본 글은 https://arxiv.org/abs/1311.2524 내용을 기반으로 합니다.
혹시 잘못된 부분이나 수정할 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
본 논문은 mAP 30% 이상 높여 53.3%를 달성한 object detection 알고리즘을 제시한다.
알고리즘의 핵심은 region proposal에 CNN을 적용하고 pre-training과 fine-tuning을 적용해 성능을 높였다.
이를, R-CNN(Regions with CNN features)라고 부른다.
1. Introduction
오랜 기간 동안 시각 인지 분야에서는 SIFT와 HOG 알고리즘을 사용하였으나 이는 object detection 성능을 많이 높이지 못하였다. 이후 back-propagation이 가능한 SGD(Stochastic Gradient Descent)기반의 CNN(Convolutional Neural Networks)이 등장하기 시작하였고 PASCAL VOC object detection에서 높은 성능을 달성하였다.
1990년대 CNN을 많이 사용하다 SVM(Support Vector Machine)의 발전으로 CNN의 인기가 떨어졌으나 ImageNet에서 relu와 dropout을 사용하면서 다시 인기를 얻었다.
본 논문은 CNN이 object detection에서 좋은 성능을 가지는 것을 보여줄 것이다.
이러한 결과를 달성하기 위해 두 가지 문제에 초점을 두어야 한다.
1. Localizing objects with a deep network
2. Training a high-capacity model with only a small quantity of annotated detection data

첫 번째 문제는 CNN으로 객체를 localization하는 것이다.
이를 해결하기 위해 본 논문은 object detection과 semantic segmentation에서 성공적이였던 recognition using regions을 사용한다.
입력 이미지에 대한 region proposal을 2000개 정도 생성하여 fixed-length feature vector를 추출한 후, SVM을 사용하여 각 region을 분류한다.
CNN을 사용하여 region proposal을 하였기 때문에 R-CNN이라고 명칭하였다.
두 번째 문제는 주석이 달린 데이터가 부족한 상태에서 모델을 학습하는 것이다.
이를 해결하기 위해 대용량 ILSVRC dataset으로 사전학습을 하여 소량의 PASCAL dataset으로 fine-tuning 방식을 제시한다.
ILSVRC의 보조데이터를 활용해 사전학습을 하기 때문에 주석이 달린 PASCAL dataset이 적어도 좋은 성능을 달성했다.
2. Object detection with R-CNN
R-CNN은 세 가지 모듈로 구성된다.
첫 번째 모듈은 각 클래스별로 region proposal를 생성한다.
두 번째 모듈은 각 region별로 고정된 길이의 특징 벡터를 추출하는 CNN이다.
세 번째 모듈은 선형 SVM이다.
다음은 각 모듈 구조와 test 단계 시간, 훈련 방법, PASCAL VOC 2010-12와 ILSVRC2013에 대한 성능 결과를 보여준다.
2.1 Module design
Region proposals.
R-CNN은 선택적 탐색(selective search)을 사용한다.
선택적 탐색은 다음 그림과 같이 수 많은 region 영역을 생성한 후, greedy 알고리즘을 이용하여 각 region을 기준으로 주변의 유사한 영역을 결합한다. 결합된 region들을 최종 region proposal 하는 방법이다.
Feature Extraction.
Region proposals를 통해 227*227 이미지로 변환 후 CNN을 사용하여 4096차원의 특징 벡터를 추출한다. 그 후, AlexNet의 모델 구조와 같이 5개의 convolutional layer와 2개의 fully connected layer를 통과한다.
2.2 Test-time detection
Test 단계에서 각 test 이미지별로 선택적 탐색을 적용해 2,000개의 후보 영역을 추출한다. 후보 영역을 warping한 후, 특징 추출을 위해 CNN을 통과시킨다. 이렇게 구한 특징들을 SVM으로 각 클래스별 점수를 계산한다. 그리고 비최댓값 억제(Non-Maximum Suppression, NMS)을 수행하여 IoU가 특정 임계값을 넘는 region들을 제거한다.
* 비최대값 억제(Non-Maximum Suppression, NMS)란 경계 박스 가운데 가장 확실한 경계 박스만 남기고 나머지 경계 박스를 제거하는 기법이다.
2.3 Training
Supervised pre-training
ILSVRC2012 dataset(Image Classification dataset)으로 CNN을 pre-training하였다. ILSVRC2012 dataset은 bounding-box labels이 없어 image 레이블만 사용해 훈련하였다.
Domain-specific fine-tuning
Pre-training한 CNN 모델을 새로운 detection task와 새로운 domain에 적용하기 위해 SGD를 적용하고 warping한 region proposals를 이용해 fine-tuning하였다. ILSVRC2012 dataset 클래스는 총 1,000개로 CNN 모델의 출력층은 1,000개이다. Object detection에 맞게 구조를 바꾸기 위해 출력층을 (N+1)개로 설정하였다. N은 객체 개수이고, 1은 배경이다. 그리고 IoU는 0.5 기준으로 하고 SGD learning rate는 0.001, batch size는 128로 설정하였다.
Object category classifiers
Fine-tuning을 할 때는 IoU threshold를 0.5로 설정하였으나, object category classifiers를 훈련할 때는 0.3으로 설정하였다. IoU threshold를 {0, 0.1, ..., 0.5}으로 설정하고 실험한 결과, 0.3일 때 가장 성능이 좋았다. 이렇게 각 클래스별 bounding box를 추출하여 linear SVM을 이용해 클래스를 분류한다. 훈련 데이터가 너무 커서 메모리 용량이 꽉 차는 문제로 hard negative mining 기법을 적용한다. Hard negative mining이란 positive 샘플과 negative 샘플을 잘 학습해 모델이 강건해지고 false positive 오류를 줄이기 위한 기법이다. 이미지 안에 배경 영역은 넓기 때문에 negative 샘플이 될 경계 박스가 많다. positive 샘플보다 negative 샘플이 지나치게 많으면 클래스 불균형 때문에 모델이 false positive 오류를 범하게 된다. 이러한 문제를 해결하기 위해 신뢰도 점수가 가장 높은 경계 박스 순으로 negative 샘플을 선정한다는 의미이다.
2.4 Results on PASCAL VOC 2010-12
다음 표는 PASCAL VOC dataset 테스트 평가표이다. Bounding box regression을 사용하지 않은 R-CNN은 50.2%, Bounding box regression을 사용한 R-CNN은 53.7%의 mAP를 달성하였다.
2.5 Results on ILSVRC2013 detection
다음 표는 ILSVRC2013 dataset 테스트 평가표이다. PASCAL VOC에서 사용한 파라미터를 그대로 사용하였으며 R-CNN BB가 가장 높은 성능을 보였다.
3. Visualization, ablation, and modes of error
3.1 Visualizing learned features
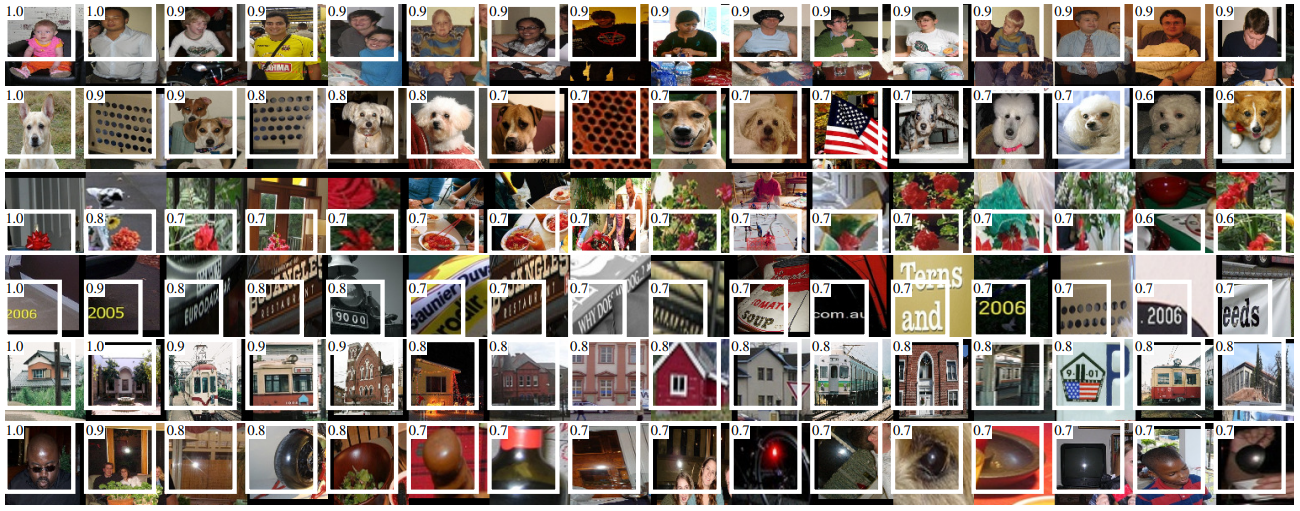
CNN의 첫 번째 계층 필터는 경계선과 보색을 찾아준다. 그 다음 필터 부터는 R-CNN 안에서의 역할을 이해하기 어렵다. Convolution neural network 안의 레이어가 어떤 것을 학습했는지 확인하기 위한 방법으로 특정필터를 선택해 이것을 독립적인 object detector로 사용한다. Object detector는 필터에서 약 10만개의 region proposals의 활성화 점수를 계산하고 이를 크기 순으로 나열하여 비 최대값억제(NMS)를 수행한다. 이 결과로 해당 필터에서 점수가 높은 region이 어떤 것을 학습했는지 시각적으로 확인할 수 있다.
다음 그림은 다섯 번째 계층의 후보 영역과 점수를 보여준다. 각 행마다 객체 탐지하는 것이 다르며 잘못 구분한 경우도 보인다.
3.2 Ablation studies
Performance layer-by-layer, without fine-tuning.
Detection 성능에 있어 중요한 레이어들을 이해하기 위해 CNN의 마지막 세 개의 레이어 pool5, fc6, fc7에 대한 VOC 2007 데이터 세트에 대한 결과를 분석한다.
먼저, PASCAL에 대해 fine-tuning 없이 진행한다. 즉, 모든 CNN 파라미터는 LSVRC 2012로만 사전학습을 한다.

R-CNN pool5는 다섯 번째 최대 풀링 계층까지만 있는 구조,
R-CNN fc6은 첫 번째 fully connected layer까지만 있는 구조,
R-CNN fc7은 두 번째 fully connected layer까지 모두 있는 구조이다.
fine-tuning 없는 R-CNN 모델에서는 R-CNN fc6가 mAP 46.2%로 가장 높다.
Performance layer-by-layer, with fine-tuning.
위 표에서 4~6행은 fine-tuning한 R-CNN 모델이다.
Fine-tuning하지 않은 모델과 다르게 4~6행 모델 중에서 R-CNN fc7이 mAP 54.2%로 가장 높다.
Bounding-box regression(BB)를 포함한 R-CNN Fine-tuning한 fc7 모델이 가장 좋은 성능을 가진다.
Comparison to recent feature learning methods.
논문 작성 기준 시점 최신 모델인 DPM ST, DPM HSC와 비교해 보아도 R-CNN 모델은 PASCAL VOC detection에서 뛰어난 성능을 보여준다.
R-CNN이 이미지에서 object detection을 학습하는데 더 효과적인 접근 방식임을 보여준다.
3.3 Network architectures
본 논문에서 대부분의 네트워크는 T-Net 모델을 사용한다.
T-Net은 토론토 대학교에서 발표한 AlexNet을 말한다.
O-Net은 옥스포드 대학교에서 발표한 VGG16을 말한다.

하지만, VOC 2007 테스트 결과를 살펴보면, bounding-box regression을 사용한 VGG 모델을 사용할 때 mAP가 58.5%에서 66%로 증가하였다. 하지만 T-Net을 사용한 R-CNN 모델보다 컴퓨팅 시간이 7배 정도 증가하여 단점이 존재하기도 한다.
3.4 Detection error analysis
Fine-tuning이 method 오류를 어떻게 변화시키는지 이해하고 오류 유형과 DPM이 어떻게 비교되는지 확인하기 위해 Hoiem et al의 탐지분석 도구를 적용한다. 하지만 이것은 논문의 범위를 벗어나는 내용이기에 참조 문서를 확인하는 것을 권한다고 표기되어있다.
3.5 Bounding-box regression
Bounding-box regression은 localization에 대한 오류를 줄여준다.
선형 회귀 모델을 통해 bounding-box의 loss를 학습하고 위치를 예측하여 mAP를 3~4점 향상 시켜주는 결과를 보여준다.
3.6 Qualitative results
아래 그림은 R-CNN으로 탐지한 결과이다.

전반적으로 정확하며 생선을 개로, 기타를 탁자로 잘못 식별한 영역도 있다.
4. The ILSVRC2013 detection dataset
4.1 Dataset overview
ILSVRC2013 데이터셋은 train data 395,918개. valid data 20,121개. test data 40,152개로 이루어져있다. valid data와 test data는 이미지 분포가 동일하며 200개의 class와 bounding box로 주석 처리 되어있고 객체 수, 혼잡도, pose 다양성 등에서 PASCAL VOC image들과 유사하다. 반대로, train data는 ILSVRC2013 classification image distribution에서 추출되어 다양한 복잡성을 가지고 있으며 주석 처리가 되어 있지 않다.
Hard hegative mining은 완벽히 annotation되어 있어야 하기 때문에 적용하기 어렵다. 이러한 문제를 해결하기 위해, valid data 일부를 train data로 활용한다. valida data를 클래스가 균일하게 "val1"과 "val2"로 나누어 val1을 train data 일부를 이용해 훈련하고 val2를 이용해 검증한다.
4.2 Region proposals
PASCAL detection에서 사용한 것과 같이 region proposal approach 방식을 사용한다.
val1, val2, test set에 대해 선택적 탐색 기법으로 region proposal을 한다.
ILSVRC image 크기는 매우 다양하기 때문에, 각 이미지를 고정된 픽셀(500 pixels)로 조정해준다.
valid set에서 평균적으로 image 당 2403개의 영역을 생성하며 ground-truth bounding box에 대한 91.6%의 재현율을 보였다.
4.3 Training data