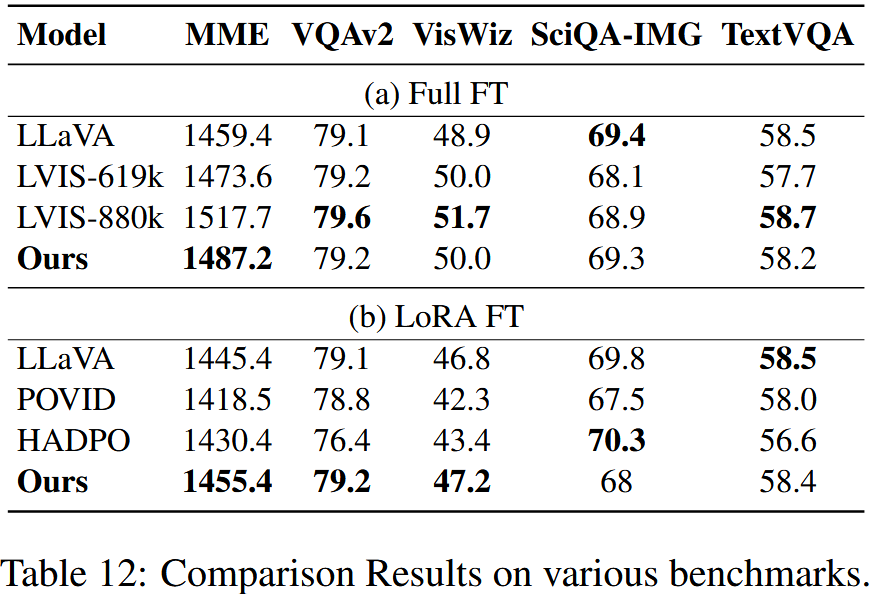
다양한 데이터셋에서 모델의 일반적인 성능을 평가한다.
MME-Perception는 yes/no 질문에 대해 모델의 시각적 인식을 평가한다.
VQA-v2는 open-ended short answer에 대해 시각적 인식 능력을 평가한다.
VizWiz and ScienceQA는 시각적 질문들에 대해 모델의 zero-shot 일반화를 평가하기 위해 다지선다형으로 평가한다.
TextVQA는 텍스트가 풍부한 vqa가 포함되어 있다.
결과는 Table 8에서 보여준다. full fine-tuning을 적용했을 때 모델의 평균 성능이 약간 향상된 것을 확인할 수 있다. 구체적으로, 다섯 개 데이터셋에 대한 평균 성능은 343.1에서 348.5로 증가했으며 가장 두드러진 개선은 MME 데이터셋이다. 반면, LoRA fine-tuning을 적용했을 때 모델의 평균 성능은 거의 변하지 않았다 (340.0 vs 341.7).
5.3 Ablation Study
이 subsection에서는 모델의 다양한 구성요소가 미치는 영향을 탐구하기 위해 ablation study를 제시한다. 이러한 실험은 CLIP ViT-B/32 모델을 기반으로 수행되었다.
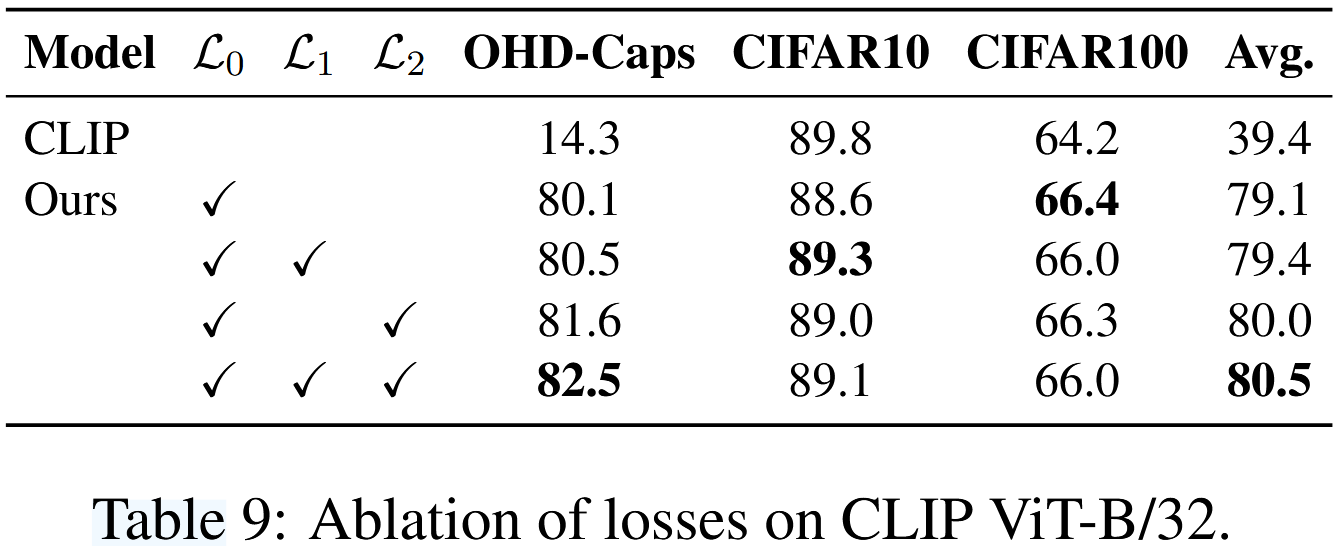
Losses
Table 9에서 볼 수 있듯이, L0 loss만 포함시켰을 때도 기본 baseline 대비 OHD-Caps 성능이 크게 향상되었다. 이후 L1과 L2를 반복적으로 추가하면서 점진적인 성능 향상이 이루어졌으며 모든 loss 항목을 겹합했을 때 가장 높은 평균 성능을 달성하였다. L1 loss와 비교했을 때, L2 loss가 모델 성능 향상에 더 큰 영향을 미치는 것으로 나타났다. 이는 생성된 negative sample과 배치 내 다른 negative sample 간의 거리를 증가시킴으로써 모델이 더욱 정교한 이해를 달성할 수 있음을 시사한다.
Data Volume
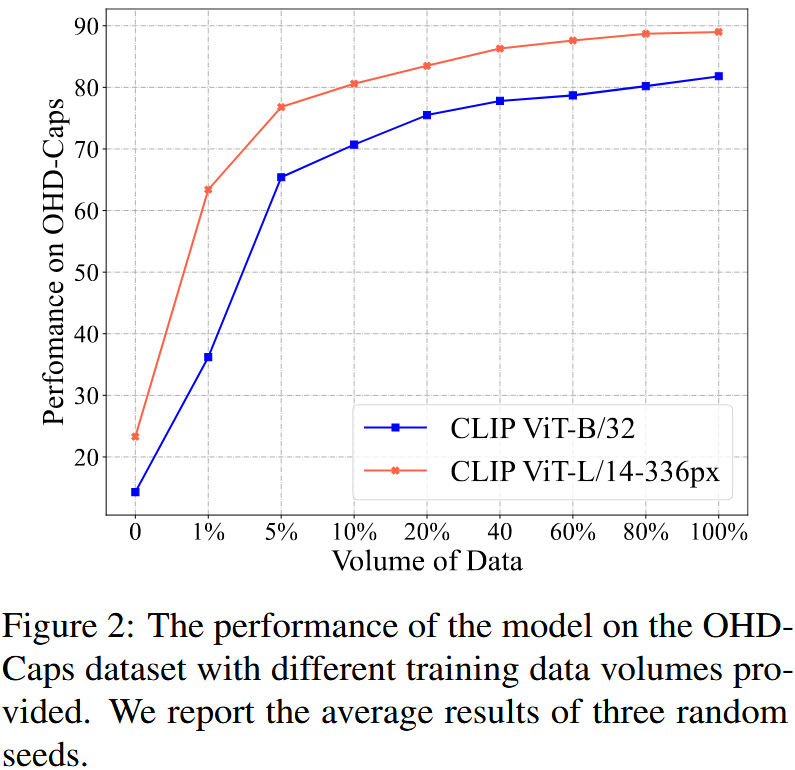
Figure 2는 다양한 양의 training data를 사용한 OHD-Caps 데이터셋에 대한 성능을 보여준다. figure에서 볼 수 있듯이, 아주 적은 양의 데이터로도 모델의 성능이 크게 향상될 수 있다. 예를 들어, 단 1%의 데이터(즉, 160개 이미지)로 학습하면 CLIP-L/14 모델의 성능이 20%에서 60%로 향상될 수 있다. 그러나, 데이터를 추가할수록 성능 향상은 점차 느려지고 안정화된다.
6. Conclusion
본 연구는 LVLM에서 object hallucination의 원인을 조사한다. 그리고 hallucination 평가를 위해 벤치마크를 구축하고 현재 LVLM에서 흔히 사용되는 visual perception module인 CLIP 모델이 hallucinated text를 효과적으로 구별할 수 없음을 발견했다. negative sample을 설계하고 contrastive loss function을 최적화함으로써 hallucination detection 데이터셋에서 모델 성능을 크게 향상시켰다. 또한, 기존 CLIP 모델을 개선된 모델로 대체하면 LLaVA 모델에서 object hallucination 문제를 효과적으로 완화할 수 있다.
Limitations
비록 일련의 탐색을 수행했지만 본 연구에는 여전히 한계가 있다. 첫째, 본 논문의 초점은 LVLM에서의 object hallucination 문제에만 맞춰져 있으며, 다른 유형의 hallucination으로 연구를 확장하지는 않았다. 둘째, 본 논문에서 제안한 벤치마크는 20개 이상의 negative sample로 구성되어 있다. 그러나 예산 제약으로 인해, 이 데이터셋의 크기는 조합적 이해를 평가하는 데 사용되는 데이터셋(예: ARO dataset)에 비해 훨씬 작다. 셋째, 대부분의 LVLM에서 사용되는 visual encoder인 CLIP 모델만 평가했으며 다른 모델에서 사용되는 encoder에 대한 연구는 수행하지 않았다. 예를 들어, Flamingo에서 사용된 ResNet 변형인 NFNet-F6과 같은 encoder에 대한 연구는 포함되지 않았다.
* 조합적 이해 (compositional understanding) : 모델이 개별적인 요소 (객체, 속성, 관계 등)을 조합하여 전체적인 의미를 파악하는 능력.
Ethics Statement
object hallucination은 LVLM의 실제 응용 가능성을 심각하게 제한한다. 예를 들어, 의료 이미지 진단에서 환각은 이미지에 존재하지 않는 종양 객체에 대한 잘못된 설명으로 이어질 수 있다. 본 연구는 LVLM의 visual encoder에서 환각을 완화했지만, 여전히 multi-head attention layer와 feed-forward layer에서 환각이 존재할 가능성이 있다. LVLM을 기반으로 한 실제 응용에서는 user에게 부정적인 영향을 미치지 않도록 hallucination을 체계적으로 제어해야 한다.
Appendix
A. Statistics on the Datasets
데이터셋의 통계 정보는 Table 10에 제시되어 있으며 training, testing, validation 세 부분으로 나뉘어 있다. 표에 표시된 평균 길이는 데이터셋 내 negative exmample의 평균 길이를 나타낸다.
B. Comparison with Other Methods
제안된 방법이 다른 방법들보다 더 적은 object hallucination을 가지고 더 나은 일반화 성능을 가짐을 보여주기 위해, 추가적으로 다음 접근법들과 비교 수행하였다.LVIS는 220k개의 visual instruction dataset을 구축하였으며 GPT-4V의 뛰어난 시각적 분석 능력을 활용하고 세심하게 설계된 프롬프트를 통해 데이터를 생성하였다. 기존 LLaVA training data를 확장하여 619k개와 880k개인 데이터셋을 추가적으로 생성하였다.POVID와 DPO는 각각 GPT4V와 GPT4를 사용하여 hallucination 텍스트를 생성하였다. 고품질의 환각이 없는 응답과 쌍을 이루어 DPO 최적화를 위해 사용하였다. 논문에서 제공된 체크포인트를 기반으로 모델 결과를 보고한다.
결과는 Table 11과 Table 12에서 보여준다. 결과에 따르면, 본 논문의 방법은 POPE 데이터셋에서 성능 면에서 instruction finetune 및 DPO 기반 방법보다 우수한 성과를 보였다(본 논문의 방법은 평균 F1 점수를 2.6만큼 개선한 반면, LVIS, HADPO, POVID는 유의미한 개선을 보이지 않았다). 이는 더 낮은 hallucination 비율을 보여준다. 또한, 전반적인 성능 면에서도 다른 방법들과 유사한 성과를 나타냈다.
C. More Examples
Figure 3에 더 많은 예제를 제시한다. 여기에서 본 논문의 방법이 원본 이미지에 존재하지 않는 object를 텍스트에 매끄럽게 통합할 수 있음을 확인할 수 있다. 추가된 object 이름은 빨간색으로 강조 표시되어 있다. 이미지에 실제로 존재하는 object를 제거하는 작업은 최소한의 조정으로 수행될 수 있다. 한편, 세 번째 그림에서 언급된 "food"와 같이 이미지에 묘사되지 않은 object를 제거하는 경우, negative sample은 일반적으로 positive sample에서 object, attribute 및 기타 내용을 수정하는 방식을 포함한다.




