본 글은 https://arxiv.org/abs/2003.10555 내용을 기반으로 합니다.
혹시 잘못된 부분이나 수정할 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
Abstract
BERT와 같은 Masked language modeling(MLM) pre-training 방법은 일부 토큰을 [MASK]로 대체하여 학습한다. 이는 downstream NLP task에서 좋은 결과를 얻을 수 있지만 많은 양의 계산을 필요로한다. 본 논문은 input을 마스킹하지 않고 generator network를 이용하여 토큰을 적절한 대안으로 대체하여 해당 토큰이 생성된 토큰인지 기존 토큰인지 예측하는 discriminative model을 학습하는 방법을 제안한다. 모든 input 토큰을 판별하기 때문에 마스킹된 토큰만 예측하는 MLM보다 더 효율적이고 동일한 모델 크기, 데이터 및 계산량을 가진 BERT보다 더 좋은 성능을 보여준다. 본 논문에서 제시한 방법을 통해 RoBERTa와 XLNet보다 1/4 미만의 계산량을 사용하면서 비슷한 성능을 보여주고 동일한 계산량을 사용할 때 더 좋은 성능을 보여준다.
1. Introduction
현재 state-of-the-art representation learning 방법은 denoising autoencoder 학습이라고 볼 수 있다. Input 시퀀스의 약 15%를 마스킹하고 이를 복원하는 MLM 방법은 bidirectional representation 학습으로 효과적이지만 example당 토큰의 15%만 학습을 할 수 있기 때문에 상당한 계산량이 발생한다.
이러한 대안으로 본 논문은 replaced token detection을 제안한다. 이는 실제 입력의 일부 토큰을 가짜 토큰으로 변경하고 각 토큰이 실제 입력에 있는 기존 토큰인지 생성된 토큰인지 예측하는 판별자로 pre-training한다. 즉, 모든 입력 토큰으로부터 학습하기 때문에 계산 효율성이 높다.
이러한 접근법을 ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)라고 부른다.
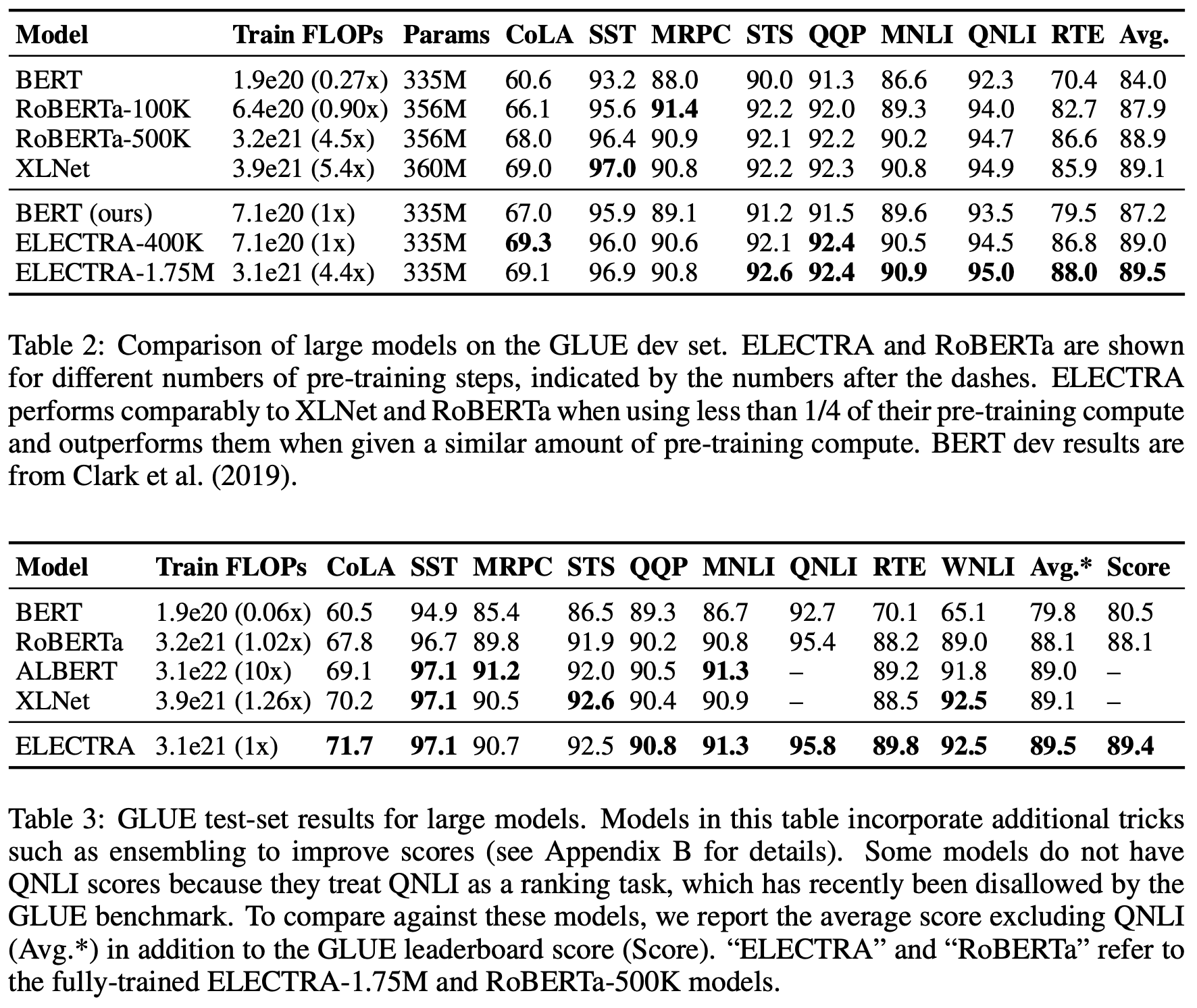
Figure 1은 ELECTRA의 성능과 효율성을 보여준다. ELECTRA-Large는 RoBERTa와 XLNet에 비해 1/4의 계산량을 사용함에도 불구하고 비슷한 성능을 보인다. ELECTRA-Larage를 추가로 학습하면 GLUE에서 ALBERT보다 성능이 우수하며 SQuAD 2.0에서 SOTA 성능을 달성한다. 따라서, ELECTRA는 기존 representation learning 기법들보다 더 효율적이다.

2. Method
Figure 2는 replaced token detection의 기본 구조를 보여주며 Generator G와 Discriminator D를 학습한다. 각 네트워크는 transformer encoder로 구성된다.
Generator는 입력 x=[x1,x2,...,xn]에 대해 마스킹할 위치의 집합 m=[m1,m2,...,mk]를 결정한다. 결정한 위치에 있는 입력 토큰을 [MASK]로 변경하며 이 과정을 xmasked=REPLACE(x, m, [MASK])로 표현한다. 마스킹된 입력 xmasked에 대해 generator는 softmax layer로 특정 토큰 xt를 원래 토큰이 무엇인지 확률을 출력하며 식은 다음과 같다. 여기서 e는 토큰 임베딩이다.
주어진 position t에 대해 Discriminator는 token xt가 진짜인지 가짜인지 예측하며 식은 다음과 같다.
GAN의 training objective와 유사하지만 몇가지 차이점이 있다.
1. Generator가 원래 토큰과 동일한 토큰을 생성해도 GAN은 negative sample로 고려하지만 ELECTRA는 positive sample로 고려한다.
2. Generator는 Discriminator를 속이기 위해 적대적 학습을 하지 않고 maximum likelihood를 이용해 학습한다.
최종적으로 ELECTRA는 대용량 corpus에 대해서 generator loss와 discriminator loss의 합을 최소화하도록 한다.
Pre-training 후에는 generator를 사용하지 않고 downstream task에 대해 discriminator를 fine-tuning한다.
3. Experiments
3.1 Experimental Setup
ELECTRA는 GLUE benchmark와 SQuAD dataset을 이용하여 평가한다. 대부분의 실험은 BERT와 동일하게 Wikipedia와 BooksCorpus를 이용해 pre-training하였으며 Large 모델은 ClueWeb과 CommonCrawl, Gigaword를 사용하여 pre-training 하였다. 모델의 구조와 대부분의 하이퍼파라미터도 BERT와 동일하게 하였다.
3.2 Model Extensions
ELECTRA의 성능 향상을 위한 몇 가지 기법들을 제안한다. 실험은 BERT base와 동일한 모델 크기와 training data를 사용한다.
Weight Sharing
Generator와 Discriminator의 가중치 공유를 세 가지 경우(공유하지 않음, 임베딩만 공유, 모든 가중치 공유)로 실험한 결과 임베딩만 공유한 것과 모든 가중치를 공유한 것에 대한 성능 결과가 비슷하게 나왔다. 크기가 동일하면 가중치 공유가 가능하지만 small generator를 사용하는 것이 효율적이다.
Smaller Generators
Generator와 Discriminator의 크기를 동일하게 하면 ELECTRA 학습은 MLM 모델에 비해 거의 두 배의 계산량이 필요하다. 이러한 문제를 완화하기 위해 Figure 3 좌측 그림과 같이 Generator의 크기를 줄여보는 실험을 진행한다. Discriminator의 크기 대비 1/4-1/2 크기의 Generator를 사용할 때 가장 좋은 성능을 가지는 것을 알 수 있다.
이는 Generator가 너무 강력하면 Discriminator의 task가 너무 어려워지고 Discriminator의 파라미터들이 Generator를 모델링하는데 사용할 수 있다고 해석한다.
Training Algorithms
ELECTRA를 효과적으로 학습시킬 수 있는 알고리즘을 살펴본다. 앞서 언급한 Generator와 Discriminator를 같이 학습하는 방식 이외에 두 가지 방식의 실험을 진행한다.
1) Two-Stage 방식 : Generator만 n번 학습한 후 Discriminator를 Generator의 학습된 가중치로 초기화하여 Discriminator만 n번 학습한다.
2) Adversarial 방식 : GAN과 같이 Generator를 적대적 학습을 하는 방식
Figure 3 우측 그림과 같이 Generator와 Discriminator를 같이 학습시키는 방식이 가장 좋은 성능을 보인다.
3.3 Small Models
Single GPU에서 빠르게 학습할 수 있는 small model을 개발한다. BERT base 하이퍼파라미터를 다음과 같이 변경한다.
- Sequence length : 512 -> 128
- Batch size : 256 -> 128
- Hidden size : 768 -> 256
- Token embedding : 768 -> 128
Table 1에서 볼 수 있듯이 ELECTRA-small은 같은 계산량인 BERT-small보다 성능이 좋으며 계산량이 많이 필요한 GPT보다도 좋은 성능을 보였다.
3.4 Large Models
본 논문은 large model에 대한 실험도 진행하며 ELECTRA-large도 이전 실험과 같이 같은 크기의 BERT-large로 실험한다. ELECTRA-400K는 XLNet과 RoBERTa-500K 학습하는데 필요한 계산량의 1/4(FLOPs)로도 비슷한 성능을 보인다.
3.5 Efficiency Analysis
Input의 일부 토큰을 마스킹하고 이러한 작은 부분집합에 대해서만 학습 목적함수를 적용하는 것은 효율성이 떨어진다고 주장하였다. 본 논문은 ELECTRA의 성능 향상을 더 잘 이해하기 위해 BERT와 ELECTRA를 이용하여 다음과 같은 실험을 진행한다.
- ELECTRA 15% : Discriminator loss를 입력 토큰의 15%만 만들도록 한다.
- Replace MLM : Discriminator를 MLM 학습을 하는데 [MASK]로 치환하지 않고 Generator가 만든 토큰으로 치환한다.
- All-Tokens MLM : Replace MLM처럼 하지만 15% 토큰만 치환하는게 아니고 모든 토큰을 Generator가 생성한 토큰으로 치환한다.
Table 4는 위와 같은 실험에 대한 결과를 보여준다. ELECTRA는 ELECTRA 15%와 Replace MLM보다 훨씬 좋은 성능을 보이고 All-Tokens MLM이 비슷한 성능을 보인다.

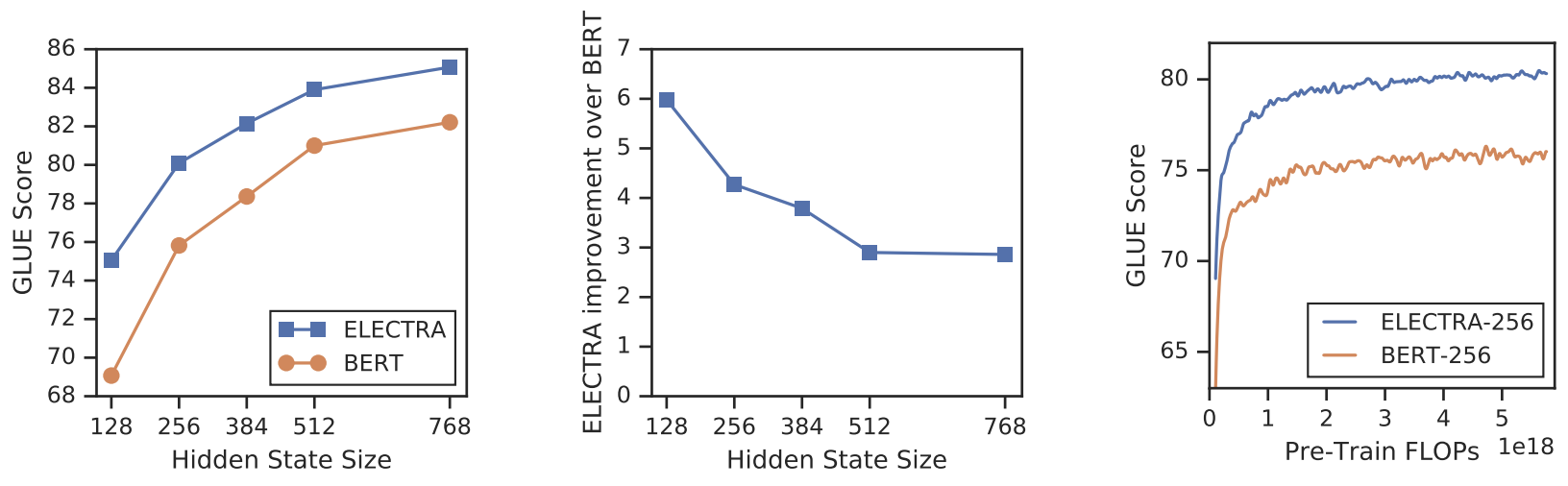
Figure 4의 좌측 그림을 보면 모델이 작아질수록 ELECTRA의 이점이 큰 것을 알 수 있다. Figure 4의 우측 그림을 보면 ELECTRA는 완전히 훈련될 때 BERT보다 더 높은 downstream 정확도를 달성한다는 것을 보여준다.
4. Conclusion
본 논문은 language representation learning을 위한 새로운 self-supervised task인 replaced token detection을 제안하였다. 핵심 아이디어는 small generator network에 의해 생성된 고품질의 negative sample을 사용하여 text encoder를 학습시키는 것이다. MLM과 비교하면 본 논문에서 제안한 방법은 효율적인 계산량과 downstream task에 대한 더 좋은 성능을 보였다.



