본 글은 Stanford CS224N: NLP with Deep Learning | Winter 2021 내용을 기반으로 합니다.
강의를 듣고 정리한 글로 혹시 잘못된 부분이나 수정할 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
개체명 인식(Named entity recognition, NER)
각 개체의 유형을 인식하는 task로 어떤 단어가 사람, 장소, 조직 등을 의미하는 단어인지 찾을 수 있다.
Simple NER: Window classification using binary logistic classifier
- context window의 이웃 단어들을 이용하여 각 단어들을 분류
예를 들어 "the museums in Paris are amazing to see."라는 문장에서 "Paris"라는 단어에 대해 객체명 인식을 한다고 해보자. 이 때, window 길이를 2라고 가정하면 다음과 같이 형성된다.

각 단어에 대한 벡터를 만들면 5차원 벡터가 만들어지고 이를 neural network layer에 넣는다. 5차원 벡터는 가중치 matrix와 곱한 후 bias를 더하게 된다. 그 후, softmax 함수와 같이 f함수를 적용하여 non-linearity를 추가한다. extra vector u를 통해 낮은 차원의 벡터(특정 숫자)로 변환해준다. 실제 숫자를 얻은 후 logistic 변환을 통해 단어가 특정 클래스에 속할 확률을 구한다.
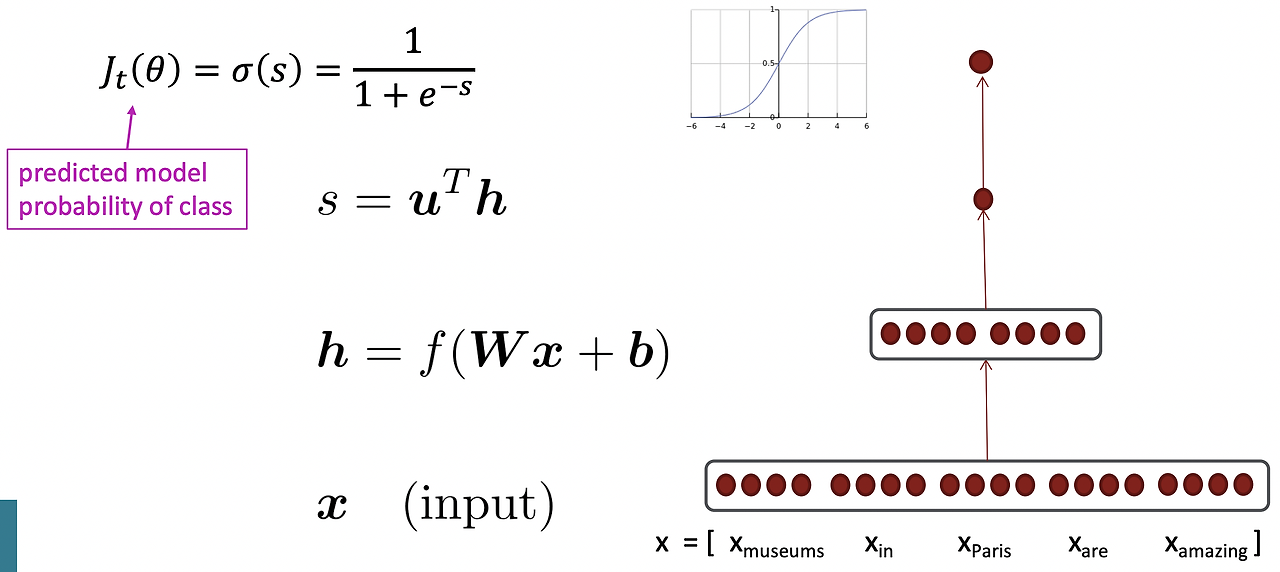
위의 과정과 같이 Feedforward를 진행한 후, Stochastic Gradient Descent(SGD)를 통해 가중치들을 업데이트한다. 여기서, J(θ)를 어떻게 구할까? 사실, 이것은 전에 작성한 Back Propagation 글에서 하나하나 계산하여 알아봤는데 이번에는 차원을 늘려 matrix 형태로 계산을 해본다.
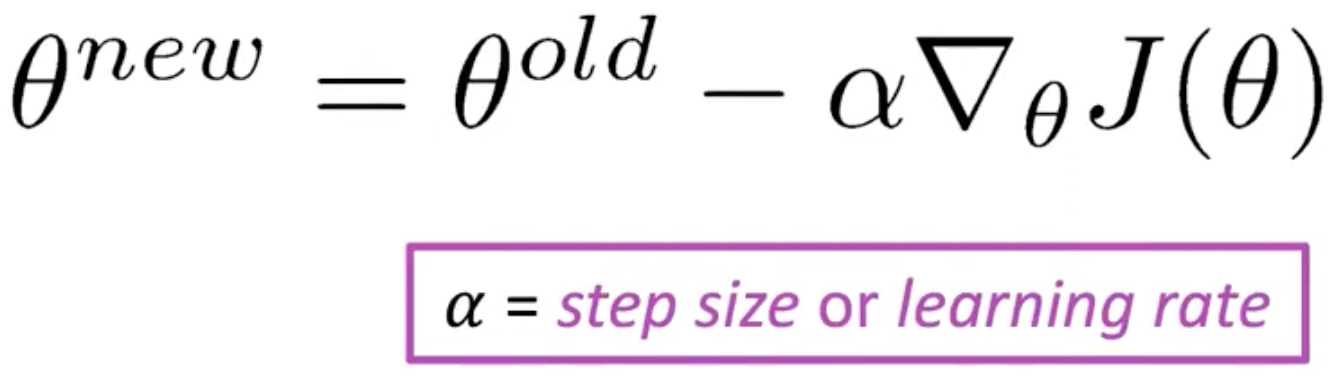
여러 매개변수를 가진 f(x) 함수(1개의 output과 n개의 input를 가진 함수)가 존재한다고 하면 각 매개변수들의 편미분 값을 통해 기울기가 정해진다.

위 그림을 좀 더 확장하여 종속변수가 많은 f(x) 함수(m개의 output과 n개의 input)이 존재한다고 하면 m * n matrix 형태의 편미분 값들을 나타낼 수 있다. 이를, Jacobian matrix라고 한다.

다시, NER 신경망으로 돌아와 W와 b에 대한 미분값을 구해보자. Chain Rule을 사용하여 h, Wx+b, b를 이용해 b에 대한 미분 값을 구하면 다음과 같다.

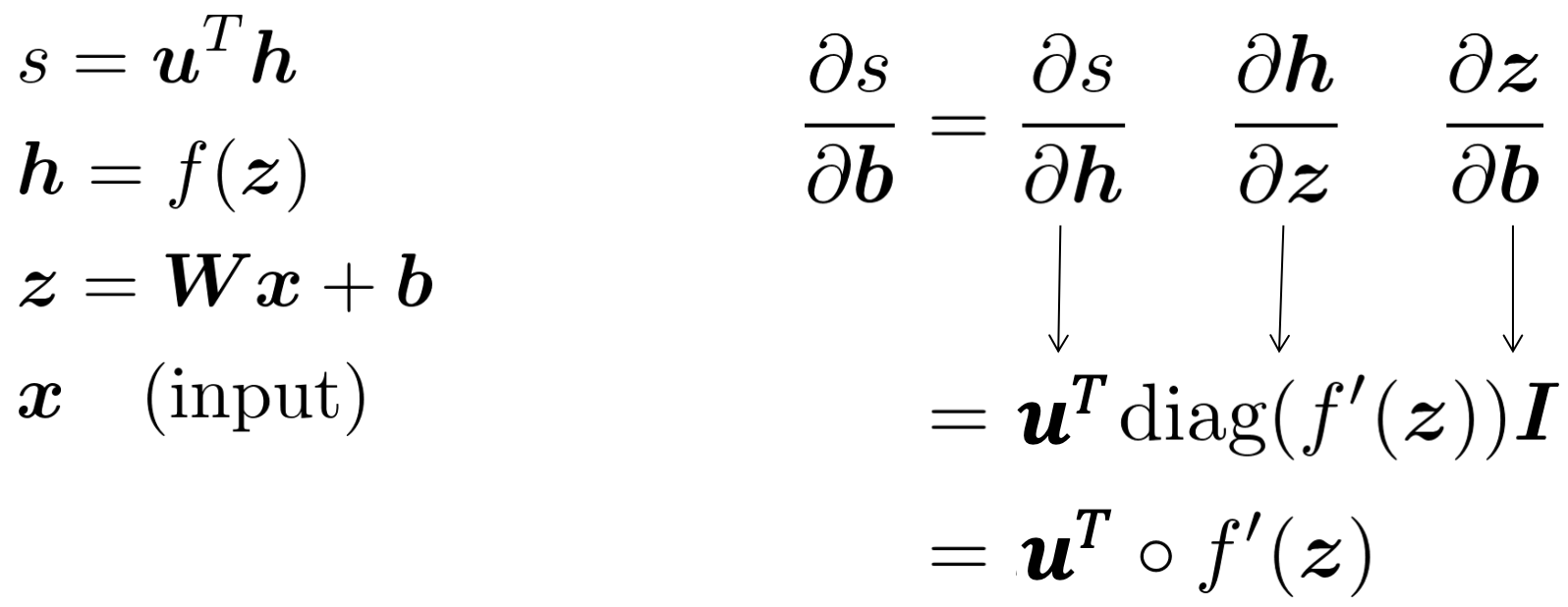
이젠, W에 대한 미분값을 구해보자. W에 대한 미분 값을 구하는 과정은 b에 대한 미분 값을 구하는 과정과 매우 유사하다. 그래서 b에 대한 미분 값을 구할 때 계산했던 값들을 이용한다.


이후 강의 내용은 Back Propagation 내용으로 이전 글 (Mathematics 파트에서 Back Propagation 글)을 참고하면 될 것 같다.
'Deep Learning Study > cs224n' 카테고리의 다른 글
| Stanford CS224N - Lecture 4. Syntactic Structure and Dependency Parsing (0) | 2024.04.04 |
|---|---|
| Stanford CS224N - Lecture 2. Neural Classifiers (0) | 2023.10.27 |
| Stanford CS224N - Lecture 1. Intro & Word Vectors (0) | 2023.10.23 |


