본 글은 Stanford CS224N: NLP with Deep Learning | Winter 2021 내용을 기반으로 합니다.
강의를 듣고 정리한 글로 혹시 잘못된 부분이나 수정할 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
Optimization
1. Gradient Descent
Optimization은 지난 Lecture 1에서 다룬 Word2Vec의 object function인 J(Θ)를 최소로 하는 것을 목표로 한다.
Gradient Descent 식은 다음과 같다.

Object function을 최소화하는 parameter를 찾기 위한 Gradient Descent는 전체 데이터에 대해 계산이 이루어지기 때문에 계산량이 너무 많으며 시간도 오래 걸린다.
2. Stochastic Gradient Descent
Gradient Descent의 단점을 보완하기 위해 일부 데이터만 샘플링하여 계산하는 방법이 Stochastic Gradient Descent(SGD)이다.
샘플링된 window만 업데이트를 진행하기에 모든 단어가 아닌 특정 단어의 vector만 업데이트된다.
이때, sparse matrix가 생성되어 계산의 효율성이 낮아진다.
3. Negative Sampling
SGD에서 sparsity로 인한 문제를 해결하기 위해 Negative Sampling이라는 기법을 사용한다.
Negative Sampling은 중심단어와 주변단어 쌍의 binary logistic regression를 학습한 후 예측 결과가 정답이 아닌 쌍에 대해 적은 확률을 부여한다. Negative Sampling 목적 함수는 다음과 같다.
o : 주변 단어 벡터, c : 중심 단어 벡터, k : 노이즈 벡터
True pair에서 중심 단어와 주변 단어들이 가까이 있을수록 목적 함수가 0에 가깝고 Noise pair에서 중심 단어와 주변 단어들이 멀리 있을수록 목적 함수는 0에 가까워진다.
Co-occurrence vectors
1. Window based co-occurrence matrix
Co-occurrence vector는 단어간의 관련성을 파악하고 벡터 형태로 표현하는 기술로 matrix의 raw 혹은 column을 word vector로 한다.
주어진 문장을 기준으로 윈도우에 각 단어의 등장횟수로 구성한다.
이는 매우 sparse하며 high dimension을 지닌다는 단점을 가진다.
2. SVD(Singular Value Decomposition)
SVD(Singular Value Decomposition; 특이값 분해)는 직교하는 벡터 집합에 대하여, 선형 변환 후에 크기는 변하지만 여전히 직교할 수 있는 직교 집합과 선형 변환 후의 결과에 대해 찾는 방법이다. SVD를 통해 차원 축소, 특이값과 특이벡터 추출, 데이터 압축 및 정보 추출을 할 수 있다.
Co-occurrence matrix에서 많이 등장하는 단어들에 대해 log 혹은 min 등을 이용하여 scaling을 진행한 후, SVD를 적용하여 차원 축소를 한다.
GloVe
왼쪽은 Count based 기법이고 오른쪽은 Direct prediction 기법이다.
Count based 기법은 빠른 학습과 효율적인 통계를 사용하지만 단어 유사성을 파악하는데만 사용되고 큰 빈도수에 대해 과도하게 중요도를 부여한다.
Direct prediction 기법은 다양한 영역에서 좋은 성능을 가지며 단어 유사도 이상의 복잡한 패턴을 파악하지만 corpus 크기가 성능에 영향을 미치며 효율적으로 통계를 사용하지 못한다.
위와 같은 두 개의 기법들을 연결한 방법이 GloVe이다.
GloVe의 아이디어를 한 줄로 요약하면 '임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 corpus에서의 동시 등장 확률이 되도록 만드는 것'이다. 즉, 이를 만족하도록 임베딩 벡터를 만드는 것이 목표이다.
위의 표는 P(Context Word | Center Word)로 구하였으며 co-occurrence matrix로부터 특정 단어의 등장 횟수를 카운트하고, 특정 단어가 등장했을 때 주변 단어가 등장한 횟수를 카운트하여 계산한 조건부 확률이다.
GloVe의 object function은 다음과 같다.

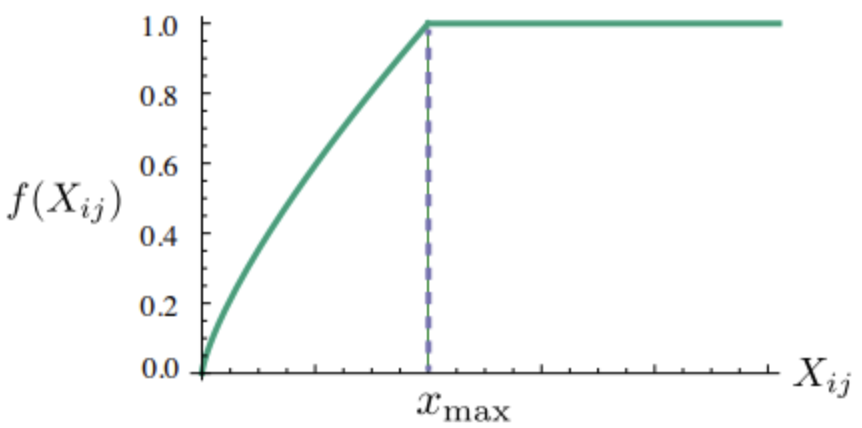
여기서, f(x)는 특정 단어가 지나치게 빈도수가 높아 생기는 오류를 방지하기 위해 일정 빈도수 이상일 경우, 똑같은 가중치를 부여할 수 있도록 설정하였다.
Evaluation
1. Intrinsic
특정 subtask에 적용하여 평가한다.
계산 속도가 빠르며 해당 시스템을 이해하기 좋다.
현실에서 해당 시스템이 유용한지 알 수 없다.
2. Extrinsic
real task에 적용하여 평가한다.
계산 속도가 느리며 해당 시스템이 문제인지, 다른 시스템이 문제인지 아니면 둘의 교호작용이 문제인지 알 수 없다.
GloVe는 위의 두 가지 평가 방법에 대해 모두 좋은 성능에 달성하였다.
Word sense ambiguity
많은 단어들은 여러 개의 의미를 보유한다.
예를 들어, pike는 다음과 같은 의미들을 가진다.

1. Improving Word Representations Via Global Context And Multiple Word Prototypes (Huang et al. 2012)

특정 단어의 윈도우들을 클러스터링한 후, 클러시터링한 단어들을 중심으로 다시 임베딩한다. ex) bank1, bank2, bank3
2. Linear Algebraic Structure of Word Senses, with Applications to Polysemy (Aroro, ..., Ma, ..., TACL 2018)

각 의미에 가중치를 부여하고 선형결합을 통해 새로운 단어 벡터를 생성한다.
'Deep Learning Study > cs224n' 카테고리의 다른 글
| Stanford CS224N - Lecture 4. Syntactic Structure and Dependency Parsing (0) | 2024.04.04 |
|---|---|
| Stanford CS224N - Lecture 3. Backprop and Neural Networks (0) | 2024.03.04 |
| Stanford CS224N - Lecture 1. Intro & Word Vectors (0) | 2023.10.23 |


